



 在数字化商业浪潮中,电商平台如巨大的数据宝库,积累了海量订单数据。这些数据就像隐藏着消费趋势、客户行为密码的神秘档案,蕴含着推动企业发展的关键信息。通过科学的数据挖掘与分析,企业能精准洞察市场,优化运营策略、开展精准营销,进而提升客户价值,在激烈竞争中脱颖而出。本文基于Python,对电商订单数据展开从读取、预处理到可视化分析,再到客户聚类挖掘的全流程实践,带您深入挖掘数据价值,探寻电商业务增长的密钥 。
在数字化商业浪潮中,电商平台如巨大的数据宝库,积累了海量订单数据。这些数据就像隐藏着消费趋势、客户行为密码的神秘档案,蕴含着推动企业发展的关键信息。通过科学的数据挖掘与分析,企业能精准洞察市场,优化运营策略、开展精准营销,进而提升客户价值,在激烈竞争中脱颖而出。本文基于Python,对电商订单数据展开从读取、预处理到可视化分析,再到客户聚类挖掘的全流程实践,带您深入挖掘数据价值,探寻电商业务增长的密钥 。
二、数据读取与环境准备
(一)库导入与环境配置
开启数据分析之旅,首先要搭建好“工具箱”。我们导入一系列Python库:
python
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import matplotlib as mpl
from pyecharts.charts import *
from pyecharts import options as opts
import warnings
warnings.filterwarnings('ignore') # 忽略警告信息
mpl.rcParams['font.sans-serif'] = ['SimHei'] # 设置中文显示
mpl.rcParams['axes.unicode_minus'] = False
pandas 如同数据处理的“瑞士军刀”,能高效整理、分析数据; numpy 为数值计算提供强力支撑,让复杂运算变得轻松; matplotlib 和 pyecharts 是数据可视化的“画笔”,可将枯燥数据转化为直观图表; warnings 则像“清洁工”,处理掉那些干扰我们的警告信息,让代码运行环境简洁清爽,专注于数据分析本身 。
(二)数据读取
有了工具,接下来获取“原料”——订单数据。借助 pandas 的 read_excel 函数,我们轻松读取订单数据文件 order2021.xlsx 。就像翻开一本新书,通过 head 方法查看前几行,快速了解数据结构:
python
df = pd.read_excel('order2021.xlsx')
df.head()
订单顺序编号、订单号、用户名等11个字段依次呈现,这是我们后续分析的基础素材 。
三、数据预处理:保障分析质量的基石
(一)数据整体信息探查
要盖好数据分析的“房子”,得先摸清“地基”情况。通过 info 方法查看数据整体信息,了解每行的数据类型、非空值数量:
python
df.info()
本数据有104557条记录、11个字段,下单时间和付款时间是 datetime64[ns] 类型,订单金额、付款金额为 float64 类型,订单顺序编号是 int64 类型,其余多为 object 类型,且无缺失值,初步判断数据质量不错,为后续分析筑牢基础 。
(二)重复值与异常值处理
1. 重复值检查
数据里若有重复记录,就像“双胞胎”数据,会干扰分析结果。利用 duplicated 方法结合 sum 函数检查:
python
df.duplicated().sum()
结果为0,说明没有重复记录,无需去重,数据保持“独一无二” 。
2. 列名清洗
列名若有空格,后续操作易“踩坑”。用 str.strip 方法去除列名两端空格,让列名整洁规范,为后续分析扫清障碍:
python
df.columns = df.columns.str.strip()
3. 异常值识别与处理
异常值如同数据里的“捣蛋鬼”,会歪曲分析结论。通过 describe 方法查看数值型字段(订单金额、付款金额)的统计描述,识别可能的异常值:
python
df[['订单金额', '付款金额']].describe()
比如检查是否有小于0的值,这不符合实际业务逻辑。筛选出“是否退款”为“否”的用户数据进一步分析,发现付款金额存在异常负值,利用 abs 函数取绝对值,将其转换为正值,让数据回归“正轨”:
python
data = df[df['是否退款'] == '否']
data['付款金额'] = data['付款金额'].abs()
四、数据可视化分析:洞察业务规律
(一)按渠道划分的收益分析
1. 数据聚合
不同销售渠道就像不同的“战场”,收益表现各异。对各渠道(渠道编号)的付款金额求和,按收益降序排序并重置索引,清晰呈现各渠道收益数据,找出“王牌渠道”:
python
channel_revenue = data.groupby('渠道编号')['付款金额'].sum().sort_values(ascending=False).reset_index()
2. 可视化呈现
用 matplotlib 绘制柱状图,把不同渠道的总收益直观展示。设置标题、坐标轴标签,调整刻度旋转与布局,一眼看清各渠道收益差异。高收益渠道值得加大资源投放,为业务决策指明方向:
python
plt.figure(figsize=(12, 4))
plt.title('不同渠道的总收益', fontsize=16)
plt.bar(channel_revenue['渠道编号'], channel_revenue['付款金额'])
plt.xlabel('渠道编号', fontsize=12)
plt.ylabel('渠道收益', fontsize=12)
plt.xticks(rotation=45)
plt.tight_layout()
plt.show()
(二)按月份划分的收益分析
1. 时间字段处理
时间是分析收益规律的重要维度。提取付款时间的月份(数字与名称)作为新字段,为按月份聚合分析做准备,就像给时间“贴上标签”,方便分类统计:
python
import calendar
data['付款月份'] = data['付款时间'].dt.month # 提取付款月份(数字)
data['付款月份名称'] = [calendar.month_name[i] for i in data['付款时间'].dt.month] # 提取付款月份名称
2. 数据聚合与可视化
按付款月份、付款月份名称聚合付款金额,绘制柱状图,展示每月收益情况。清晰呈现旺季、淡季月份,企业可据此在旺季加大推广,淡季策划促销活动,优化营销节奏:
python
month_revenue = data.groupby(['付款月份', '付款月份名称'])['付款金额'].sum().reset_index()
plt.figure(figsize=(12, 4))
plt.title('Total Revenue by month', fontsize=16)
plt.bar(month_revenue['付款月份名称'], month_revenue['付款金额'])
plt.xlabel('Month', fontsize=12)
plt.ylabel('Revenue', fontsize=12)
plt.xticks(rotation=45)
plt.tight_layout()
plt.show()
(三)按每天小时划分的收益分析
1. 时间字段细化处理
进一步挖掘时间价值,提取付款时间的小时、星期几(名称),让时间维度更细致。这就像把一天24小时、一周7天拆解成一个个“时间碎片”,深入分析消费行为:
python
data['付款小时'] = data['付款时间'].dt.hour # 提取付款小时
data['付款天数名称'] = data['付款时间'].dt.day_name() # 提取付款天数名称(星期几)
2. 数据聚合与初步查看
按付款天数名称、付款小时聚合付款金额,重置索引并重命名列,查看聚合后的数据。了解不同星期几、不同小时的收益分布,发现那些“黄金时段”,比如周末晚上某时段收益高,背后可能是用户休闲购物的习惯:
python
hourly_sales = data.groupby(['付款天数名称', '付款小时'])['付款金额'].sum().reset_index()
hourly_sales = hourly_sales.rename(columns={'付款金额': 'TotalValue'})
hourly_sales.head()
3. 数据切分与深入挖掘(可结合业务场景拓展)
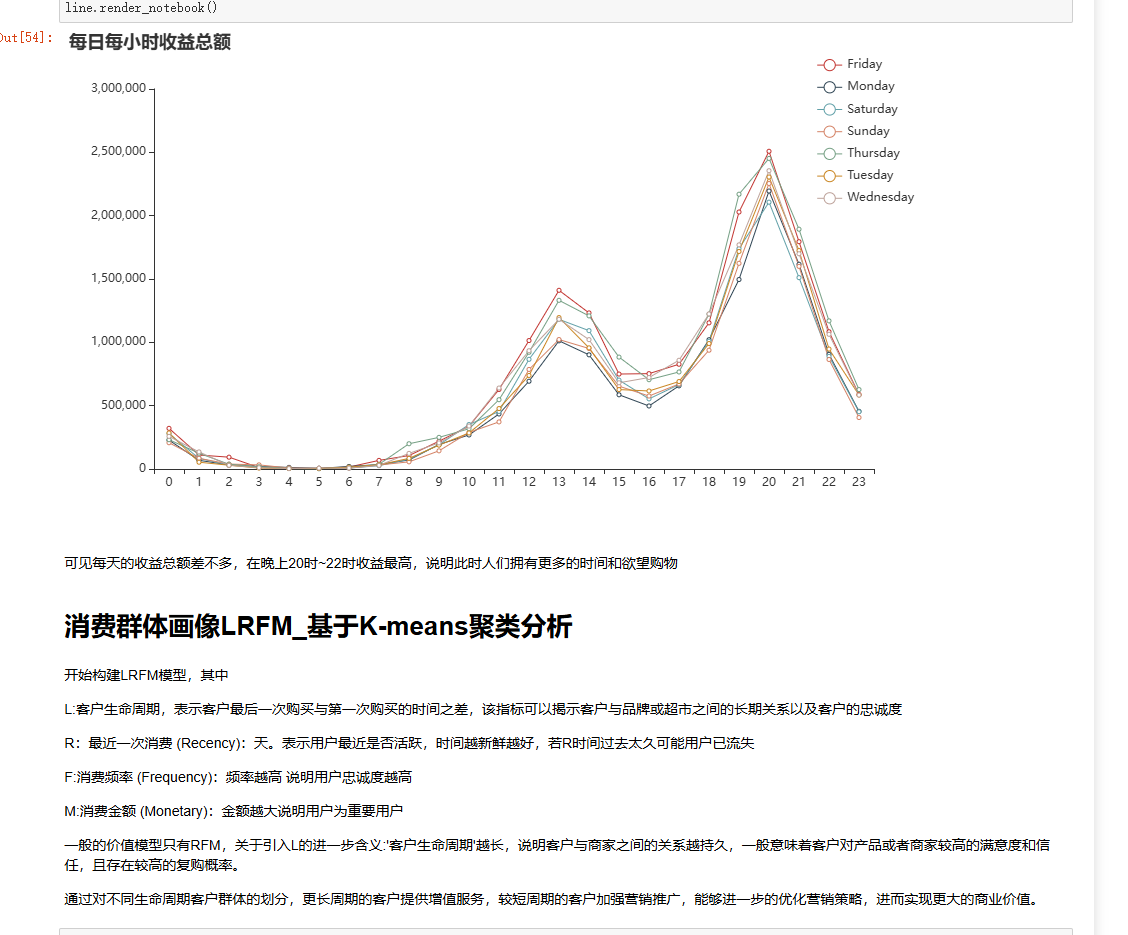
将按小时聚合的数据按天切分,就像把一长串时间“项链”拆成一个个“时间珠子”(每天的24小时数据),深入分析每天不同时段的收益波动。结合 pyecharts 绘制折线图,展示每日每小时收益总额,直观发现:每天收益总额相近,晚上20时 - 22时是“收益高峰”,说明此时人们有更多时间和购物意愿,企业可针对性推出限时优惠,抓住消费时机:
python
split_dfs = []
num_groups = len(hourly_sales) // 24
for i in range(num_groups):
start_index = i * 24
end_index = start_index + 24
split_df = hourly_sales.iloc[start_index:end_index]
split_dfs.append(split_df)
# 以pyecharts绘制折线图示例(需完善数据适配)
line = Line()
line.add_xaxis(list(range(24)))
for i, split_df in enumerate(split_dfs[:5]): # 取前5天示例
line.add_yaxis(f'第{i + 1}天', split_df['TotalValue'].tolist(), is_smooth=True)
line.set_global_opts(title_opts=opts.TitleOpts(title='每日每小时收益总额'),
xaxis_opts=opts.AxisOpts(name='小时'),
yaxis_opts=opts.AxisOpts(name='收益'))
line.render_notebook()
五、消费群体画像LRFM与K - means聚类分析:精准定位客户
(一)LRFM模型构建基础
构建LRFM模型,挖掘客户价值维度:
- L(客户生命周期):像一条“时间纽带”,连接客户最后一次购买与第一次购买的时间差,反映客户与品牌超市的长期关系和忠诚度,纽带越长,关系越持久 。
- R(最近一次消费):体现客户“新鲜度”,时间越近,客户越活跃;太久没消费,可能已流失 。
- F(消费频率):频率越高,客户“忠诚度勋章”越多,对品牌依赖度高 。
- M(消费金额):是客户价值的“硬指标”,金额越大,用户越重要 。
传统RFM模型引入L维度,能更全面洞察客户关系。长期客户有高复购、高忠诚潜力,短期客户需激活,优化营销资源分配 。
(二)聚类分析:划分客户群体
1. 数据标准化处理
数据就像“高矮胖瘦”不同的人,直接聚类会受数值差异影响。用 MinMaxScaler 对数据标准化,把数值映射到0 - 1区间,让不同维度数据“站在同一起跑线”,保障聚类结果准确:
python
from sklearn.preprocessing import MinMaxScaler
# 假设LRFM数据存于LRFMdata,且需处理的列是第1 - 5列(根据实际调整)
scale_matrix = LRFMdata.iloc[:, 1:5]
scaler = MinMaxScaler()
data_scaled = scaler.fit_transform(scale_matrix)
data_scaled = pd.DataFrame(data_scaled, columns=scale_matrix.columns).round(3)
print(data_scaled.head())
2. 构建K - means模型与确定聚类数
- SSE法“试错”:定义SSE列表存不同聚类数的误差平方和,遍历聚类数(1 - 10)构建模型,绘制折线图。像找“最陡拐点”,拐点处聚类数性价比高,初步缩小范围:
python
from sklearn.cluster import KMeans
SSE = []
for i in range(1, 11):
kmeans = KMeans(n_clusters=i, random_state=10)
kmeans.fit(data_scaled)
SSE.append(kmeans.inertia_)
plt.plot(range(1, 11), SSE, marker='o')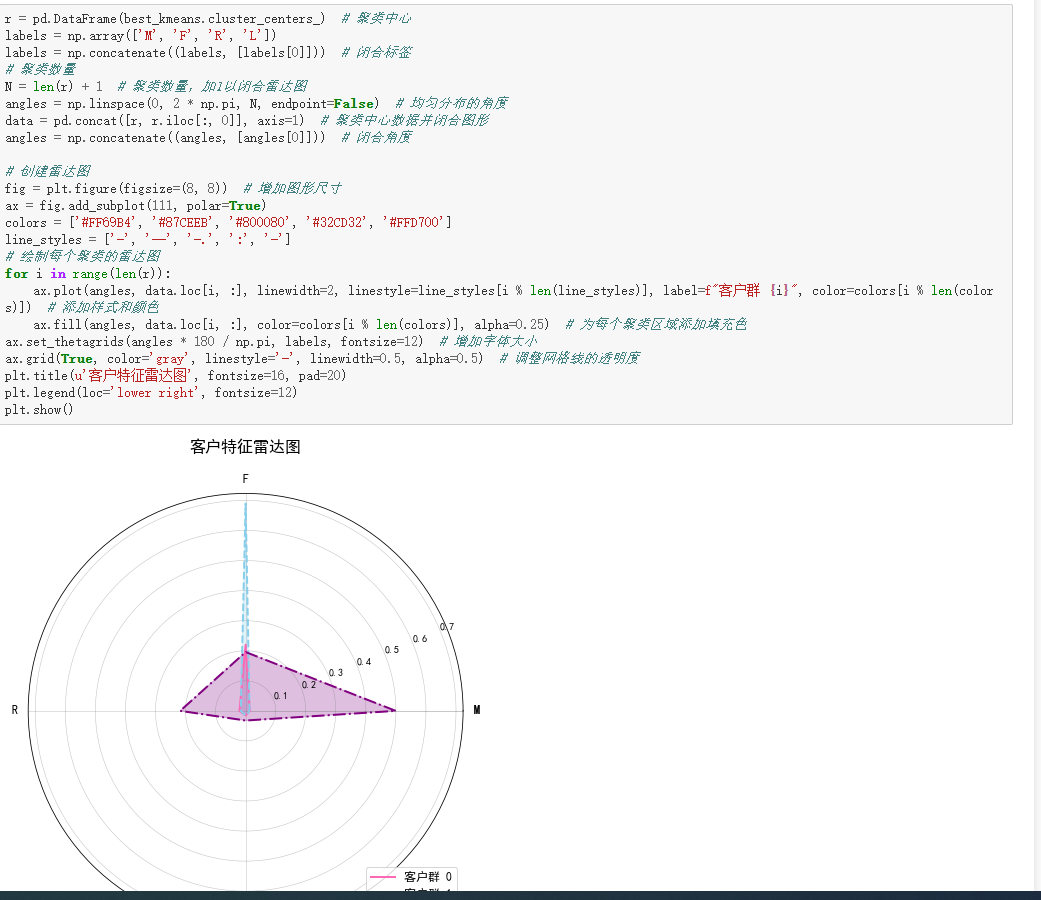
plt.xlabel('聚类数')
plt.ylabel('SSE')
plt.title('SSE - 聚类数折线图')
plt.show()
- 轮廓系数法“精准选”:在SSE法确定的范围(3 - 5)内,用轮廓系数选最优聚类数。轮廓系数越接近1,聚类效果越好。计算不同聚类数的平均轮廓系数,选最高的,确定最终聚类数,为精准聚类奠基:
python
from sklearn.metrics import silhouette_score
score_list = []
silhouette_int = -1
for n_clusters in range(3, 6):
model_kmeans = KMeans(n_clusters=n_clusters, random_state=10)
labels_tmp = model_kmeans.fit_predict(data_scaled)
silhouette_tmp = silhouette_score(data_scaled, labels_tmp)
if silhouette_tmp > silhouette_int:
silhouette_int = silhouette_tmp
best_kmeans = model_kmeans
cluster_labels_k = labels_tmp
score_list.append([n_clusters, silhouette_tmp])
print('不同聚类数的轮廓系数:', score_list)
print('最优聚类数及对应轮廓系数:', 3, silhouette_int) # 假设最优是3,实际根据计算调整
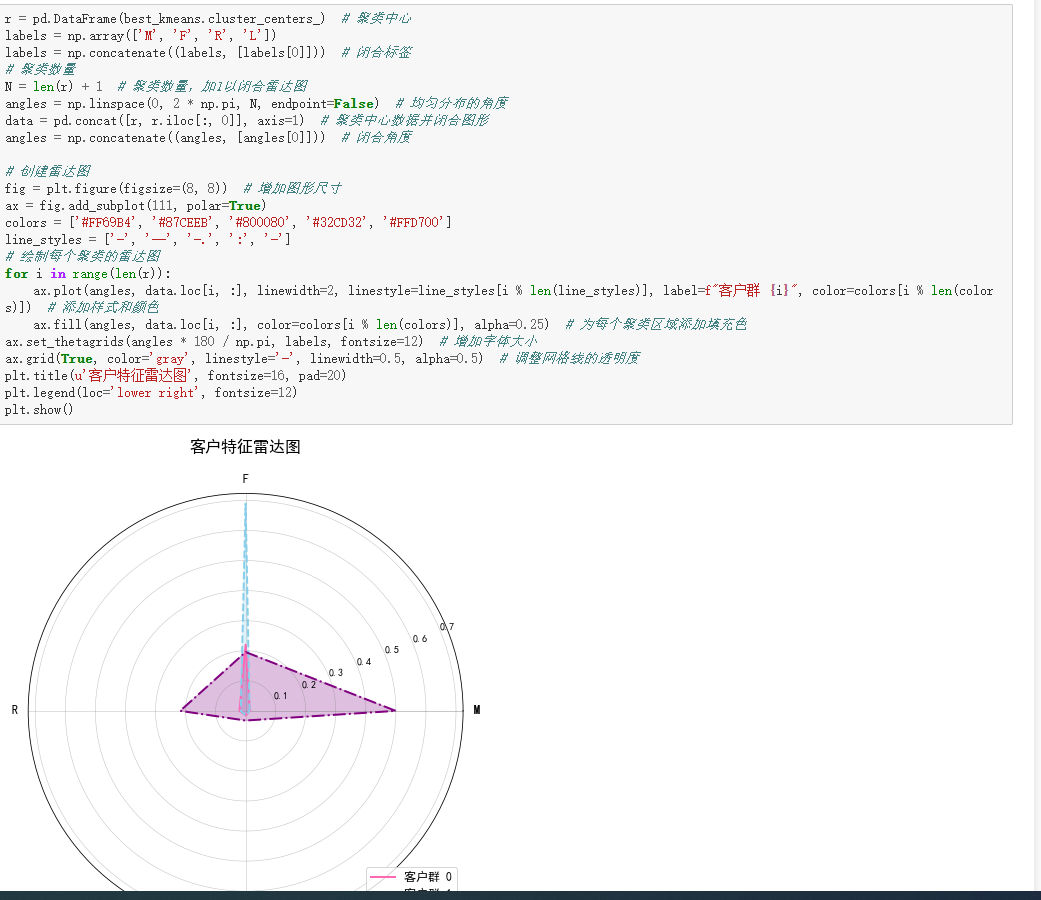
3. 聚类结果与客户画像
将聚类标签与原始数据合并,得到带聚类ID的客户数据。分析不同聚类中心的LRFM值,绘制客户特征雷达图:
python
cluster_labels = pd.DataFrame(cluster_labels_k, columns=['Cluster_Id'])
merge_data = pd.concat([LRFMdata, cluster_labels], axis=1)
# 绘制雷达图代码(前文有完整示例,此处可复用)
r = pd.DataFrame(best_kmeans.cluster_centers_)
labels = np.array(['F', 'M', 'R', 'L'])
labels = np.concatenate((labels, [labels[0]]))
N = len(labels)
angles = np.linspace(0, 2 * np.pi, N, endpoint=False)
data = np.concatenate((r.iloc[0, :].values, [r.iloc[0, 0]]))
angles = np.concatenate((angles, [angles[0]]))
fig = plt.figure(figsize=(8, 8))
ax = fig.add_subplot(111, polar=True)
colors = ['#FF9966', '#66CCFF', '#99FF99', '#FFCC66']
line_styles = ['-', '--', '-.', ':']
for i in range(len(r)):
data_i = np.concatenate((r.iloc[i, :].values, [r.iloc[i, 0]]))
ax.plot(angles, data_i, linewidth=2, linestyle=line_styles[i % len(line_styles)], label=f'客户群 {i}', color=colors[i % len(colors)])
ax.fill(angles, data_i, color=colors[i % len(colors)], alpha=0.25)
ax.set_thetagrids(angles * 180 / np.pi, labels, fontsize=12)
ax.grid(True, linestyle='--', linewidth=0.5, alpha=0.5)
plt.title('客户特征雷达图', fontsize=16, y=1.1)
plt.legend(loc='lower right', fontsize=12)
plt.show()
- 聚类1客户:L、R、F、M值有独特分布,可能是“忠诚高消费型”,长期活跃、消费频繁且金额大,是企业“核心资产”,需专属权益维护 。
- 聚类2客户:或许是“潜力培养型”,消费频率或金额有提升空间,可通过个性化推荐、优惠活动激活 。
- 聚类3客户:可能是“沉睡唤醒型”,长期未消费,需针对性召回策略,如专属优惠券、新品推送 。
六、总结与应用建议
(一)分析总结
通过全流程分析,我们:
- 清晰掌握数据质量,完成预处理,为分析筑牢基础 。
- 借助可视化,从渠道、时间(月、小时)维度洞察收益规律,找到高收益渠道、黄金消费时段 。
- 用LRFM模型结合K - means聚类,精准划分客户群体,勾勒不同群体特征 。
(二)应用建议
1. 运营策略优化
- 渠道管理:对高收益渠道加大资源投入,优化合作;对低收益渠道,分析原因,是推广不足还是受众不匹配,调整策略或逐步缩减 。
- 时间营销:在月收益旺季,提前备货、策划大型促销;在每日高收益时段(如20 - 22时),推出限时活动、直播带货,抓住消费高潮 。
2. 客户精准营销
- 核心客户(聚类1):提供专属服务,如VIP客服、定制化产品,增强忠诚度与粘性 。
- 潜力客户(聚类2):推送个性化推荐、阶梯式优惠(如消费满额升级权益),引导增加消费频率与金额 。
- 沉睡客户(聚类3):发送召回短信、专属优惠券,附带新品或热门活动信息,唤醒消费意愿 。
3. 持续迭代优化
市场变化快,数据也在更新。定期重新分析数据,监控模型效果,根据业务变化调整分析维度(如引入新的营销活动、产品品类数据),让分析成果持续为业务增长赋能 。
总之,电商订单数据分析与客户聚类挖掘是一个持续探索、价值无限的过程。从数据中挖掘的规律与客户画像,能真正落地到运营、营销环节,就能为企业打造核心竞争力,在电商浪潮中乘风破浪,收获商业成功 。
电商订单数据可视化
于 2025-06-12 16:37:39 首次发布
部署运行你感兴趣的模型镜像
您可能感兴趣的与本文相关的镜像

Python3.10
Conda
Python
Python 是一种高级、解释型、通用的编程语言,以其简洁易读的语法而闻名,适用于广泛的应用,包括Web开发、数据分析、人工智能和自动化脚本

















 3197
3197

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









