




动手点关注 干货不迷路 👆
背景
飞书智能问答应用于员工服务场景,致力于减少客服人力消耗的同时,以卡片的形式高效解决用户知识探索性需求。飞书智能问答整合了服务台、wiki 中的问答对,形成问答知识库,在综合搜索、服务台中以一问一答的方式将知识提供给用户。
作为企业级 SaaS 应用,飞书对数据安全和服务稳定性都有极高的要求,这就导致了训练数据存在严重的不足,且极大的依赖于公开数据而无法使用业务数据。在模型迭代过程中,依赖公开数据也导致模型训练数据存在与业务数据分布不一致的情况。通过和多个试点服务台的合作,在得到用户充分授权后,以不接触数据的方式进行训练。即模型可见数据,但人工无法以任何方式获取明文数据。
基于以上原因,我们的离线测试数据均为人工构造。因此在计算 AUC(Area Under Curve)值进行评估,会存在与业务数据分布不一致的情况,只能作为参考验证模型的性能,但不能作为技术指标进行优化迭代。因此转而采用用户点击行为去佐证模型效果的是否出现提升。
在业务落地的过程中,是否展示答案由模型计算的相似度决定。控制展示答案的 Threshold,会同时对点击率和展示率产生重大影响。因此为了避免 Threshold 的值对指标的干扰,飞书问答采用 SSR(Session Success Rate)作为决定性指标去评估模型的效果。其计算方式如下,其中 total_search_number 会记录用户的每一次提问,search_click_number 会记录用户每一次提问后是否点击、及点击了第几个答案。
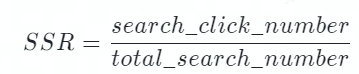
bot_solve_rate(BSR):用来评估机器人拦截的效果,机器人拦截越多的工单则会消耗越少的人力。
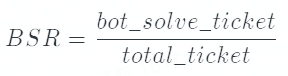
飞书智能问答模型技术
原始的 1.0 版本模型
问答服务最早采用的模型是 SBERT(Sentence Embeddings using Siamese BERT) 模型(1),也是业内普遍使用的模型。其模型结构如下所示:
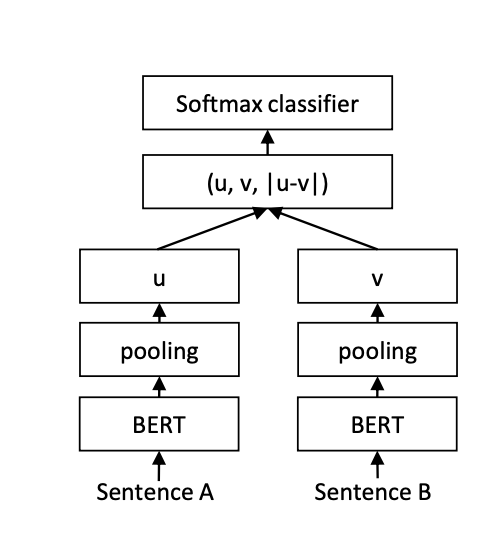
通过将 Query 和 FAQ 的 Question 输入孪生 BERT 中进行训练,并通过二分类对 BERT 的参数进行调整。我们可以离线的将所有的 question 转换为向量存在索引库中。在推理时,将用户的 Query 转换为 Embedding,并在索引库中进行召回。向量的相似度均采用余弦相似度进行计算,下文简称为相似度。
此方案相对于交互式模型,最大的优点在于文本相似度的计算时间与 Faq 的数量脱钩,不会线性增加。
改进的 2.0 版本模型
1.0 版本的模型在表示学习上的表现依然不够好,主要体现在即使是不那么相似的两句话,模型依旧会给出相对较高的分数,导致整体的区分度很低。2.0 版本的模型考虑通过增加两句话的交互,进而获得更多的信息,能够更好的区分两句话是否相似。并且引入了人脸识别的思想,让相似的内容分布更加紧凑,不相似的内容类间距更大,进而提高模型的区分度。其结构如下所示:
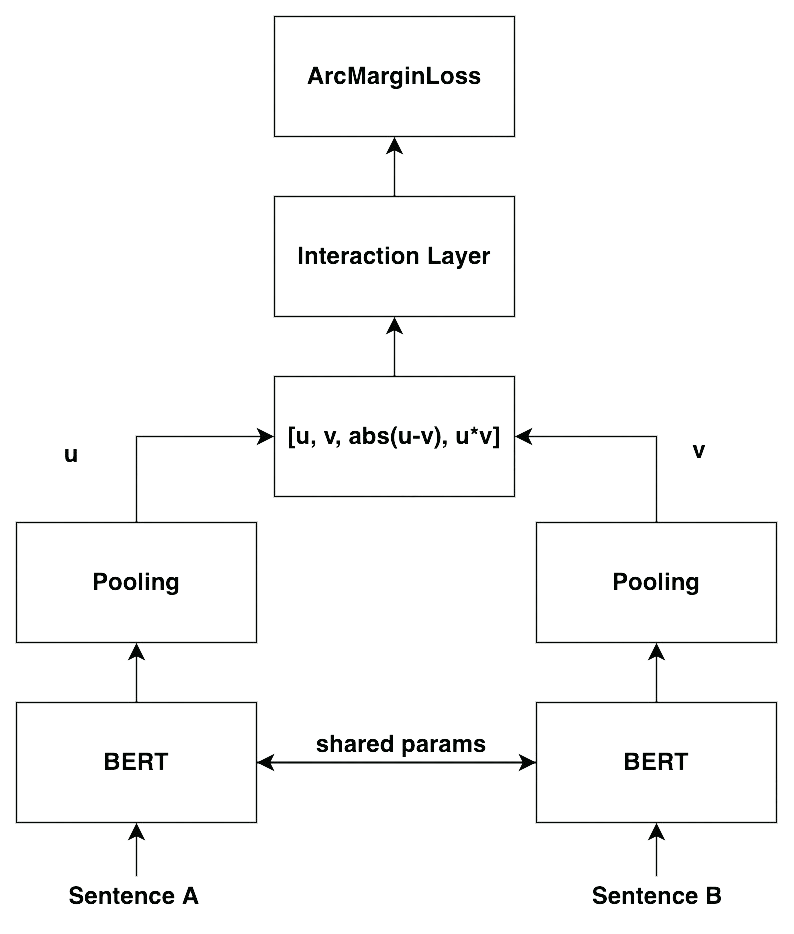
相对于 1.0 版本的模型,2.0 版本更加强调交互的重要性。在原先 concat 的基础上,新增了 u*v 作为特征,并增加了 interaction layer(本质上是 MLP layer)去进一步增强交互。除此之外,引入了 CosineAnnealingLR(2)和 ArcMarinLoss(3)去优化训练过程。除此以外,根据 Bert-Whitening(3)的实验启示,在 pooling 的时候采用了多种 pooling 的方法,去寻找最优的结果。
CosineAnnealingLR
余弦退火学习率通过缓慢下降+突然增大的方法,在模型即将到达局部最优的时候,可以“逃离”局部最优空间,并且进一步检索到更好的局部最优解。下图源自 CosineAnnealingLR 的 paper,其中 default 是
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









