




10月26日,字节跳动技术沙龙 | 大数据架构专场 在上海字节跳动总部圆满结束。我们邀请到字节跳动数据仓库架构负责人郭俊,Kyligence 大数据研发工程师陶加涛,字节跳动存储工程师徐明敏,阿里云高级技术专家白宸和大家进行分享交流。
以下是字节跳动数据仓库架构负责人郭俊的分享主题沉淀,《字节跳动在Spark SQL上的核心优化实践》。
团队介绍
数据仓库架构团队负责数据仓库领域架构设计,支持字节跳动几乎所有产品线(包含但不限于抖音、今日头条、西瓜视频、火山视频)数据仓库方向的需求,如 Spark SQL / Druid 的二次开发和优化。
概括
今天的分享分为三个部分,第一个部分是 SparkSQL 的架构简介,第二部分介绍字节跳动在 SparkSQL 引擎上的优化实践,第三部分是字节跳动在 Spark Shuffle 稳定性提升和性能优化上的实践与探索。
Spark SQL 架构简介
我们先简单聊一下Spark SQL 的架构。下面这张图描述了一条 SQL 提交之后需要经历的几个阶段,结合这些阶段就可以看到在哪些环节可以做优化。

很多时候,做数据仓库建模的同学更倾向于直接写 SQL 而非使用 Spark 的 DSL。一条 SQL 提交之后会被 Parser 解析并转化为 Unresolved Logical Plan。它的重点是 Logical Plan 也即逻辑计划,它描述了希望做什么样的查询。Unresolved 是指该查询相关的一些信息未知,比如不知道查询的目标表的 Schema 以及数据位置。
上述信息存于 Catalog 内。在生产环境中,一般由 Hive Metastore 提供 Catalog 服务。Analyzer 会结合 Catalog 将 Unresolved Logical Plan 转换为 Resolved Logical Plan。
到这里还不够。不同的人写出来的SQL 不一样,生成的 Resolved Logical Plan 也就不一样,执行效率也不一样。为了保证无论用户如何写 SQL 都可以高效的执行,Spark SQL 需要对 Resolved Logical Plan 进行优化,这个优化由 Optimizer 完成。Optimizer 包含了一系列规则,对 Resolved Logical Plan 进行等价转换,最终生成 Optimized Logical Plan。该 Optimized Logical Plan 不能保证是全局最优的,但至少是接近最优的。
上述过程只与 SQL 有关,与查询有关,但是与 Spark 无关,因此无法直接提交给 Spark 执行。Query Planner 负责将 Optimized Logical Plan 转换为 Physical Plan,进而可以直接由 Spark 执行。
由于同一种逻辑算子可以有多种物理实现。如 Join 有多种实现,ShuffledHashJoin、BroadcastHashJoin、BroadcastNestedLoopJoin、SortMergeJoin 等。因此 Optimized Logical Plan 可被 Query Planner 转换为多个 Physical Plan。如何选择最优的 Physical Plan 成为一件非常影响最终执行性能的事情。一种比较好的方式是,构建一个 Cost Model,并对所有候选的 Physical Plan 应用该 Model 并挑选 Cost 最小的 Physical Plan 作为最终的 Selected Physical Plan。
Physical Plan 可直接转换成 RDD 由 Spark 执行。我们经常说“计划赶不上变化”,在执行过程中,可能发现原计划不是最优的,后续执行计划如果能根据运行时的统计信息进行调整可能提升整体执行效率。这部分动态调整由 Adaptive Execution 完成。
后面介绍字节跳动在 Spark SQL 上做的一些优化,主要围绕这一节介绍的逻辑计划优化与物理计划优化展开。
Spark SQL引擎优化
Bucket Join改进
在 Spark 里,实际并没有 Bucket Join 算子。这里说的 Bucket Join 泛指不需要 Shuffle 的 SortMergeJoin。
下图展示了 SortMergeJoin 的基本原理。用虚线框代表的 Table 1 和 Table 2 是两张需要按某字段进行 Join 的表。虚线框内的 partition 0 到 partition m 是该表转换成 RDD 后的 Partition,而非表的分区。假设 Table 1 与 Table 2 转换为 RDD 后分别包含 m 和 k 个 Partition。为了进行 Join,需要通过 Shuffle 保证相同 Join Key 的数据在同一个 Partition 内且 Partition 内按 Key 排序,同时保证 Table 1 与 Table 2 经过 Shuffle 后的 RDD 的 Partition 数相同。
如下图所示,经过 Shuffle 后只需要启动 n 个 Task,每个 Task 处理 Table 1 与 Table 2 中对应 Partition 的数据进行 Join 即可。如 Task 0 只需要顺序扫描 Shuffle 后的左右两边的 partition 0 即可完成 Join。
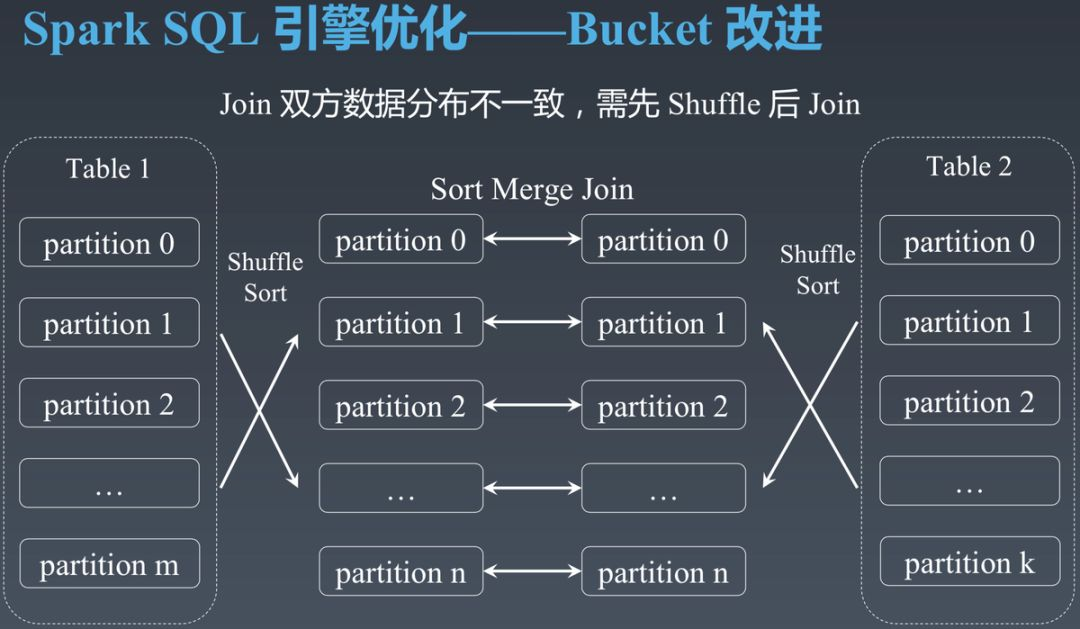
该方法的优势是适用场景广,几乎可用于任意大小的数据集。劣势是每次 Join 都需要对全量数据进行 Shuffle,而 Shuffle 是最影响 Spark SQL 性能的环节。如果能避免 Shuffle 往往能大幅提升 Spark SQL 性能。
对于大数据的场景来讲,数据一般是一次写入多次查询。如果经常对两张表按相同或类似的方式进行 Join,每次都需要付出 Shuffle 的代价。与其这样,不如让数据在写的时候,就让数据按照利于 Join 的方式分布,从而使得 Join 时无需进行 Shuffle。如下图所示,Table 1 与 Table 2 内的数据按照相同的 Key 进行分桶且桶数都为 n,同时桶内按该 Key 排序。对这两张表进行 Join 时,可以避免 Shuffle,直接启动 n 个 Task 进行 Join。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









