



Day 3
一.二进制与内存对齐
1.二进制
二进制:逢二进一
8421法:最后一位代表 2的0次 倒数第二位2的1次 以此类推
字符是通过ASCII码来转换为数字,然后转化为二进制储存
2.内存对齐
内存对齐的概念:在实际的内存存储中,还有一个重要的概念叫做 “内存对齐”。这是为了提高内存访问效率而采用的策略。
想象一下,如果你要从书架上取书,整齐摆放的书比杂乱摆放的书更容易找到和取出。内存对齐就是这样,它让数据在内存中按照一定的规则整齐摆放。
3. 栈区和堆区的存储
程序中的变量根据定义方式的不同,会被存储在内存的不同区域:
栈区存储
局部变量(在函数内部定义的变量)通常存储在栈区。栈区就像一摞盘子,后放的盘子在上面,先拿走的也是上面的盘子,这叫做 “后进先出”。
当函数被调用时,函数的局部变量会被 “压入” 栈中;当函数结束时,这些变量会被自动 “弹出” 栈,内存空间会被自动回收。
堆区存储
动态分配的内存(使用 malloc 等函数分配的内存)存储在堆区。堆区的管理比栈区复杂,程序员需要手动申请和释放内存。
全局区存储
全局变量和静态变量存储在全局区,这些变量在程序运行期间一直存在。
二.字节序
1.概念
(1)什么是字节序?
字节序(Byte Order)是一个听起来很技术化的概念,但实际上可以用一个很简单的例子来理解。
想象一下,你要在纸上写下数字 “1234”,你会从左到右写,先写 1,再写 2,然后 3,最后 4。但是,如果有些人习惯从右到左写字,他们可能会先写 4,再写 3,然后 2,最后 1,最终在纸上呈现的可能是 “4321”。
在计算机世界中,也存在类似的情况。当一个数据需要多个字节来存储时,这些字节在内存中的排列顺序就是字节序的问题。
(2)大端序与小端序
计算机世界中主要有两种字节序:大端序(Big Endian)和小端序(Little Endian)。
大端序(Big Endian)
大端序的排列方式是高位字节存储在低地址,低位字节存储在高地址。这就像我们平常写数字的习惯一样,高位在前,低位在后。
举个例子,十六进制数 0x12345678 在大端序的 32 位系统中会这样存储:
- 地址 1000: 0x12(最高位字节)
- 地址 1001: 0x34
- 地址 1002: 0x56
- 地址 1003: 0x78(最低位字节)
大端序的命名来源于《格列佛游记》中的故事,在那个故事里,有些人习惯从大头(Big End)开始吃鸡蛋。
小端序(Little Endian)
小端序的排列方式正好相反,低位字节存储在低地址,高位字节存储在高地址。这就像倒着写数字一样。
同样的十六进制数 0x12345678 在小端序的 32 位系统中会这样存储:
- 地址 1000: 0x78(最低位字节)
- 地址 1001: 0x56
- 地址 1002: 0x34
- 地址 1003: 0x12(最高位字节)
小端序的命名也来源于《格列佛游记》,对应从小头(Little End)开始吃鸡蛋的人。
三.常见数据类型
字符型数据类型
这里我们不多说浮点型和整形,直接说字符型
char类型通常占用一个字节 所以最多可以表示256个数据
char 要配合ASCII码表来定义字符
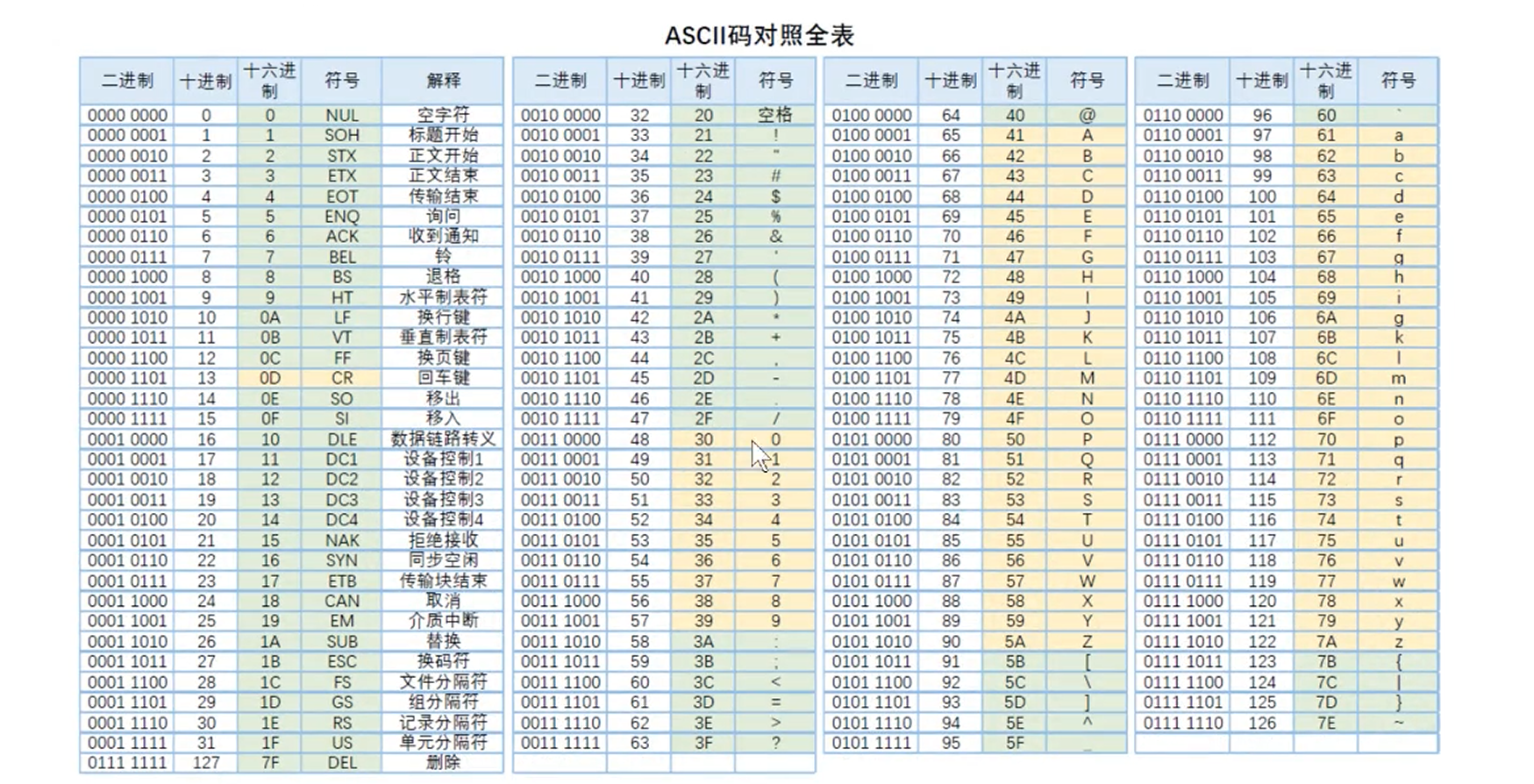
比如我们表示 A 可以是 char ch=‘A’; 也可以是 char ch = 65;
printf 打印时 用的是 %c 如果用%d输出的话,将输出ASCII码表对应的数字
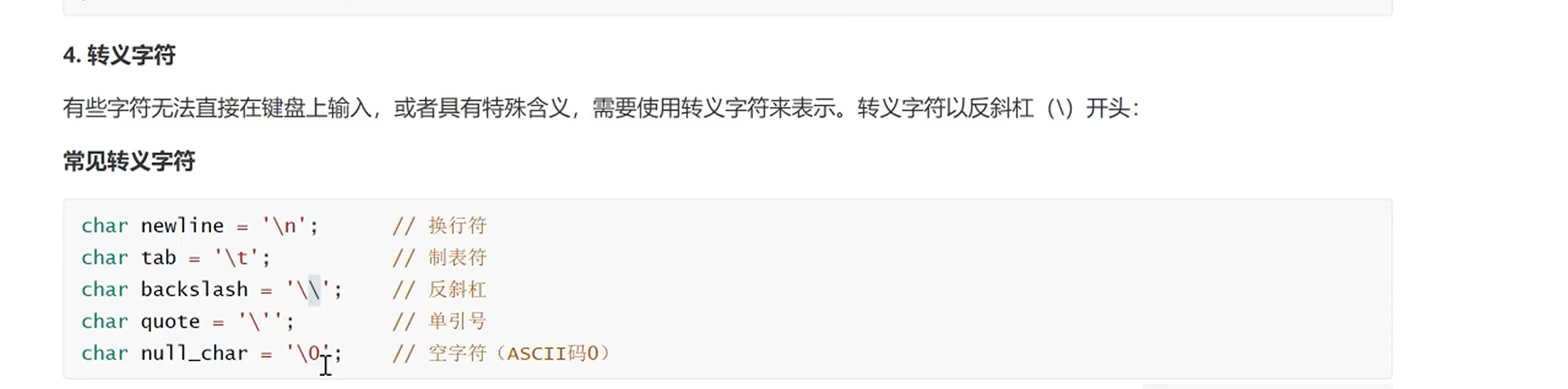
转义字符
常量
1.字面常量
概念:字面常量(Literal Constants)是直接写在程序代码中的具体数值,它们的值在编写程序时就已经确定,不能在程序运行时改变。字面常量就像是直接写在纸上的数字或文字,你看到的就是它们的值。
在程序中,当我们写下 int age = 25; 时,这里的 25 就是一个整数字面常量。当我们写下 printf (“Hello”); 时,“Hello” 就是一个字符串字面常量。这些值直接出现在代码中,编译器在编译时就知道它们的确切值。
字面常量是最直接的常量表示方法,虽然使用简单,但在大型程序中可能会带来维护上的困难,因为相同的字面常量可能在程序中多次出现,修改时需要逐一查找替换。
int a = 100; // 十进制
short b = 200;
int c = 010; // 八进制
int hex = 0x1F; // 十六进制
int binary = 0b1010; // 二进制
// 浮点型
float pi = 3.14f;//f表示明确告诉计算机将1.2当作float处理 否则可能会当作double赋给float
//从而引发问题
double height = 1.75;
// 字符型
char letter = 'A';
// 科学计数
double light_speed = 2.998E8;
2.符号常量
符号常量的概念和重要性
符号常量是为常量值指定一个有意义名称的机制,它让程序更易读、更易维护。如果说字面常量是在代码中直接写出具体数值,那么符号常量就是给这些数值起一个好记的名字。
想象一下,在一个计算几何面积的程序中,如果到处都出现 3.14159 这个数字,当有一天需要更高精度的 π 值时,你需要在整个程序中查找并替换所有的 3.14159。但如果使用符号常量 PI,只需要在定义处修改一次即可。
符号常量不仅仅是为了方便修改数值,更重要的是它提高了代码的可读性。当你看到 if (speed> SPEED_LIMIT) 时,比看到 if (speed > 120) 更容易理解代码的意图。
在 C 语言中,有两种主要的符号常量定义方法:#define 宏定义和 const 关键字定义。每种方法都有其特点和适用场景。
#define 宏定义
#define 是 C 语言预处理指令,用于定义宏。通过 #define 定义的符号常量在预处理阶段被文本替换,不占用运行时内存。
#define 的基本语法是:#define 宏名 替换文本
#define PI 3.14159265359
const关键字定义
const double area=8.8;//这样以后area将会成为常量
3.枚举常量
枚举(enumeration)是 C 语言提供的一种定义常量集合的机制,特别适用于定义一组相关的整数常量。枚举让程序更具可读性,也更不容易出错。
想象一下,如果要表示一周的七天,你可能会这样定义:
#define MONDAY 1
#define TUESDAY 2
#define WEDNESDAY 3
#define THURSDAY 4
#define FRIDAY 5
#define SATURDAY 6
#define SUNDAY 7
但是用枚举会更优雅:
enum weekday {
MONDAY,
TUESDAY,
WEDNESDAY,
THURSDAY,
FRIDAY,
SATURDAY,
SUNDAY
};
比如我们要定义性别
enum gender{
Male,
Female
};
我们可以利用printf 来确定Male 和 Female 的默认值为0 和 1,也就是说,枚举常量中的变量从上到下默认为 0,1,2,3 如果我们强行给Male赋值为 10 那么 Female 会默认为11,以此类推
四.变量
变量的作用域
变量的作用域(Scope)是指程序中可以访问该变量的代码区域。这就像现实生活中的 “管辖范围” 一样,一个村长的管辖范围是他的村子,一个市长的管辖范围是他的城市,超出这个范围,他们的权力就无法行使。
在 C 语言中,变量的作用域决定了在程序的哪些地方可以使用这个变量。理解作用域不仅有助于写出正确的程序,还能帮助我们更好地组织代码,避免变量名冲突,提高程序的可维护性。
作用域的概念与变量的生命周期密切相关,但两者不是同一个概念。作用域是指在源代码中可以访问变量的区域,而生命周期是指变量在程序运行时存在的时间段。
如果在花括号内部定义了变量,则这个变量只能在这个花括号内使用(如果是下一级花括号中进行访问,则也可以访问到)(可以总结为 外层不可访问内层,内层可访问外层)
帮助我们更好地组织代码,避免变量名冲突,提高程序的可维护性。
作用域的概念与变量的生命周期密切相关,但两者不是同一个概念。作用域是指在源代码中可以访问变量的区域,而生命周期是指变量在程序运行时存在的时间段。
如果在花括号内部定义了变量,则这个变量只能在这个花括号内使用(如果是下一级花括号中进行访问,则也可以访问到)(可以总结为 外层不可访问内层,内层可访问外层)

















 405
405

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









