



 博客主要围绕逻辑回归展开,先进行分类散点图可视化,展示未区分类别和区分类别的散点图。接着介绍逻辑回归模型的使用,包括引入库、读入数据,然后建立型数据集,最后对模型进行评估,如计算准确率、可视化模型表现等。
博客主要围绕逻辑回归展开,先进行分类散点图可视化,展示未区分类别和区分类别的散点图。接着介绍逻辑回归模型的使用,包括引入库、读入数据,然后建立型数据集,最后对模型进行评估,如计算准确率、可视化模型表现等。
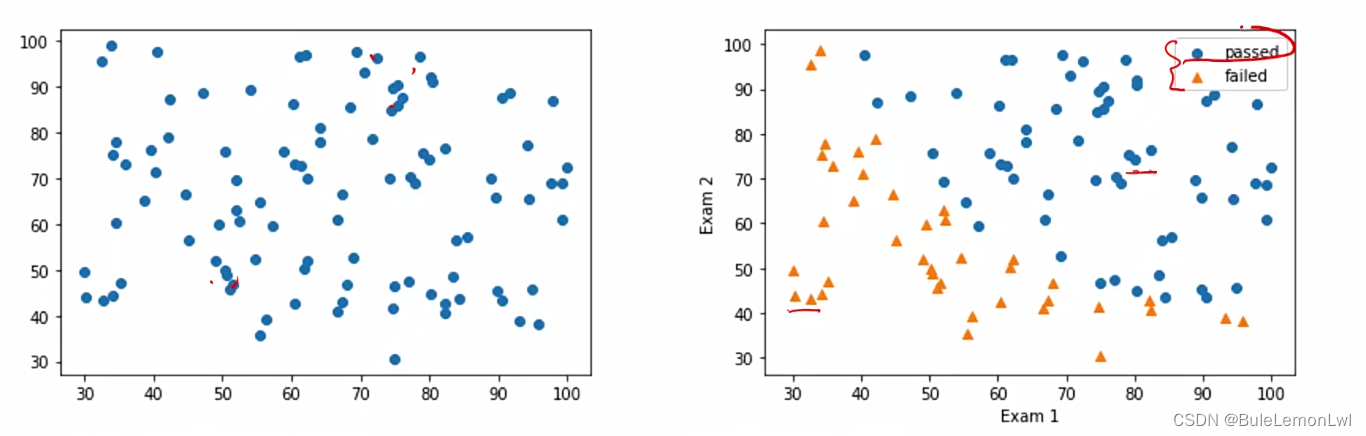
一、分类散点图可视化
1.分类散点图可视化:
未区分类别散点图:plt.scatter(X1,X2)
区分类别散点图:
mask=y==1
passed=plt.scatter(X1[mask],X2[mask])
failed=plt.scatter(X1[mask],X2[mask],marker=‘^’)。
区别如下图:
二、逻辑回归模型使用
1.引入库
模型训练:
from sklearn.linear_model import LogisticRegression
lr_model = LogisticRegression()
lr_model.fit(x,y)
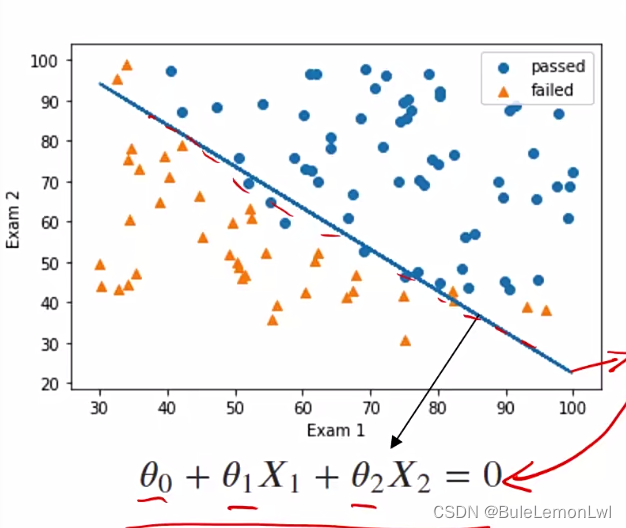
边界函数系数:
theta1,theta2 = lr_model.coef_[0][0],lr_model.coef_[0][1]
theta0 = LR.intercept_[0]
对新数据做预测:
predictions = lr_model.predict(x)
生成新的属性数据:
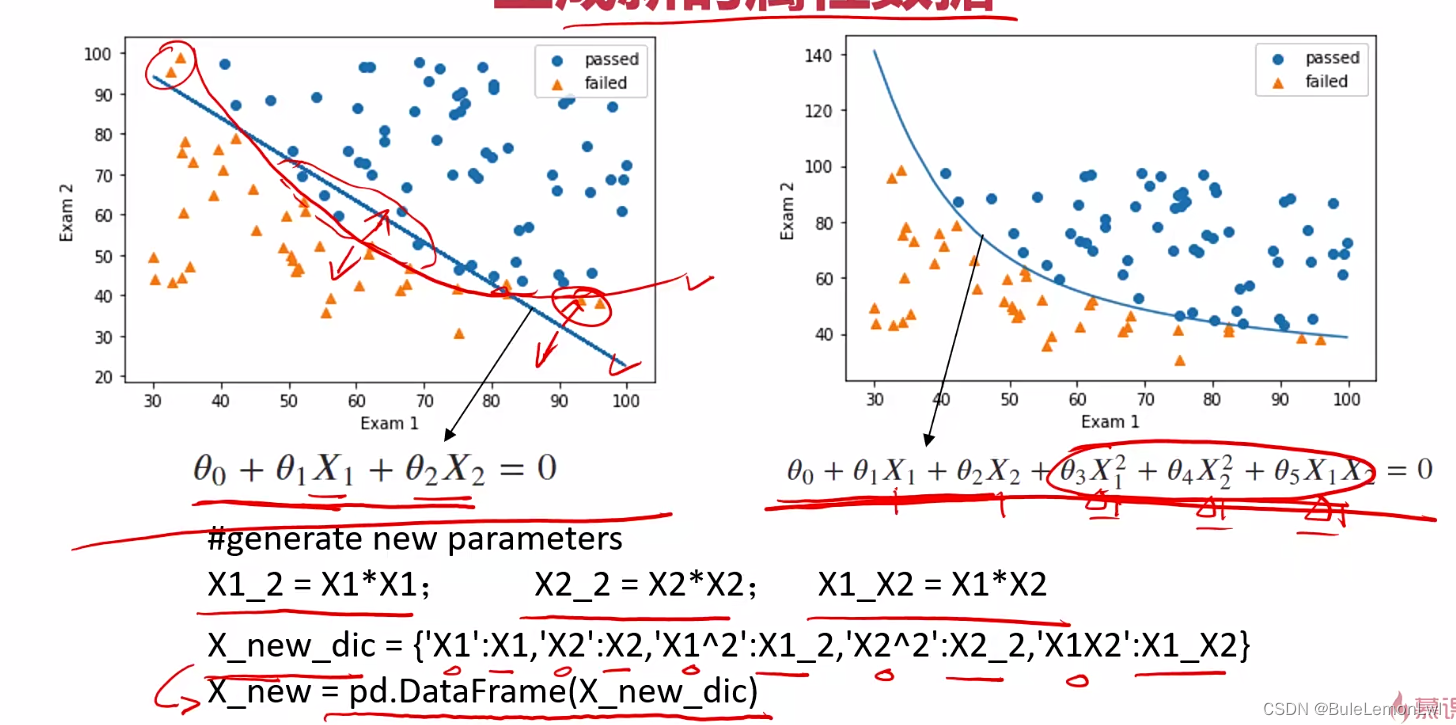
2.读入数据
代码如下(示例):
data = pd.read_csv(
'https://labfile.oss.aliyuncs.com/courses/1283/adult.data.csv')
print(data.head())
三、建立型数据集
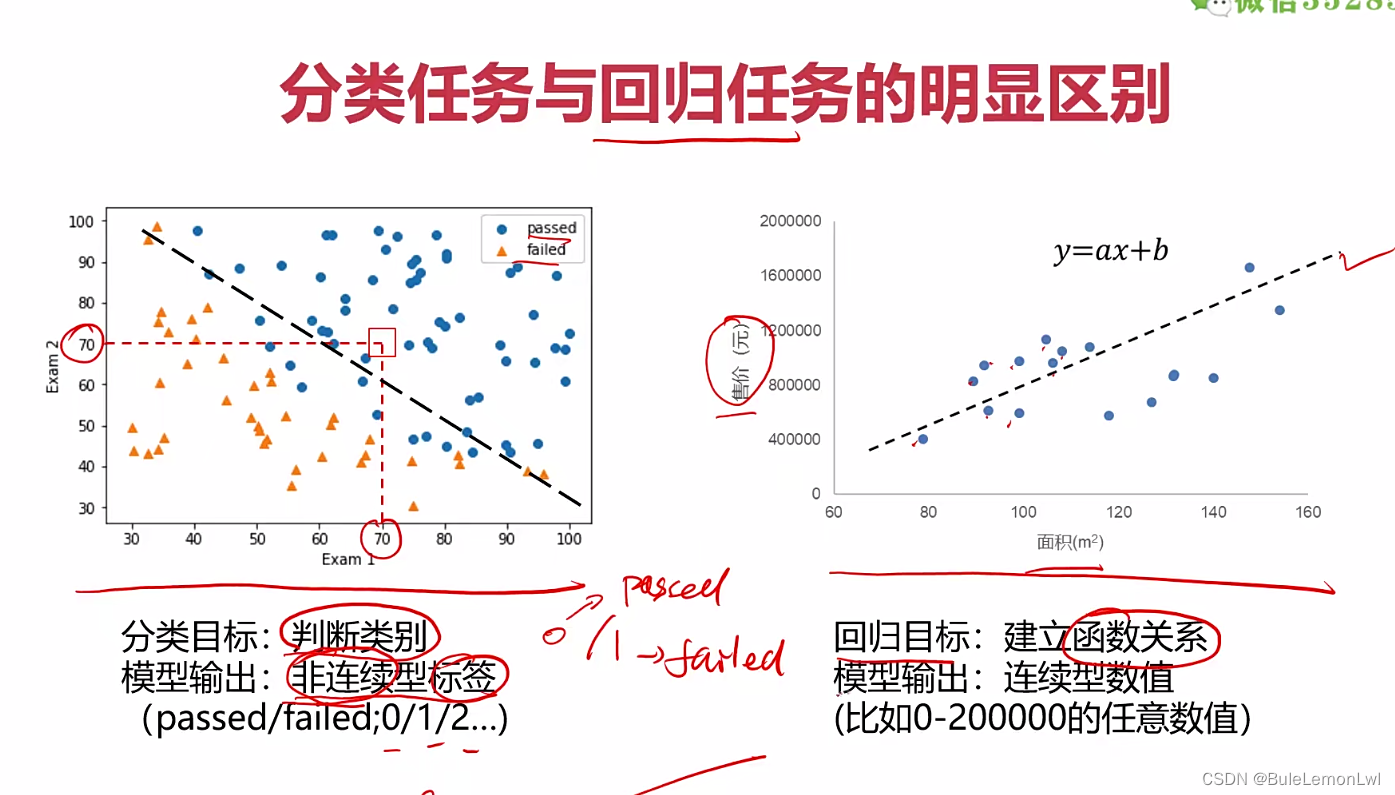
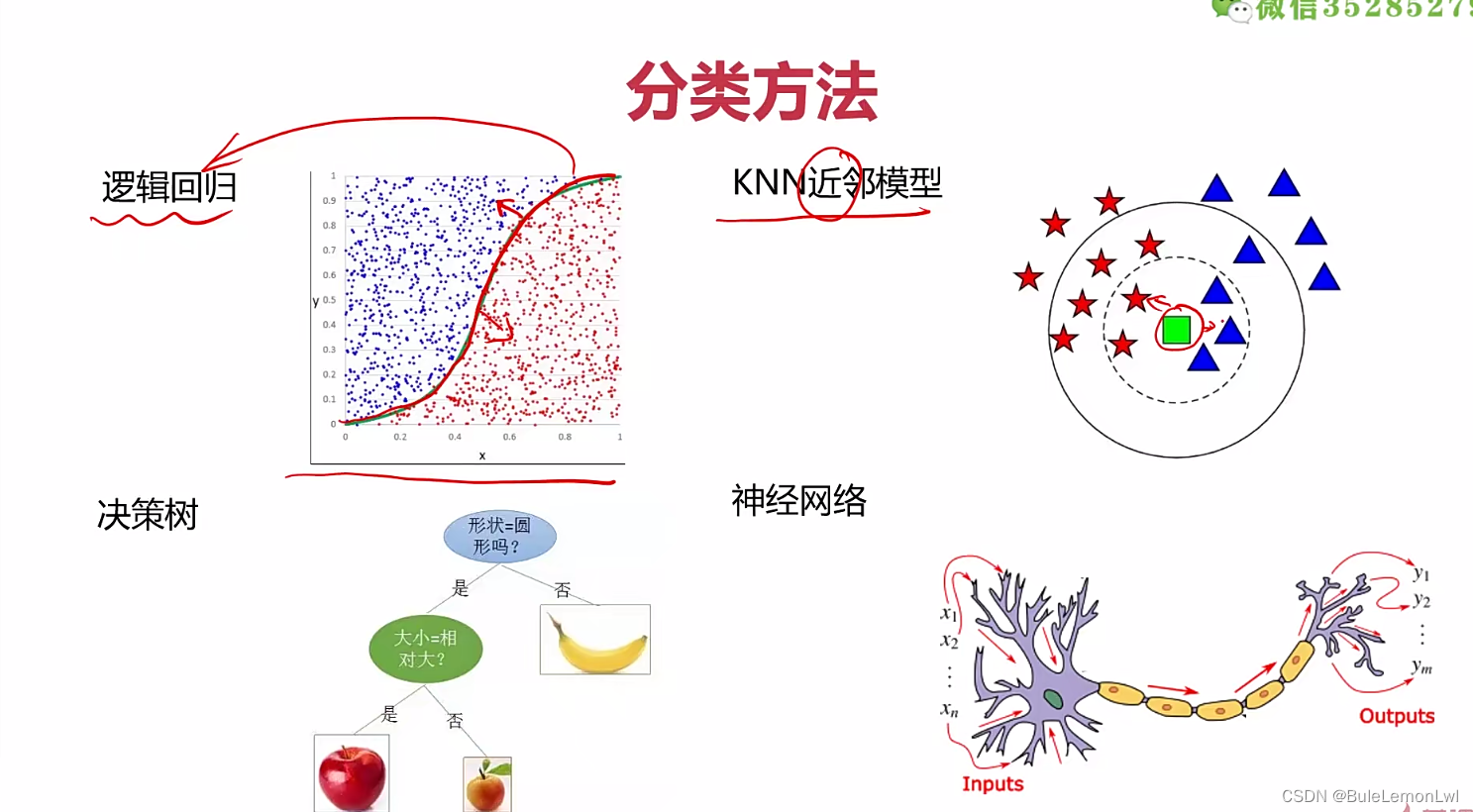
四、模型评估
评估模型表现:
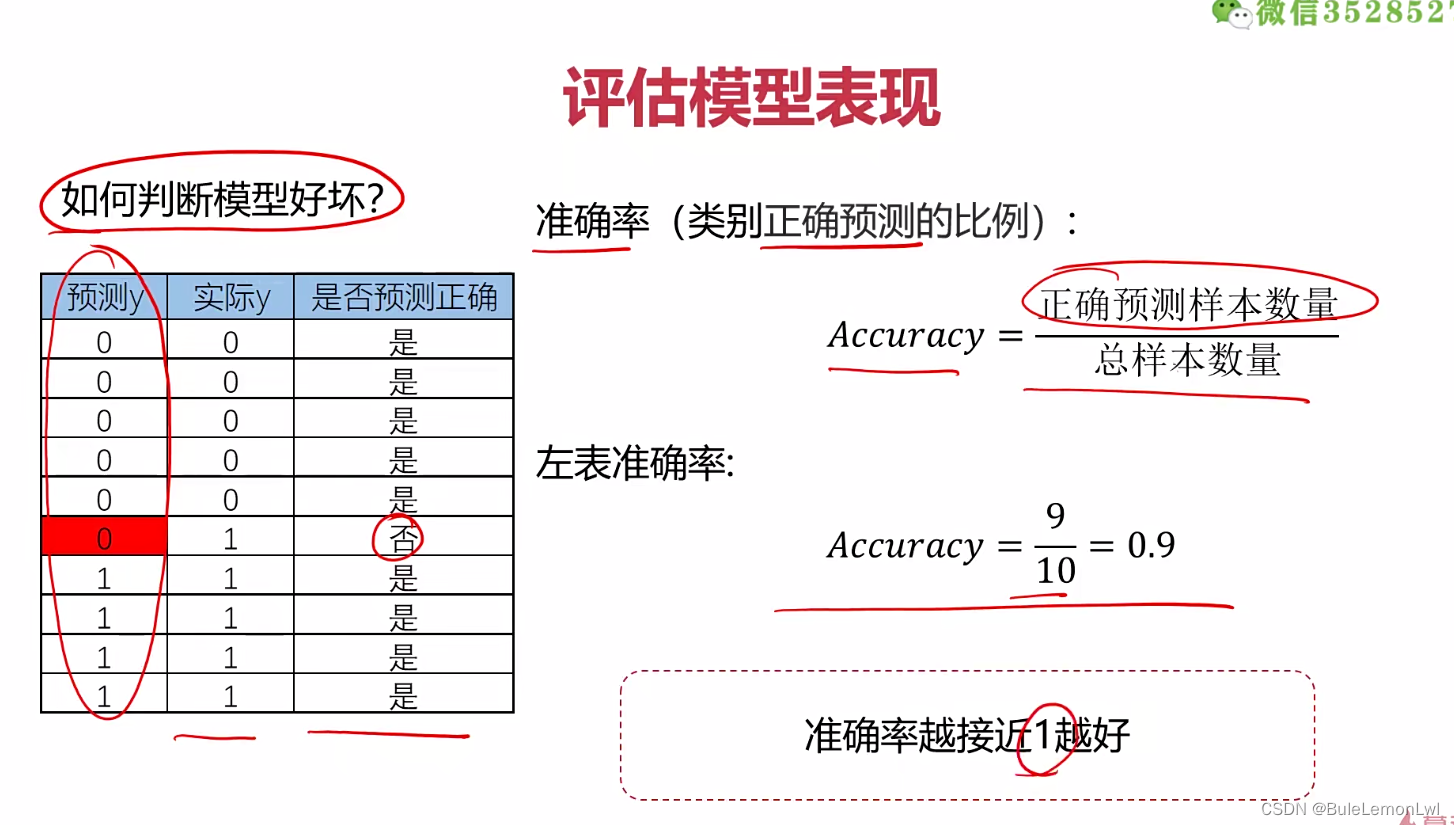 计算准确率:
计算准确率:
from sklearn.metrics import accuracy_score
y_predict = lr_model.predict(X)
accuracy = accuracy_score(y,y_predict)
画图看决策边界效果,可视化模型表现:
plt.plot(x1,x2_boundary)
passed = plt.scatter(X1[mask],X2[mask])
failed = plt.scatter(X1[~mask],X2[~mask],maker='^')


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









