







一.Spring Boot整合JPA
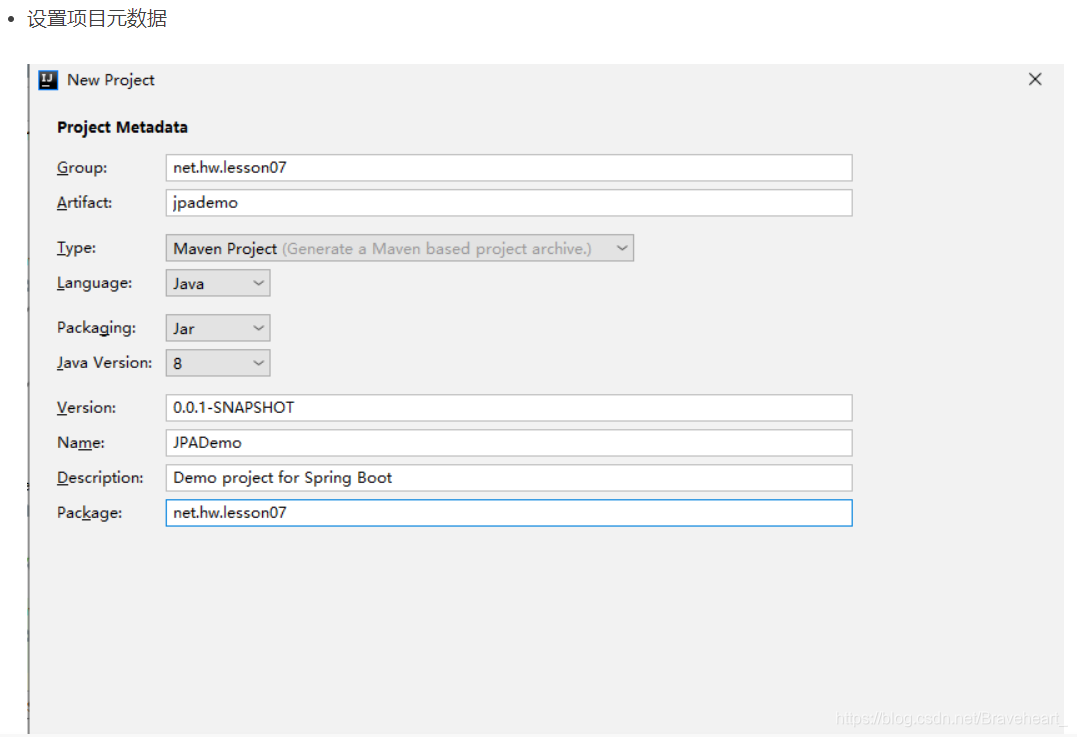
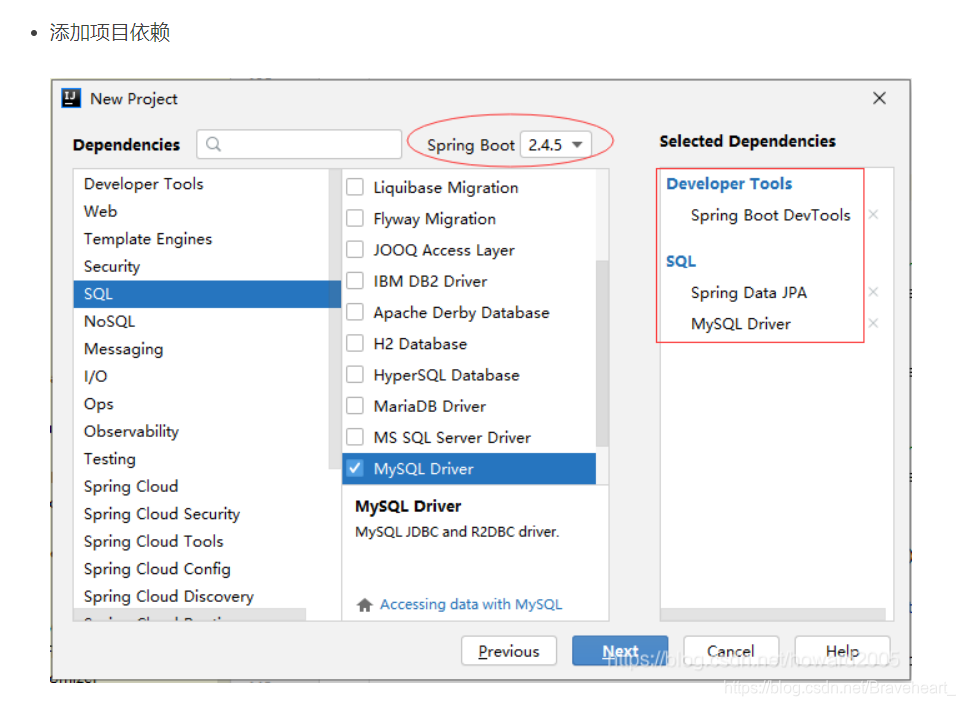
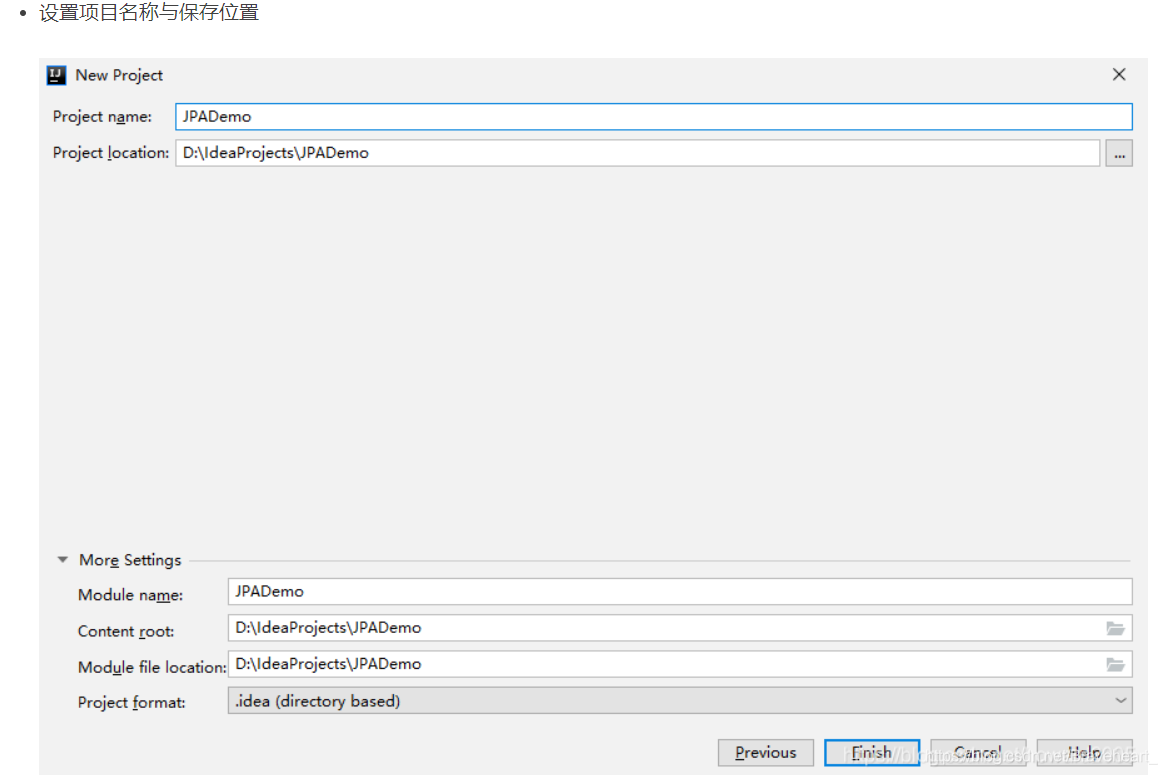
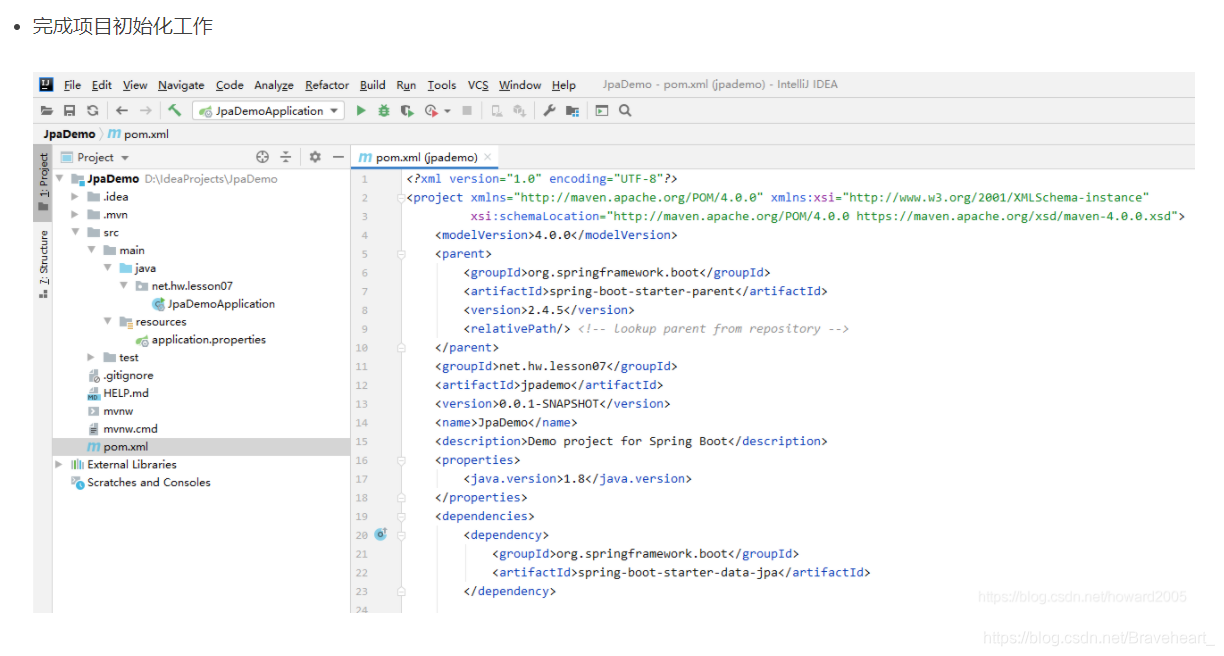
(一)创建Spring Boot项目JPADemo
(二)创建ORM实体类
.ORM: Object Relation Mapping 对象关系映射 (Object: Java Bean; Relation: Table)
package net.hw.lesson07.bean;
import javax.persistence.*;
@Entity(name = "t_comment")
public class Comment {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
@Column(name = "id")
private Integer id;
@Column(name = "content")
private String content;
@Column(name = "author")
private String author;
@Column(name = "a_id")
private Integer aId;
public Integer getId() {
return id;
}
public void setId(Integer id) {
this.id = id;
}
public String getContent() {
return content;
}
public void setContent(String content) {
this.content = content;
}
public String getAuthor() {
return author;
}
public void setAuthor(String author) {
this.author = author;
}
public Integer getaId() {
return aId;
}
public void setaId(Integer aId) {
this.aId = aId;
}
@Override
public String toString() {
return "Comment{" +
"id=" + id +
", content='" + content + '\'' +
", author='" + author + '\'' +
", aId=" + aId +
'}';
}
}
.@Entity中的name对应数据库中表名
.GenerationType.IDENTITY为MySQL中自增使用的策略,不同类型的数据库使用策略不同
2、创建文章实体类 - Article
package net.hw.lesson07.bean;
import javax.persistence.*;
import java.util.List;
/**
* 功能:文章实体类
* 作者:华卫
* 日期:2021年05月12日
*/
@Entity(name = "t_article")
public class Article {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
@Column(name = "id")
private Integer id;
@Column(name = "title")
private String title;
@Column(name = "content")
private String content;
// 查询时将子表一并查询出来
@OneToMany(fetch = FetchType.EAGER) // FetchType.LAZY 懒加载
@JoinTable(name = "t_comment", joinColumns = {@JoinColumn(name = "a_id")},
inverseJoinColumns = {@JoinColumn(name = "id")})
private List<Comment> commentList;
public Integer getId() {
return id;
}
public void setId(Integer id) {
this.id = id;
}
public String getTitle() {
return title;
}
public void setTitle(String title) {
this.title = title;
}
public String getContent() {
return content;
}
public void setContent(String content) {
this.content = content;
}
public List<Comment> getCommentList() {
return commentList;
}
public void setCommentList(List<Comment> commentList) {
this.commentList = commentList;
}
@Override
public String toString() {
return "Article{" +
"id=" + id +
", title='" + title + '\'' +
", content='" + content + '\'' +
", commentList=" + commentList +
'}';
}
}
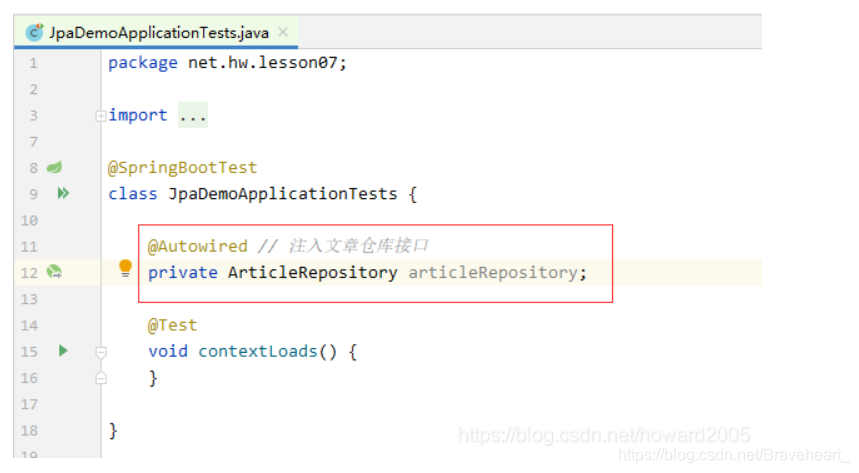
(三)创建自定义JpaRepository接口 - ArticleRepository

package net.hw.lesson07.repository;
import net.hw.lesson07.bean.Article;
import org.springframework.data.jpa.repository.JpaRepository;
public interface ArticleRepository extends JpaRepository<Article, Integer> {
}
注意,接口里什么代码也没写,是不是感觉很简单?
(四)添加数据源依赖,配置数据源属性
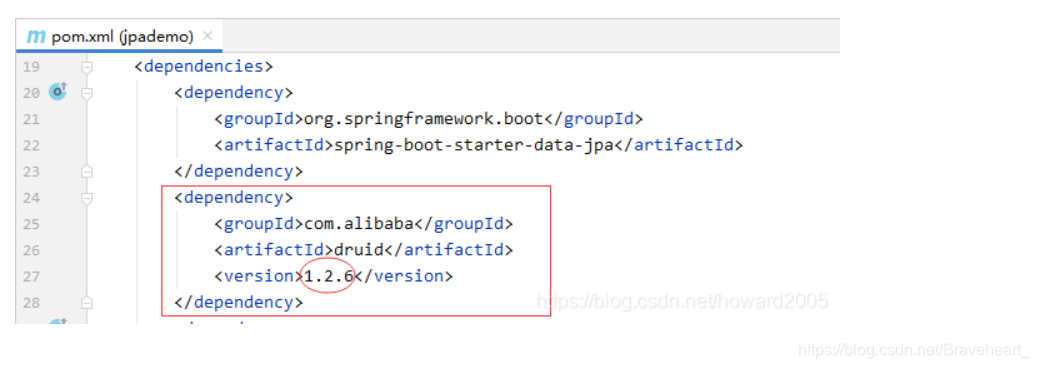
1、在pom.xml里添加阿里巴巴数据源依赖
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>druid-spring-boot-starter</artifactId>
<version>1.2.6</version>
</dependency>
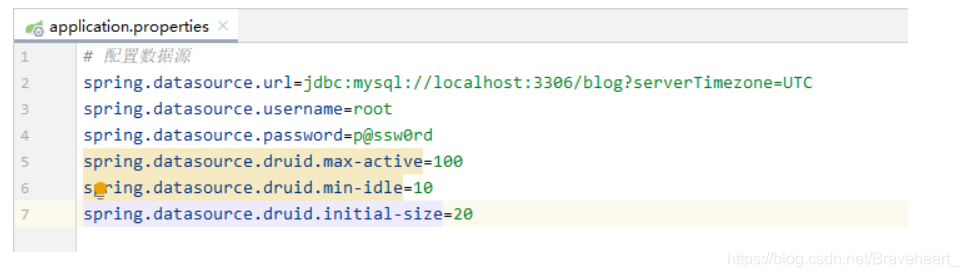
2、在全局配置文件里配置数据源
# 配置数据源
spring.datasource.url=jdbc:mysql://localhost:3306/blog?serverTimezone=UTC
spring.datasource.username=root
spring.datasource.password=p@ssw0rd
spring.datasource.druid.max-active=100
spring.datasource.druid.min-idle=10
spring.datasource.druid.initial-size=20
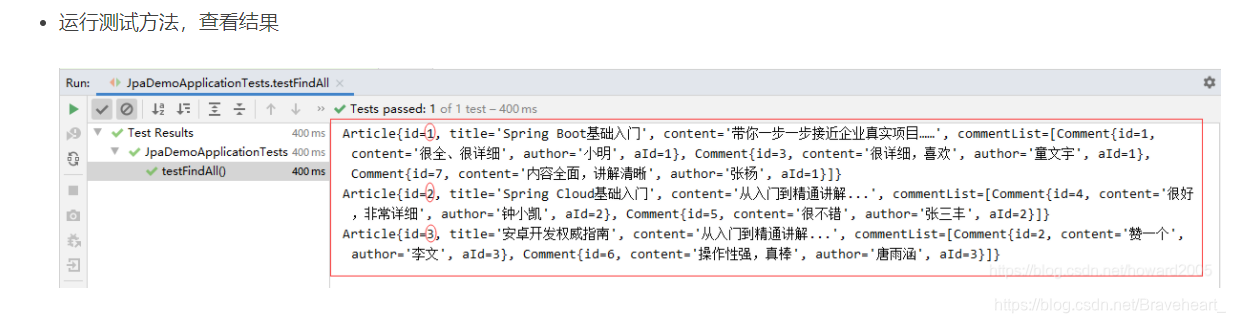
3、在测试类里编写测试方法
(1)注入文章仓库 - ArticleRepository
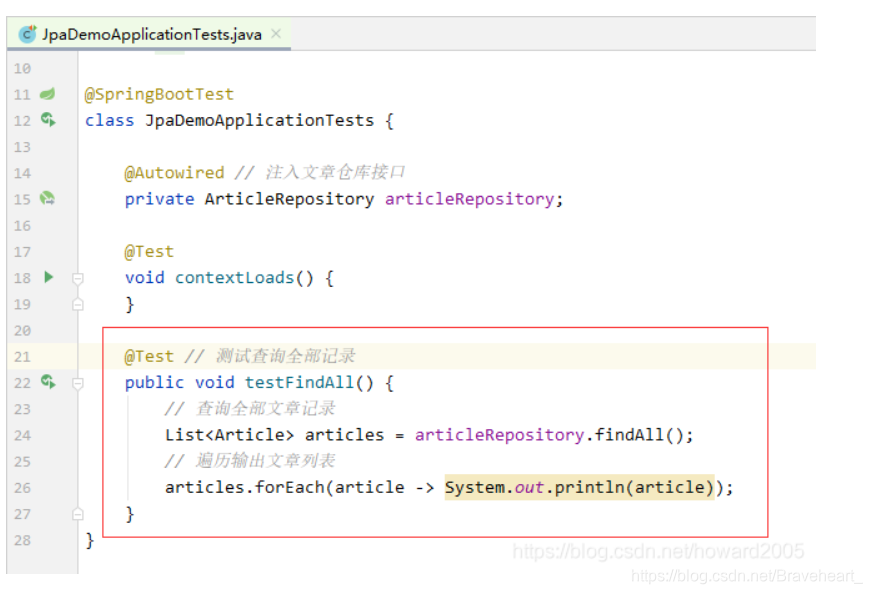
(2)创建测试方法testFindAll()
(一)案例 - 根据文章编号分页查询评论
1、创建评论仓库接口 - CommentRepository
package net.hw.lesson07.repository;
import net.hw.lesson07.bean.Comment;
import org.springframework.data.jpa.repository.JpaRepository;
public interface CommentRepository extends JpaRepository<Comment, Integer> {
}
2、定义按文章编号分页查询评论的方法
/**
* 根据文章ID进行分页查询评论
* nativeQuery = true, 表示使用原生SQL语句,否则使用HQL语句
* @param aId 查询条件字段(文章编号)
* @param pageable 可分页对象,分页查询需要该参数
* @return 返回page对象,包含page的相关信息及查询结果集
*/
@Query(value = "select * from t_comment where a_id = ?1", nativeQuery = true)
Page<Comment> findCommentPagedByArticleId01(Integer aId, Pageable pageable);
/**
* 根据文章ID进行分页查询评论
* 没有设置nativeQuery,默认就是false,表示使用HQL语句
* @param aId 查询条件字段(文章编号)
* @param pageable 可分页对象,分页查询需要该参数
* @return 返回page对象,包含page的相关信息及查询结果集
*/
@Query(value = "select c from t_comment c where c.aId = ?1")
Page<Comment> findCommentPagedByArticleId02(Integer aId, Pageable pageable);

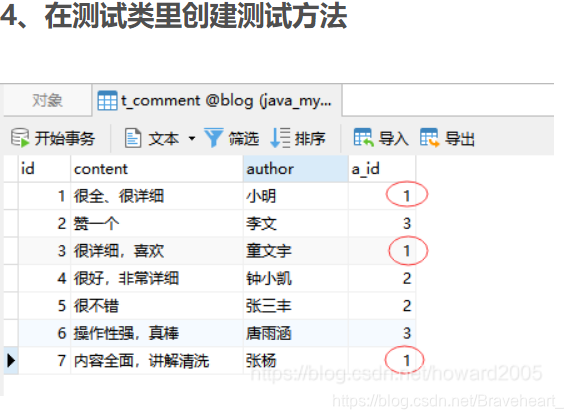
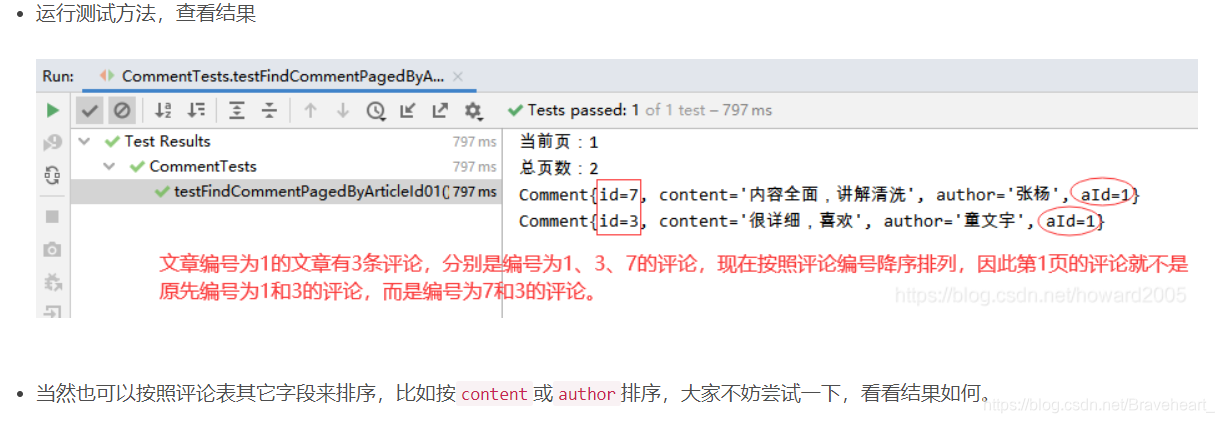
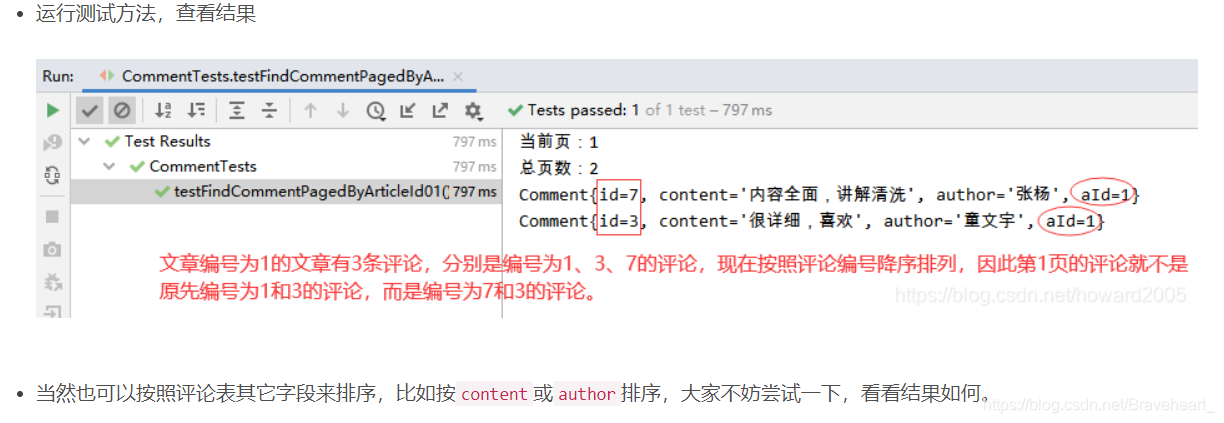
.文章编号为1的评论有3条,下面我们将3条评论分两页显示,每页大小为2(最多两条记录)。第1页:id为1和3的两条评论;第2页:id为7的一条评论。
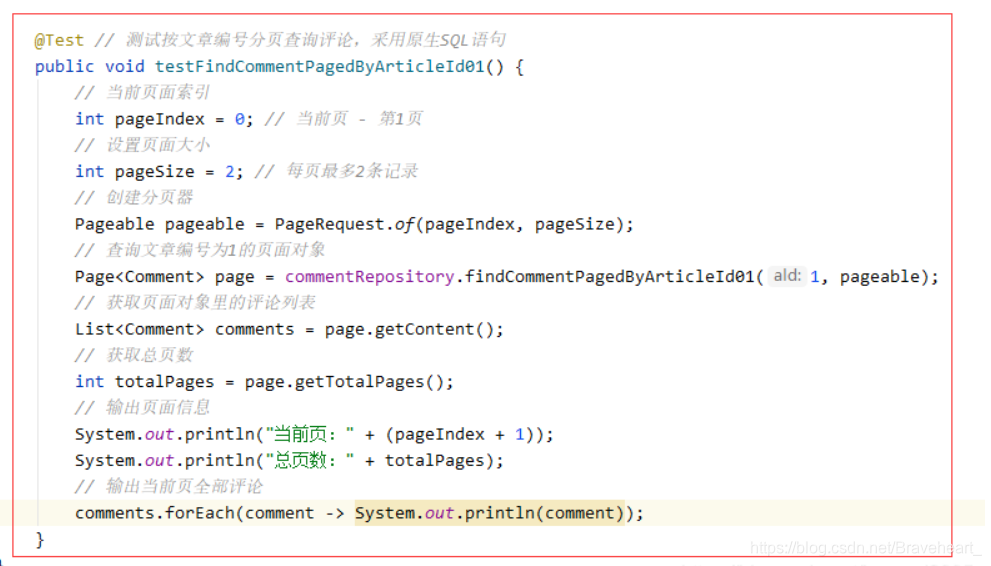
(1)创建测试方法testFindCommentPagedByArticleId01()
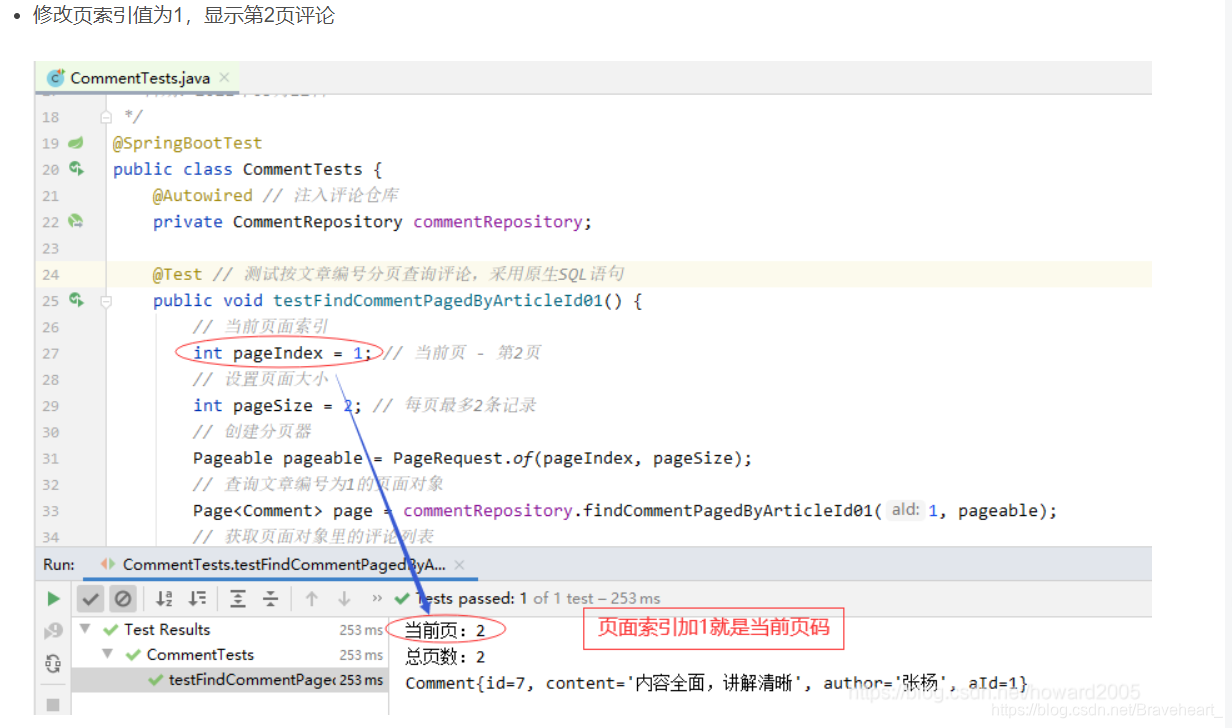
.设置pageIndex = 0,表明当前页为第1页
.设置pageSize = 2,表明每页最多两条记录
package net.hw.lesson07;
import net.hw.lesson07.bean.Comment;
import net.hw.lesson07.repository.CommentRepository;
import org.junit.jupiter.api.Test;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.test.context.SpringBootTest;
import org.springframework.data.domain.Page;
import org.springframework.data.domain.PageRequest;
import org.springframework.data.domain.Pageable;
import java.util.List;
/**
* 功能:测试评论查询方法.
* 作者:华卫
* 日期:2021年05月12日
*/
@SpringBootTest
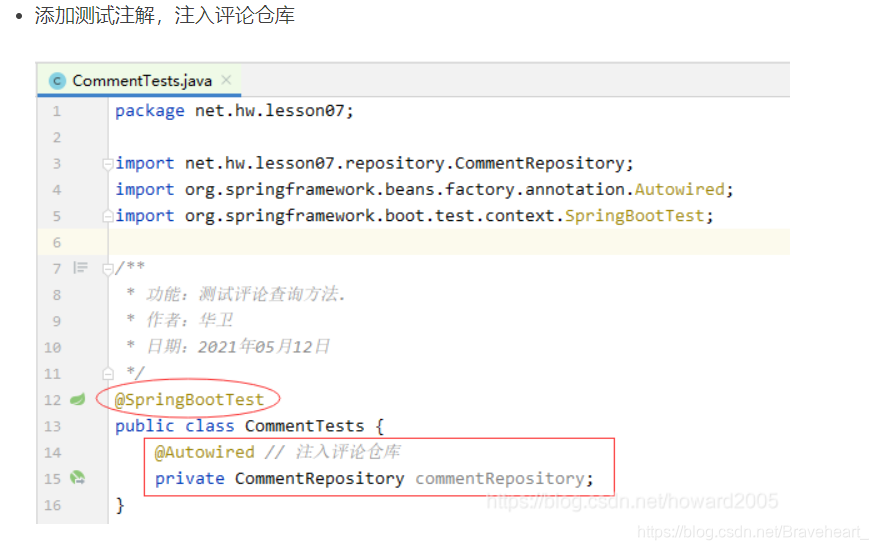
public class CommentTests {
@Autowired // 注入评论仓库
private CommentRepository commentRepository;
@Test // 测试按文章编号分页查询评论,采用原生SQL语句
public void testFindCommentPagedByArticleId01() {
// 当前页面索引
int pageIndex = 0; // 当前页 - 第1页
// 设置页面大小
int pageSize = 2; // 每页最多2条记录
// 创建分页器
Pageable pageable = PageRequest.of(pageIndex, pageSize);
// 查询文章编号为1的页面对象
Page<Comment> page = commentRepository.findCommentPagedByArticleId01(1, pageable);
// 获取页面对象里的评论列表
List<Comment> comments = page.getContent();
// 获取总页数
int totalPages = page.getTotalPages();
// 输出页面信息
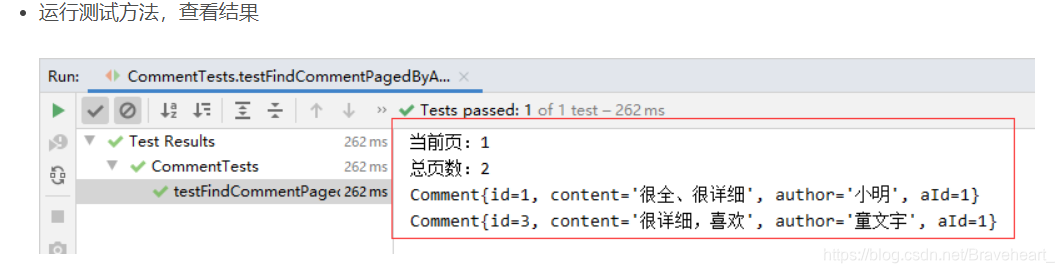
System.out.println("当前页:" + (pageIndex + 1));
System.out.println("总页数:" + totalPages);
// 输出当前页全部评论
comments.forEach(comment -> System.out.println(comment));
}
}


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









