




文章目录
一、若依定时任务页面
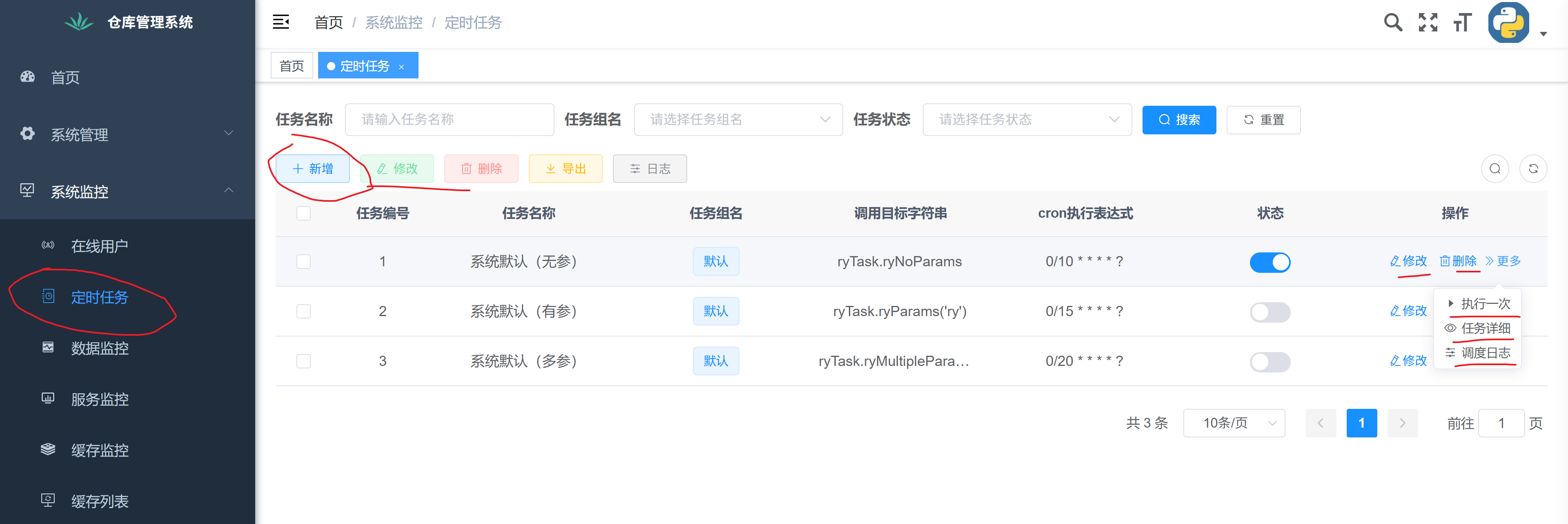
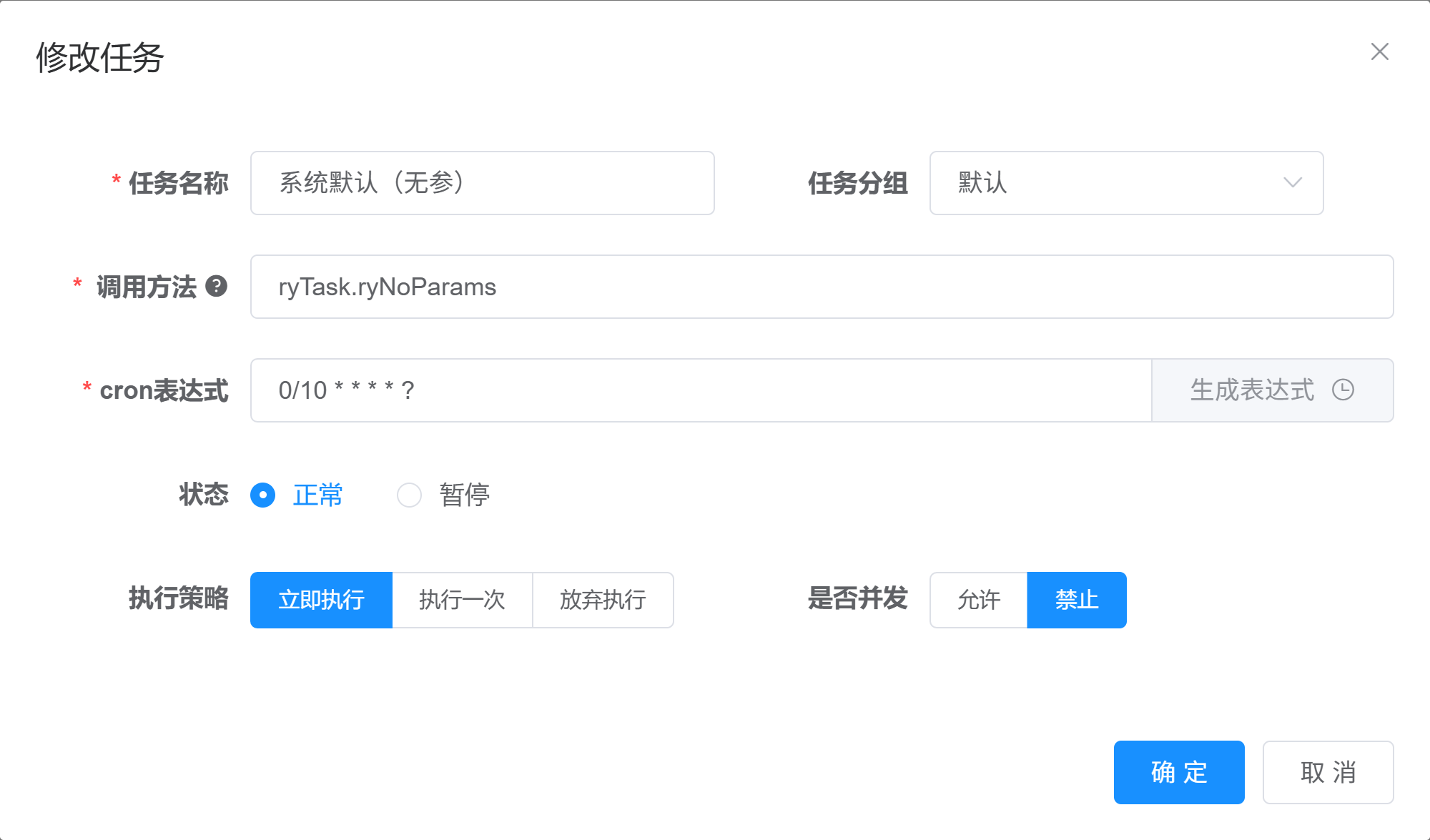
从页面,我们可以看出,若依系统对定时任务的常用操作:新增,修改,删除,执行一次,定时执行,查看日志,等。
二、源码分析
1、pom
在ruoyi-quartz模块中引入了quartz依赖
<!-- 定时任务 -->
<dependency>
<groupId>org.quartz-scheduler</groupId>
<artifactId>quartz</artifactId>
<exclusions>
<exclusion>
<groupId>com.mchange</groupId>
<artifactId>c3p0</artifactId>
</exclusion>
</exclusions>
</dependency>
2、MySQL表
sys_job、sys_job_log
只用了这两张表,大大缩减了quartz自带的表。
3、Java代码
3.1、任务接口相关逻辑
我们从页面触发,首先,这些定时任务是如何查询出来的?
定位到:com.ruoyi.quartz.controller.SysJobController
这里包含了,增删改查等基本功能。
顺着controller,可以查看到对应的service层、dao层代码。
3.2、新增任务
找到controller接口的add方法,进入serviceImpl,找到对应的新增实现。
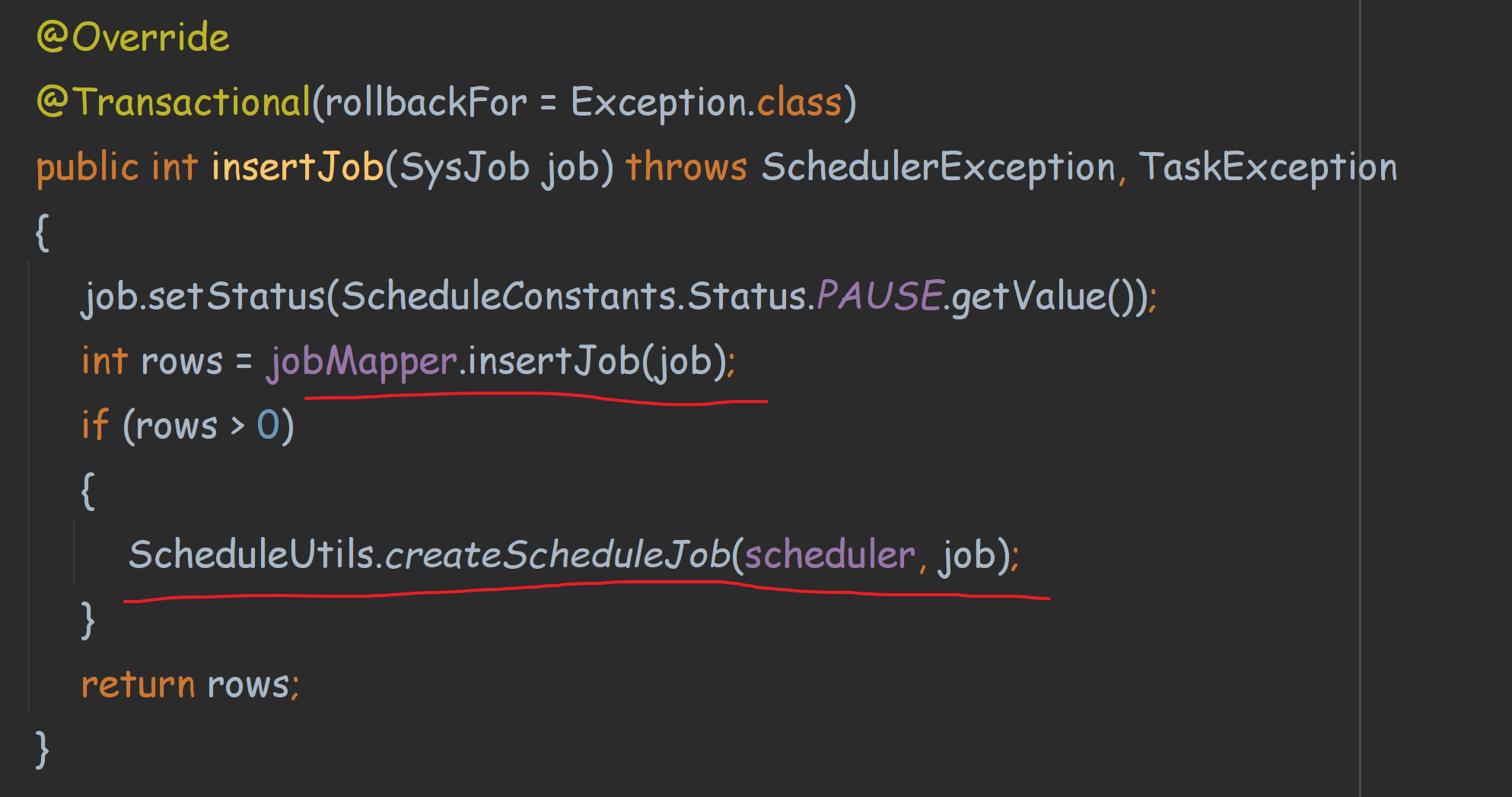
主要做了两件事
1、向数据库中,保存任务配置信息。
2、使用ScheduleUtils生成任务。
查看utils中具体的创建逻辑
public static void createScheduleJob(Scheduler scheduler, SysJob job) throws SchedulerException, TaskException
{
Class<? extends Job> jobClass = getQuartzJobClass(job);
// 构建job信息
Long jobId = job.getJobId();
String jobGroup = job.getJobGroup();
JobDetail jobDetail = JobBuilder.newJob(jobClass).withIdentity(getJobKey(jobId, jobGroup)).build();
// 表达式调度构建器
CronScheduleBuilder cronScheduleBuilder = CronScheduleBuilder.cronSchedule(job.getCronExpression());
cronScheduleBuilder = handleCronScheduleMisfirePolicy(job, cronScheduleBuilder);
// 按新的cronExpression表达式构建一个新的trigger
CronTrigger trigger = TriggerBuilder.newTrigger().withIdentity(getTriggerKey(jobId, jobGroup))
.withSchedule(cronScheduleBuilder).build();
// 放入参数,运行时的方法可以获取
jobDetail.getJobDataMap().put(ScheduleConstants.TASK_PROPERTIES, job);
// 判断是否存在
if (scheduler.checkExists(getJobKey(jobId, jobGroup)))
{
// 防止创建时存在数据问题 先移除,然后在执行创建操作
scheduler.deleteJob(getJobKey(jobId, jobGroup));
}
// 判断任务是否过期
if (StringUtils.isNotNull(CronUtils.getNextExecution(job.getCronExpression())))
{
// 执行调度任务
scheduler.scheduleJob(jobDetail, trigger);
}
// 暂停任务
if (job.getStatus().equals(ScheduleConstants.Status.PAUSE.getValue()))
{
scheduler.pauseJob(ScheduleUtils.getJobKey(jobId, jobGroup));
}
}
这里的逻辑,和我们之前学习的案例utils基本一致。
jobClass 、jobDetail、cronScheduleBuilder 、trigger 、scheduler
至此,任务就创建成功了。
三、若依对quartz的个性化使用
1、为什么我们在若依系统中,没有看到@PersistJobDataAfterExecution注解?
因为,若依系统的任务数据,不是存放在jobDetail中,所以,无需这个注解。
2、若依系统的Job类在哪里?
若依系统中,总共就两个Job实现。
private static Class<? extends Job> getQuartzJobClass(SysJob sysJob)
{
boolean isConcurrent = "0".equals(sysJob.getConcurrent());
return isConcurrent ? QuartzJobExecution.class : QuartzDisallowConcurrentExecution.class;
}
一个是运行并发的执行任务
一个是不允许并发任务,这个里面有@DisallowConcurrentExecution注解。
3、就两个job 实现,那么,如何开发多种任务?
我们看下Job类的内部实现
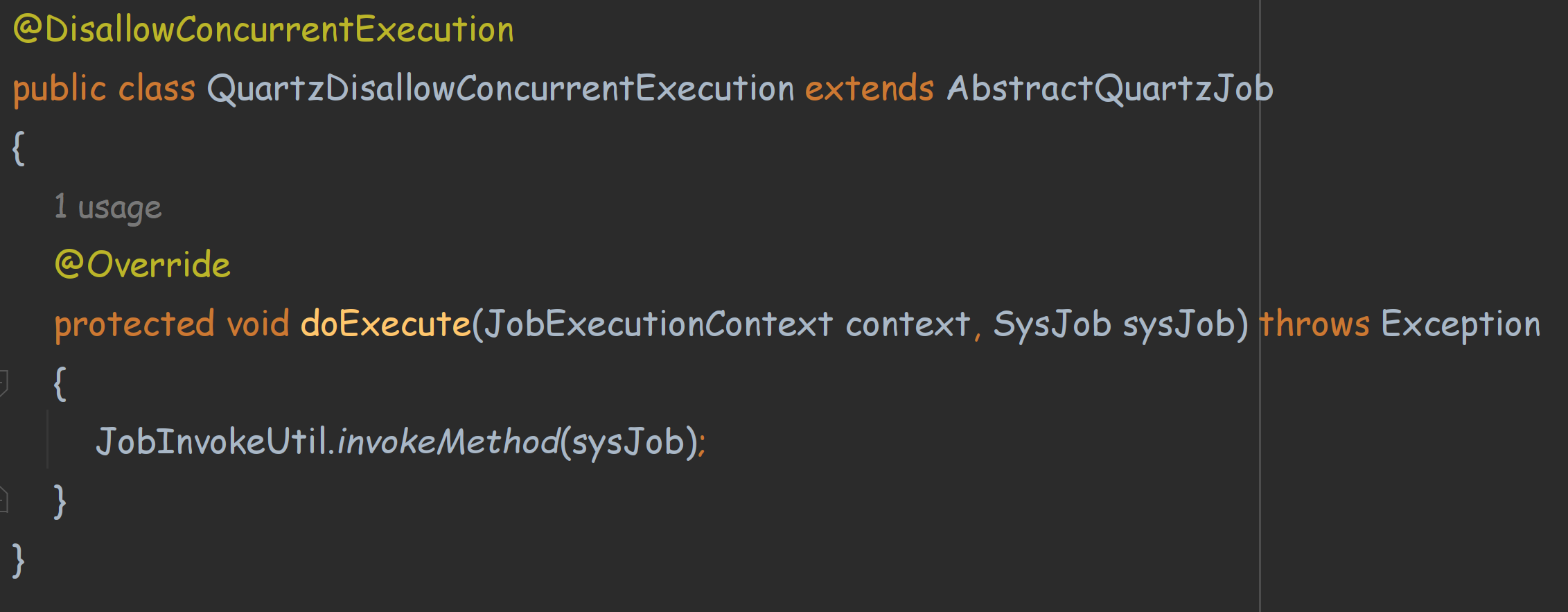
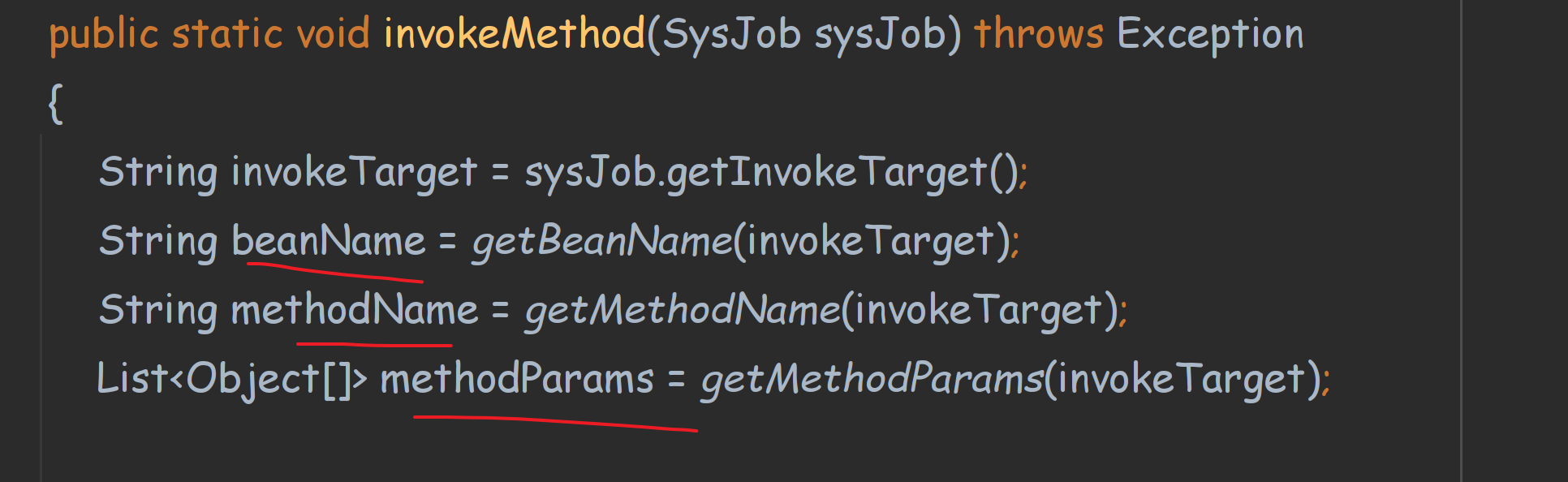
内部通过一个工具类,来反射生成或者获取Task实例。
我们在页面添加任务的时候,需要一个参数:调用方法。

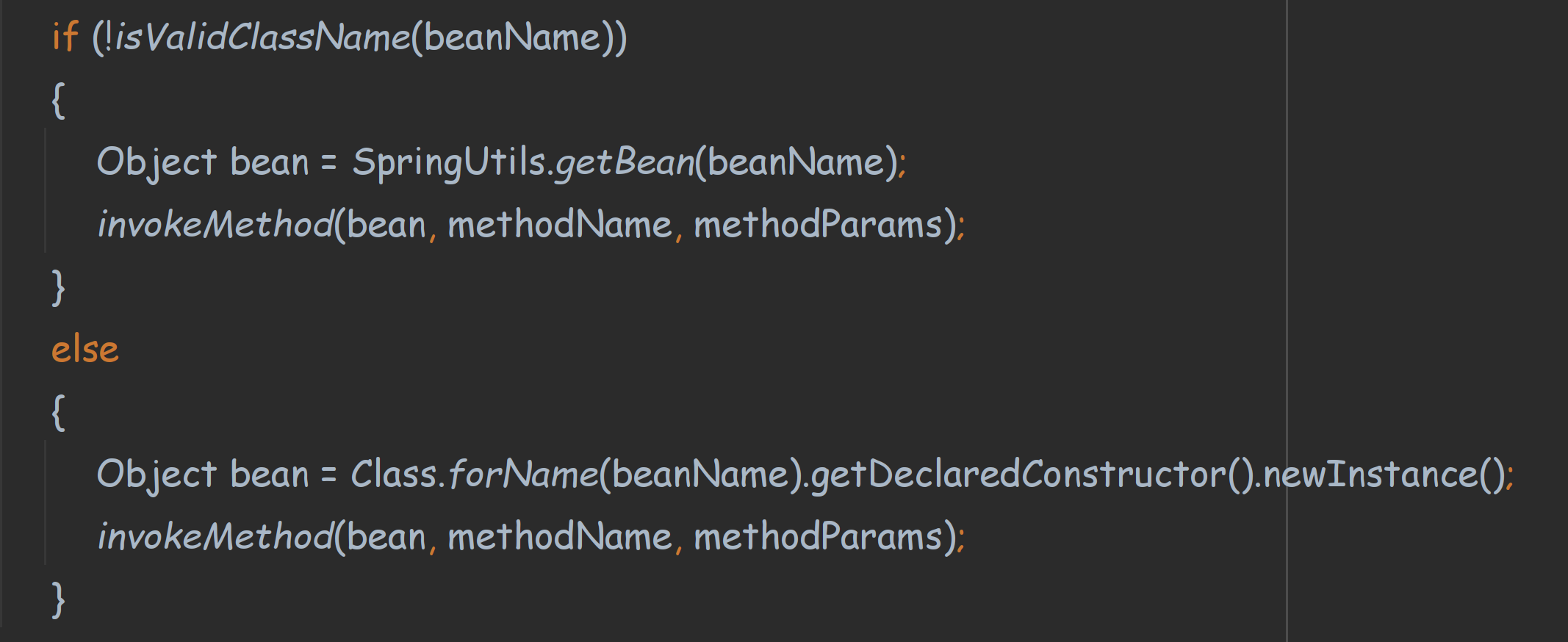
这里有两种方式
1、通过spring容器中,根据beanName来获取Task实例。
2、通过Class.for生成实例。
那么,若依这样的好处在哪里了?
我们创建Job类,里面只能通过execute方法,来执行任务逻辑。
而,若依的这种方式,可以在一个Task中,实现多个方法,通过配置,执行具体的任务方法。
这样,就不用创建太多的Job类和Task类。
并且,把方法参数暴露到配置页,就可以通过不同的参数,实现不同的数据处理任务。
4、若依系统在启动时,怎么初始化所有的任务了?
在com.ruoyi.quartz.service.impl.SysJobServiceImpl#insertJob方法中实现的
通过@PostConstruct注解,在SpringBoot启动时,初始化所有任务。
那么,这个是不是也可以放在监听器里面实现了?
答案是:不可以的
因为这个注解的初始化,是在 Bean 的依赖注入完成后执行初始化逻辑,可以很好的利用spring容器。
避坑:https://blog.youkuaiyun.com/Brave_heart4pzj/article/details/151711468?spm=1001.2014.3001.5502


















 4412
4412

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









