







1 索引的使用原则
既然索引可以提升SQL的查询性能,那是不是给经常使用的查询条件上都建立索引,索引越多越好呢?
1.1 列的离散度
第一个叫做列的离散度,我们先来看一下列的离散度的公式count(distinct(column name)):count(*),列的全部不同值和所有数据行的比例。数据行数相同的情况下,分子越大,列的离散度就越高。
按照这个定义, name 的离散度更高,还是 gender的离散度更高?
简单来说,如果列的重复值越多,离散度就越低,重复值越少,离散度越高。
一般不建议大家在离散度低的字段上建立索引。
建立索引前后根据性别查询数据:
-- 根据性别查询数据
SELECT * FROM `user_innodb` WHERE gender=0;
-- 删除索引
ALTER TABLE user_innodb DROP INDEX idx_user_gender;
-- 创建索引(消耗的时间比较久)
ALTER TABLE user_innodb ADD INDEX idx_user_gender(gender);
-- 根据性别查询数据
SELECT * FROM `user_innodb` WHERE gender=0;
创建索引之后发现,查询的消耗的时间反而更久了。
如果在B+Tree里面的重复值太多,MySQL的优化器发现走索引跟使用全表扫描的时间差不了多少,就算是建立了索引,也不一定会走索引。(MySQL内部有优化器基于成本的原则会选择是否走索引)。
1.2 联合索引最佳左前缀原则
前面我们说的都是针对单列创建的索引,但有的时候我们的多条件查询的时候,也会建立联合索引。单列索引可以看成是特殊的联合索引。
比如我们在 user 表上面,给 name和 phone 建立了一个联合索引。
-- 删除索引
ALTER TABLE user_innodb DROP INDEX idx_name_phone;
-- 创建索引
ALTER TABLE user_innodb ADD INDEX idx_name_phone(name, phone); 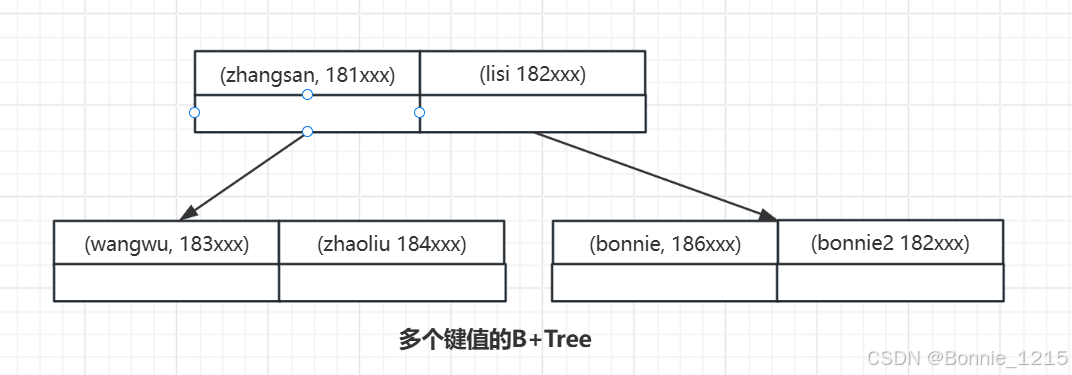
联合索引在 B+Tree 中是复合的数据结构,它是按照从左到右的顺序来建立搜索树的(name 在左边,phone 在右边)
从这张图可以看出来,name是有序的,phone是无序的。当name相等的时候phone 才是有序的。
这个时候我们使用 where name='bonnie' and phone ='186xx'去查询数据的时候B+Tree 会优先比较 name 来确定下一步应该搜索的方向,往左还是往右。如果 name相同的时候再比较 phone。但是如果查询条件没有 name,就不知道第一步应该查哪个节点,因为建立搜索树的时候 name是第一个比较因子,所以用不到索引。
1.2.1 什么时候用到联合索引
比较下面三个语句,看看是否使用了联合索引。
1) 使用两个字段,用到联合索引:
EXPLAIN SELECT * FROM `user_innodb` WHERE name="bonnie" AND phone="15256528888";

2) 使用左边的name字段,用到联合索引:
EXPLAIN SELECT * FROM `user_innodb` WHERE name="bonnie";

3) 使用右边的phone字段,无法使用到索引,全表扫描:
EXPLAIN SELECT * FROM `user_innodb` WHERE phone="15256528888";

1.2.2 如何创建联合索引
有一天发现我们的项目里面有两个查询很慢,按照我们的想法,一个查询建立一个索引,所以我们针对这两条SQL创建了两个索引,着这种做法正确吗?
ALTER TABLE user_innodb ADD INDEX idx_name(name);
ALTER TABLE user_innodb ADD INDEX idx_name_phone(name, phone); 当我们创建一个联合索引的时候,按照最左匹配原则,用左边的字段name去查询的时候,也能用到索引,所以第一个索引(idx_name)完全没必要,
相当于建立了两个联合索引(name),(name,phone)。如果我们创建三个字段的索引index(a,b,c),相当于创建三个索引:
index(a)
index(a,b)
index(a,b,c)
用 where b=?和 where b=?and c=?是不能使用到索引的。
1.3 覆盖索引
回表:
非主键索引,我们先通过索引找到主键索引的键值,再通过主键值查出索引里面没有的数据,它比基于主键索引的查询多扫描了一棵索引树,这个过程就叫回表。
EXPLAIN SELECT * FROM `user_innodb` WHERE name="bonnie";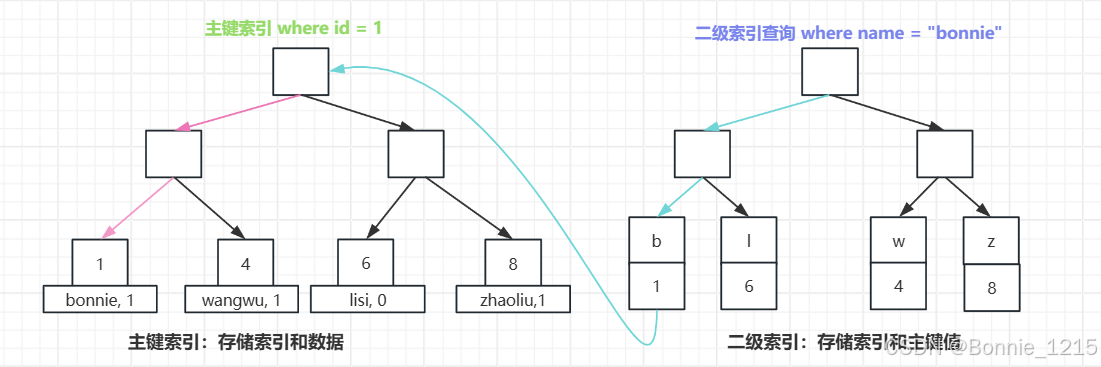 在二级索引里面,不管是单列索引还是联合索引,如果select的数据列只用从索引中就能获取,不必从数据去中读取,这时候使用的索引就叫做覆盖索引,这样就避免了回表。
在二级索引里面,不管是单列索引还是联合索引,如果select的数据列只用从索引中就能获取,不必从数据去中读取,这时候使用的索引就叫做覆盖索引,这样就避免了回表。
-- 删除索引
ALTER TABLE user_innodb DROP INDEX idx_name_phone;
-- 创建联合索引
ALTER TABLE user_innodb ADD INDEX idx_name_phone(name, phone); 使用以下语句查询数据会使用覆盖索引, Extra(Using index)
EXPLAIN SELECT name, phone FROM `user_innodb` WHERE name="bonnie" AND phone="15256528888";
EXPLAIN SELECT name FROM `user_innodb` WHERE name="bonnie" AND phone="15256528888";
EXPLAIN SELECT phone FROM `user_innodb` WHERE name="bonnie" AND phone="15256528888"; 很明显,因为覆盖索引减少了IO次数,减少了数据的访问量,可以大大地提升查询效率。
很明显,因为覆盖索引减少了IO次数,减少了数据的访问量,可以大大地提升查询效率。
1.4 索引条件下推(ICP)
索引条件下推(Index Condition Pushdown),5.6 以后完善的功能。只适用于二级索引。ICP 的目标是减少访问表的完整行的读数量从而减少I/O操作。这里说的下推,其实是意思是把过滤的动作在存储引擎做完,而不需要到 Server 层过滤。
在MySQL的架构中一般存储引擎层对外提供数据的存储以及数据的查询操作,对于数据的过滤操作都是在server层处理,但是索引条件下推表明数据的过滤操作在存储引擎层执行了,减少了向server返回的数据,提升性能。
CREATE TABLE `user_innodb` (
`id` int NOT NULL AUTO_INCREMENT,
`name` varchar(255) COLLATE utf8mb4_unicode_ci DEFAULT NULL,
`gender` tinyint(1) DEFAULT NULL,
`phone` varchar(11) COLLATE utf8mb4_unicode_ci DEFAULT NULL,
`first_name` varchar(255) COLLATE utf8mb4_unicode_ci DEFAULT NULL,
`last_name` varchar(255) COLLATE utf8mb4_unicode_ci DEFAULT NULL,
PRIMARY KEY (`id`) USING BTREE,
KEY `idx_name_phone` (`name`,`phone`)
) ENGINE=InnoDB AUTO_INCREMENT=5 DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_unicode_ci COMMENT='用户表';
ALTER TABLE `user_innodb` ADD INDEX idx_first_last_name(first_name, last_name);
INSERT INTO `youxin_v2`.`user_innodb` (`id`, `name`, `gender`, `phone`, `first_name`, `last_name`) VALUES ('1', 'zhangsan', '1', '18652017511', 'zhang', 'F');
INSERT INTO `youxin_v2`.`user_innodb` (`id`, `name`, `gender`, `phone`, `first_name`, `last_name`) VALUES ('2', 'lisi', '0', '15242412222', 'li', 'F');
INSERT INTO `youxin_v2`.`user_innodb` (`id`, `name`, `gender`, `phone`, `first_name`, `last_name`) VALUES ('3', 'wangwu', '1', '15236584444', 'wang', 'zi');
INSERT INTO `youxin_v2`.`user_innodb` (`id`, `name`, `gender`, `phone`, `first_name`, `last_name`) VALUES ('4', 'bonnie', '1', '15256528888', 'hu', 'F');
INSERT INTO `youxin_v2`.`user_innodb` (`id`, `name`, `gender`, `phone`, `first_name`, `last_name`) VALUES ('5', 'wangwu', '1', '15236584445', 'wang', 'a');
INSERT INTO `youxin_v2`.`user_innodb` (`id`, `name`, `gender`, `phone`, `first_name`, `last_name`) VALUES ('6', 'wangwu', '1', '15236584446', 'wang', 'b');
现在我们要查询所有姓 wang,并且名字最后一个字是zi的员工,比如王胖子,王
瘦子。查询的 SQL:
SELECT * FROM `user_innodb` WHERE first_name="wang" AND last_name="%zi"; 正常情况来说,因为字符是从左往右排序的,当你把%加在前面的时候,是不能基于索引去比较的,所以只有last name(姓)这个字段能够用于索引比较和过滤。
所以查询过程是这样的:
1)根据联合索引查出所有姓 wang的二级索引数据(3 个主键值:6、7、8)
2)回表,到主键索引上查询全部符合条件的数据(3条数据)。
3)把这3条数据返回给 Server层,在 Server 层过滤出名字以zi结尾的员工。

注意,索引的比较是在存储引擎进行的,数据记录的比较,是在 Server层进行的。而当 first name 的条件不能用于索引过滤时,Server 层不会把 first name 的条件传递给存储引擎,所以读取了两条没有必要的记录。
这时候,如果满足 last name='wang'的记录有 10 万条,就会有 99999 条没有必要读取的记录。
所以,根据 first name 字段过滤的动作,能不能在存储引擎层完成呢?这是第二种查询方法:
1)根据联合素引査出所有姓wang 的二级索引数据(3 个主键值:6、7、8)多
2)然后从二级索引中筛选出 first name 以zi结尾的索引(1 个索引)3)然后再回表,到主键索引上查询全部符合条件的数据(1条数据),返回给 Server层。
 很明显,第二种方式到主键索引上查询的数据更少。
很明显,第二种方式到主键索引上查询的数据更少。
ICP 是默认开启的,也就是说针对于二级索引,只要能够把条件下推给存储引擎,它就会下推,不需要我们干预:

set optimizer switch='index_condition_pushdown=on'关闭ICP
set optimizer switch='index_condition_pushdown=off';
查看优化器参数:
SHOW VARIABLES LIKE 'optimizer_switch';

value值如下:
index_merge=on,index_merge_union=on,index_merge_sort_union=on,index_merge_intersection=on,engine_condition_pushdown=on,index_condition_pushdown=on,mrr=on,mrr_cost_based=on,block_nested_loop=on,batched_key_access=off,materialization=on,semijoin=on,loosescan=on,firstmatch=on,duplicateweedout=on,subquery_materialization_cost_based=on,use_index_extensions=on,condition_fanout_filter=on,derived_merge=on,use_invisible_indexes=off,skip_scan=on,hash_join=on,subquery_to_derived=off,prefer_ordering_index=on,hypergraph_optimizer=off,derived_condition_pushdown=on

2 索引创建与失效
2.1 索引创建原则
1、在用于 where 判断 order排序和join的(on)、group by的字段上创建索引
2、索引的个数不要过多。-浪费空间,更新变慢。
3、过长的字段,建立前缀索引。
4、离散度太低,导致扫描行数过多。
5、频繁更新的值,不要作为主键或者索引。一页分裂
6、随机无序的值,不建议作为索引,例如身份证、UUID。--无序,分裂
7、组合索引把散列性高(区分度高)的值放在前面
8、创建复合索引,而不是修改单列索引
2.2 索引失效
1、索引列上使用函数(count sum avg)、表达式(+ - * /)
2、字符串不加引号,出现隐式转换
3、like条件中前面带%
4、负向查询 (NOT LIke) ( !=) ( NOT IN)


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









