






向量(Vector)是数学和计算机科学中的基本概念,指具有大小(长度)和方向的量。在机器学习和数据科学中,向量通常表示为一组有序的数字,用于描述对象的特征。以下是详细解析:
1)向量的数学表示
几何意义:在二维或三维空间中,向量可以画成带箭头的线段,箭头指向方向,长度表示大小。
示例:二维向量 (3, 4) 在坐标系中的表示
数学形式:向量是一维数组,包含 n 个数值(称为维度)。
二维向量:[x, y]
三维向量:[x, y, z]
n 维向量:[v₁, v₂, ..., vₙ]
2)向量在计算机中的应用
(1)特征表示
在机器学习中,对象(如文本、图像、用户行为)被转换为特征向量,以便计算机处理。
示例:
图像的向量:通过 CNN 提取的 512 维特征 [0.1, 0.7, ..., -0.2]
文本的向量:通过 BERT 生成的 768 维嵌入 [0.3, -0.5, ..., 0.9]
(2)相似性计算
通过向量距离(如欧式距离、余弦相似度)衡量对象之间的相似性。
欧式距离:向量间的直线距离,越小越相似。
python
import numpy as np
v1 = np.array([1, 2, 3])
v2 = np.array([4, 5, 6])
distance = np.linalg.norm(v1 - v2) # 输出 5.196(欧式距离)
余弦相似度:向量方向的夹角余弦值,越接近 1 越相似。
python
from sklearn.metrics.pairwise import cosine_similarity
similarity = cosine_similarity([v1], [v2]) # 输出 0.974(余弦相似度)
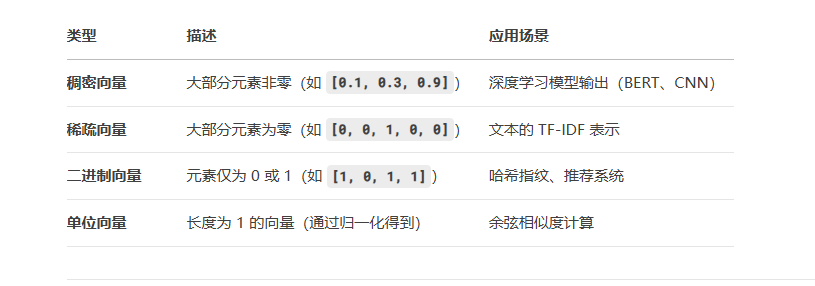
3)向量的常见类型
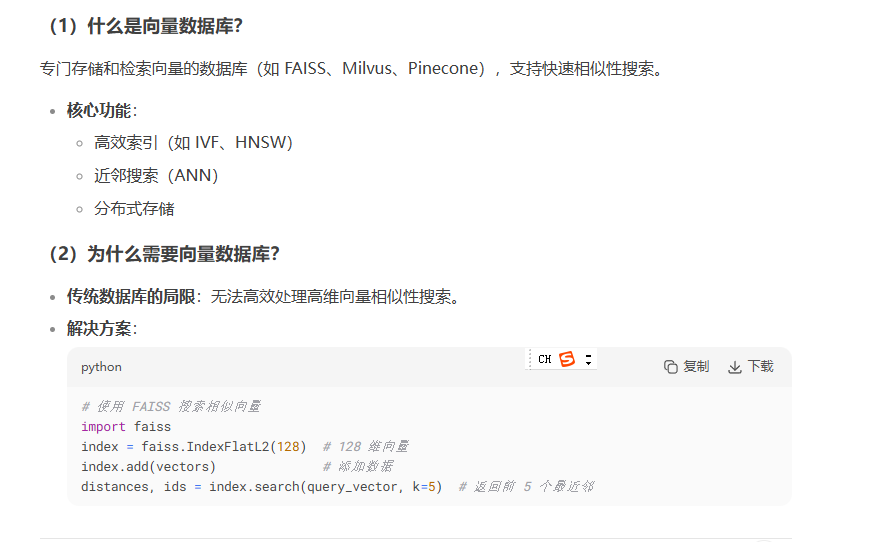
4)向量数据库与检索
5)实战示例
(1)文本相似度搜索
from sentence_transformers import SentenceTransformer
import faiss
# 生成文本向量
model = SentenceTransformer('all-MiniLM-L6-v2')
texts = ["猫", "狗", "汽车"]
embeddings = model.encode(texts)
# 构建 FAISS 索引
index = faiss.IndexFlatL2(embeddings.shape[1])
index.add(embeddings)
# 搜索相似文本
query = model.encode("动物")
distances, ids = index.search(query.reshape(1, -1), k=2)
print("相似文本:", [texts[i] for i in ids[0]]) # 输出 ["狗", "猫"]
(2)图像检索
import torchvision.models as models
import torch
# 提取图像特征
model = models.resnet18(pretrained=True).eval()
image_tensor = torch.randn(1, 3, 224, 224) # 假设输入图像
feature_vector = model(image_tensor).detach().numpy()
# 存储和检索(伪代码)
database.add(feature_vector)
results = database.search(query_feature)

















 5912
5912

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









