




 本文详细介绍了MapJoin和ReduceJoin在大数据处理中的使用。MapJoin适用于小表与大表的联合,直接在Map阶段完成连接操作;而ReduceJoin适合处理两张大表的联合,通过定义Bean对象、Map和Reduce类实现。文中通过具体实例展示了两种方法的执行过程和结果,有助于理解这两种Join方法的工作原理。
本文详细介绍了MapJoin和ReduceJoin在大数据处理中的使用。MapJoin适用于小表与大表的联合,直接在Map阶段完成连接操作;而ReduceJoin适合处理两张大表的联合,通过定义Bean对象、Map和Reduce类实现。文中通过具体实例展示了两种方法的执行过程和结果,有助于理解这两种Join方法的工作原理。
产品表:
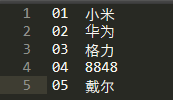
订单表:
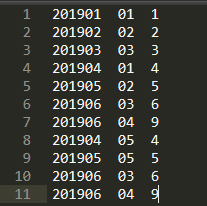
需求:通过产品表和订单表得到,数据为(2019 01 小米 1)的表。
一、MapJoin
MapJoin适合小表+大表的联合。
1、Map类直接进行join操作
package com.join.mapjoin;
import org.apache.commons.lang.StringUtils;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.BufferedReader;
import java.io.FileInputStream;
import java.io.IOException;
import java.io.InputStreamReader;
import java.util.HashMap;
public class MapJoin extends Mapper<LongWritable, Text, Text, NullWritable> {
//定义HashMap对象存储小表对象
HashMap hashMap = new HashMap<String, String>();
/**
* 将小表加载到内存中
* @param context
* @throws IOException
* @throws InterruptedException
*/
@Override
protected void setup(Context context) throws IOException, InterruptedException {
//获取缓存的文件
BufferedReader reader = new BufferedReader(new InputStreamReader(new FileInputStream("D:\\Bigdata\\product.txt"), "UTF-8"));
//按行读取数据
String line;
while (StringUtils.isNotEmpty(line=reader.readLine())){
//切分小表行数据
String[] split = line.split("\t");
//数据存储进HashMap集合
hashMap.put(split[0], split[1]);
}
}
/**
* Map方法
* @param key
* @param value
* @param context
* @throws IOException
* @throws InterruptedException
*/
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
//获取大表数据
String line = value.toString();
//切分
String[] fields = line.split("\t");
//按照productId关联
String productId = fields[1];
if (hashMap.containsKey(productId)) {
context.write(new Text(fields[0].substring(0, 4) + "\t" + fields[0].substring(4)
+ "\t" + hashMap.get(productId) + "\t" + fields[2]), NullWritable.get());
}
}
}
2、驱动程序
package com.join.mapjoin;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 273
273

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









