




 本文介绍了计算机的基础构成,包括CPU、RAM、永久存储器和外围设备,阐述了CPU如何执行指令。接着讲解了C语言编程的七个步骤,从定义目标到维护程序,并详细描述了编译和链接过程。在Linux环境下,讨论了C程序的编辑、编译和运行。文章强调了源代码、目标代码和可执行文件的区别,并提供了Linux下C程序的实例。
本文介绍了计算机的基础构成,包括CPU、RAM、永久存储器和外围设备,阐述了CPU如何执行指令。接着讲解了C语言编程的七个步骤,从定义目标到维护程序,并详细描述了编译和链接过程。在Linux环境下,讨论了C程序的编辑、编译和运行。文章强调了源代码、目标代码和可执行文件的区别,并提供了Linux下C程序的实例。
1.扫盲
1.1计算机工作的基本原理
1.计算机的几个部件
| 名称 | 功能 |
|---|---|
| 中央处理器(CPU) | 担负着绝大部分的计算工作 |
| 随机访问存储器(RAM) | 作为一个工作区来保护程序和文件 |
| 永久存储器 | 一般是硬盘,即使在计算机关机时也能记下程序 |
| 各种外围设备 | 如键盘、鼠标、监视器,用来提供人与计算机之间的通信 |
2.CPU简单的工作内容
-
CPU从内存获取一个指令并执行这个指令,然后从内存中获取下一个指令并执行。一个千兆CPU可以在一秒内进行大约一亿次这样的操作,所以CPU能以惊人的速度来从事其枯燥的工作。
-
CPU有自己的小工作区,该工作区由若干个寄存器(registers)组成,每个寄存器可以保存一个数。 一个寄存器保存下一条指令的内存内存地址,CPU使用该信息获取下一条指令。 获取一条指令后,CPU在另一个寄存器中保存该指令并将第一个寄存器的值更新为下一条指令的地址。
-
CPU只能理解有限的指令(指令集)。这些指令是相当具体的,其中许多指令要求计算机将一个数从一个位置移动到另一个位置,例如,从内存单元移到寄存器。
-
所以,当您需要计算机做某件事时,就必须提供一个特定的指令列表(一套程序)确切的告诉计算机要做的事及如何去做。这是一项繁琐、乏味、费力的任务。即使将两个数字想加这样简单的事,也必须被分解成若干个步骤:
- (1) 将内存单元为2000中的数字复制到寄存器1。
- (2)将内存单元为2004中的数字复制到寄存器2。
- (3)将寄存器 2 的内容加到寄存器 1 的内容上,答案保留在寄存器 1 中。
- (4)将寄存器 1 的内容复制到内存单元 2008。
- 你必须用数字来表示这些指令中的每一个!
- 太麻烦了~
_ 存储在计算机中的一切内容都是数字。数字是以数字形式存储的,字符(如文本文档中使用的字母字符)也是以数字形式存储的,每个字符有一个数字代码。_
1.2 使用C语言的7个步骤
- 定义程序目标
- 设计程序
- 编写代码
- 编译
- 运行程序
- 测试和调试程序
- 维护和修改程序
1.2.1 第1步:定义程序目标
- 也就是在开始的时候,您对希望程序做什么有一个清晰的想法。考虑:
1.程序需要的信息
2.程序需要的计算和操作
3.程序应该向您报告的信息 - 这一规划阶段,您应该用一般概念来考虑问题,而不是用一些具体的计算机语言术语来考虑。
1.2.2 第2步:设计程序
- 完成上一步以后,您就可以决定程序如何完成它:
用户界面应该是什么样
程序应该如何组织
目标用户是谁
您有多长时间来完成它
在程序中(也可能在辅助文件中)如何表示数据,以及用什么方法来处理数据
1.2.3 第3步:编写代码
- 在程序有了清晰的设计以后,就可以通过代码来 实现它了。
- 一般来说,需要使用文本编辑器来创建 一种称为源代码的文件。此文件,包含程序设计的C实现形式。
- 如以下代码:
# include <stdio.h>
int main(void)
{
int dogs;
printf(How many dogs do you have?\n);
scanf("%d", &dogs);
printf("So you have %d dog (s) !\n", dogs);
return 0;
}
- 作为这一步的一部分,应该给所编写的程序添加文字注视。最简单的方式是使用 C 的注释工具向代码中加入解释。
1.2.4 第4步:编译
- 下一个步骤是编译源代码,编译细节也取决于编程环境。
- 编译器是一个程序,其工作是将源代码转换为可执行代码。
- 可执行代码是用计算机的本机语言会机器语言表示的代码。这种语言是由数字代码表示的详细指令组成。
- 不同的计算机具有不同的机器语言,C编译器用来将C语言转换成特定的机器语言。
- C编译器还从C的库中向最终程序加入代码。库中包含着许多标准例程供使用,例如 printf( ) 和 scanf( )。(更准确地说,是一个被称为连接器(linker)的程序将库例程引入的,但在多数系统上,编译器为您运行链接器。)
- 最后的结果是,形成一个包含计算机可以理解的代码并且您能够运行的可执行文件。
- 编译器还检查您的程序是否为有效的C语言程序。如果编译器发现错误,就将错误报告给您,而且不生成可执行文件。
1.2.5 第5步:运行程序
- 传统上讲,可执行文件是您可以运行的一个程序。
- 很多公用环境(MS-DOS、Unix、Linux控制台)中,想运行程序,只需要键入响应的可执行文件名即可。
- 在其他环境,例如VAX上的VMS可能需要一个运行命令会一些其他机制。
1.2.6 第6步:测试和调试程序
- 程序可以运行是一个好现象,但有可能它运行的不正确。
- 因此,应该进行检查,看程序是否在做要做的事情。可能会发现一些程序有错误,在计算机行话中称之为bug。
- 调试(Debugging)就是要发现并修正程序错误。
1.2.7 第7步:维护和修改程序
- 在为自己或为别人创建程序时,该程序可能会更广泛的应用。如果是这样,您可能会发现需要对其进行更改。
- 如果对程序作了清除的文字注释并采取良好的设计做法,则所有这些任务都会大大简化。
1.3 编程机制
- 编写程序时,必须遵循的确切步骤取决于您的计算机环境。因为C是可移植的,所以它在许多环境中可用。
- 用C语言编写一个程序时,要将编写的内容保存在一个被称为源代码的文本文件中。大多数C系统,都需要该文件的名字以 .c 结尾,例如 worldcount.c 和 budget.c 。名称中小点前的部分被称为基本名,小点后的部分被称为扩展名。因此, budget 是一个基本名,c 是一个扩展名。组合在一起的 budget.c 是文件名。
- 源代码的文件名,还应满足特定计算机操作系统的需求。如:
| 操作系统 | 要求 |
|---|---|
| MS-DOS | 是IBM PC及其兼容机的操作系统,要求基本名不能大于8个字符长。 |
| 一些Unix系统 | 对整个文件名长度、包括扩展名在内,有14个字符的限制 |
| 其他的Unix系统 | 如Linux、Windows、Macintosh OS ,允许更长的文件名,最长为255个字符。 |
- 这样在我们提到名字的时候就可以更具体,我们假定一个名为 concrete.c 的源文件,其中包含程序源代码如下:
#include <stduo.h>
int main(void)
{
printf("Concrete contains gravel and cement. \n");
return 0;
}
1.3.1 目标代码文件、可执行文件和库
- C 编程的基本策略是使用程序将源代码文件转换为可执行文件,此文件包含可以运行的机器语言代码。
- C 分两步完成这一工作:
- 编译 :编译器将源代码转换为中间代码。
- 链接 :链接器将此中间代码与其他代码相结合来生成可执行文件。
- C 使用被划分为两部分,这一使用使程序便于模块化。您可以分别编译各个模块。同时链接器将您的程序与预编译的库代码结合起来。
- 中间文件的形式有多重选择。最一般的选择,同时也是下面会采用的选择,是将源代码转为机器语言代码,将结果放置在一个目标码文件(或简称为目标文件)中(这里假定您的源代码由单个文件组成)。虽然目标文件包含机器语言代码,但是该文件还不能运行。目标文件包含源代码的转换结果,它还不是一个完整的程序。
- 目标代码文件中所缺少的第一个元素是一种叫启动代码(start-up code)的东西,此代码相当于您程序和操作系统之间的接口。
- 所缺少的第二个元素是库例程的代码。几乎所有的 C 程序都利用准 C 库中所包含的例程(称为函数)。 例如,前面的 concrete.c 使用了函数printf()。目标代码文件不包含这一函数的代码,它只包含声明使用 printf() 函数的指令。实际代码存储在另一个称为“库”的文件中。库文件中包含许多函数的目标代码。
- 链接器的作用就是将这三个元素(目标代码、系统的标准启动代码和库代码)结合在一起。对库代码而言,链接器只是从库中提取您所使用的函数需要的代码(如下图所示)。
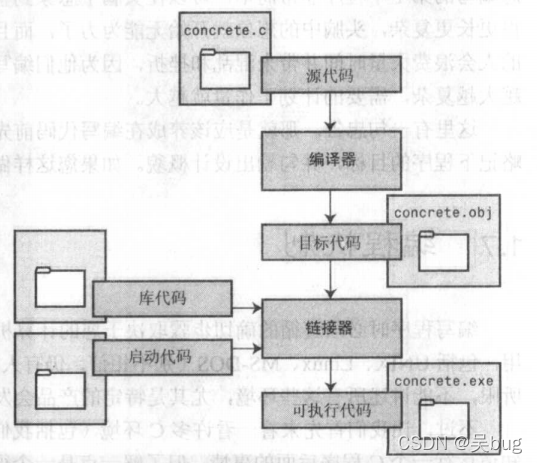
- 简而言之,目标文件和可执行文件都是由机器语言指令组成的。
标文件:只包含您所编写的代码转换成的机器语言。
可执行文件:包含所使用的库例程以及启动代码的机器代码。
- 在一些系统上,必须分别运行编译和链接程序。在另一些系统上,编译器可以自动启动链接器,所以只须给出编译命令即可。
1.3.2 Linux系统
- 现在大部分企业的服务器是Linux环境,接下来讲下Linux系统 C 的编译过程。
一、在Linux系统上编辑
- Linux C不具备自己的编辑器,可以用vi/vim等文件编辑器。
- 编辑程序的文件名,应以 .c 结尾,不能使用 .C。
- Linux区分大小写。
- 使用 vi 编辑器,可以编写下面的程序并将其存储在名为 inform.c 的文件中。
#include <stdio.h>
int main(void)
{
printf("A.c is used to end a C program filename.\n");
return 0;
}
此段文本是源代码,inform.c 是源文件。此处的要点是,源文件是过程的开始,不是结束。
二、在Linux系统上编译
- 计算机不理解诸如 #include 或 printf 这样的东西,需要编译器将我们的代码(源代码)转换为计算机的代码(机器代码)。这些工作的结果是形成可执行文件,其中包含计算机完成任务所需的所有机器代码。
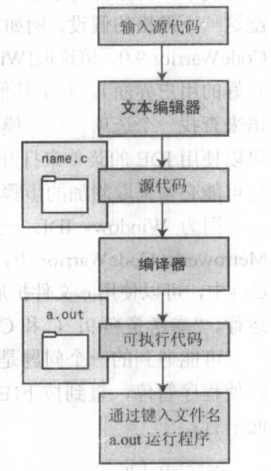
- Linux 使用由 GNU 提供的被称为 gcc 的公共域 C 编辑器,来编译 inform.c 程序。
注意,在安装Linux时,gcc 的安装可能是可选项,所以,如果原理没有安装 gcc ,必须先进行安装。一般情况下,安装的过程会将 cc 作为 gcc 的别名 ,所以如果愿意,可以在命令行使用 cc 而不是 gcc。
- 编译 inform.c 需要键入下列内容:
wudan@uos:~/c$ ls
inform.c
wudan@uos:~/c$ gcc inform.c
wudan@uos:~/c$ ls
a.out inform.c
- 如上所示,执行完成后,会出现名为 a.out 的新文件,它是包含程序转换(或编译)结果的可执行文件。要运行该文件,如下操作:
wudan@uos:~/c$ ./a.out
A.c is used to end a C program filename.
- 如果想保存该可执行文件(a.out),就必须对其进行重命名。否则,该文件会被下一次编译程序时产生的一个新的 a.out 替代。
- gcc 编辑器创建一个与源代码具有相同基本名但扩展名为 .o 的目标代码文件。本例中,目标代码文件名为 inform.o,但您却找不到这个文件,因为链接器在可执行程序被生成后,将该文件删除。然而,如果原始程序使用多个源代码文件,则会保存目标代码文件。后面会讨论多文件程序。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









