




【NebulaGraph】深入了解查询语句
- 1. NebulaGraph 查询语句概述
- 2. GO查询语句
- 2.1 GO语法
- 2.1.1 遍历深度 `[[<M> TO] <N> {STEP|STEPS}]`
- 2.1.2 起始顶点 `FROM <vertex_list>`
- 2.1.3 变类型 `OVER <edge_type_list>`
- 2.1.4 条件过滤`WHERE <conditions>`
- 2.1.5 返回值 `YIELD [DISTINCT] <return_list>`
- 2.1.6 采样 `SAMPLE <sample_list>`
- 2.1.7 分组与聚合 `GROUP BY {<col_name> | expression | <position>} YIELD <col_name>`
- 2.1.8 排序 `ORDER BY <expression> [{ASC | DESC}]`
- 2.1.9 限制结果 `LIMIT n , m`
- 2.1.10 查询示例
- 2.2 补充GO语法查询例子
- 在这里插入图片描述
- 3. MATCH语句
- 4. 查询中一些结果说明
1. NebulaGraph 查询语句概述
NebulaGraph 的数据以点和边的形式存储。每个点可以有 0 或多个标签(Tag);每条边有且仅有一个边类型(Edge Type)。标签定义点的类型以及描述点的属性;边类型定义边的类型以及描述边的属性。在查询时,可以通过指定点的标签或边的类型来限定查询的范围。
查询语句分类
NebulaGraph 的核心查询语句可分为:
- FETCH PROP ON
- LOOKUP ON
- GO
- MATCH
- FIND PATH
- GET SUBGRAPH
- SHOW
FETCH PROP ON和LOOKUP ON更多用于基础的数据查询;
GO和MATCH用于更复杂的查询和图数据遍历;
FIND PATH和GET SUBGRAPH用于图数据的路径查询和子图查询;
SHOW用于获取数据库的元数据信息。
2. GO查询语句
GO查询手册: https://docs.nebula-graph.com.cn/3.8.0/3.ngql-guide/7.general-query-statements/3.go/
用法:用于基于给定的点进行图遍历,按需返回起始点、边或目标点的信息。可以指定遍历的深度、边的类型、方向等。
场景:复杂的图遍历,比如找到某个点的朋友、朋友的朋友等。
说明:
结合属性引用符($^和$$)来返回起始点或目标点的属性,例如YIELD $^.player.name。
结合函数properties($^)和properties($$)来返回起始点或目标点的所有属性;或者在函数中指定属性名,来返回指定的属性,例如YIELD properties($^).name。
结合函数src(edge)和dst(edge)来返回边的起始点或目标点 ID,例如YIELD src(edge)。
GO 3 STEPS FROM "player102" OVER follow YIELD dst(edge);
-----+--- --+------- -+---- ---+-----
| | | |
| | | |
| | | +--------- 返回最后一跳边的终点
| | |
| | +------ 从 follow 这个边的出方向探索
| |
| +--------------------- 起点是 "player102"
|
+---------------------------------- 探索 3 步
2.1 GO语法
GO [[<M> TO] <N> {STEP|STEPS} ] FROM <vertex_list>
OVER <edge_type_list> [{REVERSELY | BIDIRECT}]
[ WHERE <conditions> ]
YIELD [DISTINCT] <return_list>
[{ SAMPLE <sample_list> | <limit_by_list_clause> }]
[| GROUP BY {<col_name> | expression> | <position>} YIELD <col_name>]
[| ORDER BY <expression> [{ASC | DESC}]]
[| LIMIT [<offset>,] <number_rows>];
<vertex_list> ::=
<vid> [, <vid> ...]
<edge_type_list> ::=
<edge_type> [, <edge_type> ...]
| *
<return_list> ::=
<col_name> [AS <col_alias>] [, <col_name> [AS <col_alias>] ...]
GO 是 NebulaGraph 中的一个核心语法,用于实现遍历查询。通过指定起始顶点、边类型和其他条件,可以查询图中的邻居信息、路径关系或属性值。以下是对其语法结构的详细介绍:
2.1.1 遍历深度 [[<M> TO] <N> {STEP|STEPS}]
- 指定遍历的深度。
<M>和<N>定义步数范围,M 是起始步,N 是结束步。- 如果只指定
<N>,表示单步遍历深度为 N。 - 例子:
- GO 2 STEPS:表示两步遍历。
- GO 1 TO 3 STEPS:表示从 1 步到 3 步的范围遍历。
2.1.2 起始顶点 FROM <vertex_list>
- 指定遍历的起点。
<vertex_list>是顶点 ID 的列表。- 例子
FROM "player1", "player2"
2.1.3 变类型 OVER <edge_type_list>
- 指定需要遍历的边的类型。
- 可以列出多个边类型,用逗号分隔。
- 如果使用
*,表示遍历所有边类型。 - 修饰符:
- REVERSELY:按边的反方向遍历。
- BIDIRECT:按边的双向遍历。
- 例子
OVER follow, teammate REVERSELY
2.1.4 条件过滤WHERE <conditions>
- 使用 WHERE 子句过滤遍历结果,支持条件表达式。
- 常见条件包括:属性值、比较操作符(=、>、< 等)以及逻辑操作符(AND、OR、NOT)。
- 例子
WHERE follow.degree > 5 AND teammate.rank == 1
2.1.5 返回值 YIELD [DISTINCT] <return_list>
- 指定查询返回的字段,可以是顶点、边的属性,或表达式结果。
DISTINCT:去除重复值。- 例子
YIELD follow.degree AS degree, src(edge), dst(edge)
2.1.6 采样 SAMPLE <sample_list>
- 从查询结果中随机抽样指定数量的顶点或边
- 例子
SAMPLE 5
2.1.7 分组与聚合 GROUP BY {<col_name> | expression | <position>} YIELD <col_name>
- 对查询结果进行分组,并计算聚合值(如 COUNT、SUM 等)。
- 例子:
GROUP BY follow.degree YIELD COUNT(*), MAX(follow.rank)
2.1.8 排序 ORDER BY <expression> [{ASC | DESC}]
ORDER BY follow.rank DESC
2.1.9 限制结果 LIMIT n , m
2.1.10 查询示例
示例1:简单遍历
从顶点 player100 开始,沿 follow 边遍历 1 步,返回目标顶点 ID。
GO 1 STEP FROM "player100" OVER follow YIELD dst(edge) AS friend_id;
示例 2:条件过滤
从 player100 出发,沿 follow 边遍历 2 步,过滤 degree > 3 的边,并返回目标顶点和边的 degree 属性。
GO 2 STEPS FROM "player100" OVER follow WHERE follow.degree > 3
YIELD dst(edge), follow.degree;
示例 3:多边类型与方向
从 player100 出发,沿 follow 和 teammate 边反向遍历 3 步,返回边的起点、终点及类型。
GO 3 STEPS FROM "player100" OVER follow, teammate REVERSELY
YIELD src(edge), dst(edge), type(edge);
示例 4:分组聚合
按 degree 聚合,统计每个 degree 出现的次数。
GO 1 STEP FROM "player100" OVER follow
GROUP BY follow.degree
YIELD follow.degree AS degree, COUNT(*) AS count;
示例 5:排序与分页
从 player100 出发,沿 follow 边遍历 1 步,根据 degree 倒序排列,返回前 10 条记录。
GO 1 STEP FROM "player100" OVER follow
ORDER BY follow.degree DESC
LIMIT 10;
2.2 补充GO语法查询例子
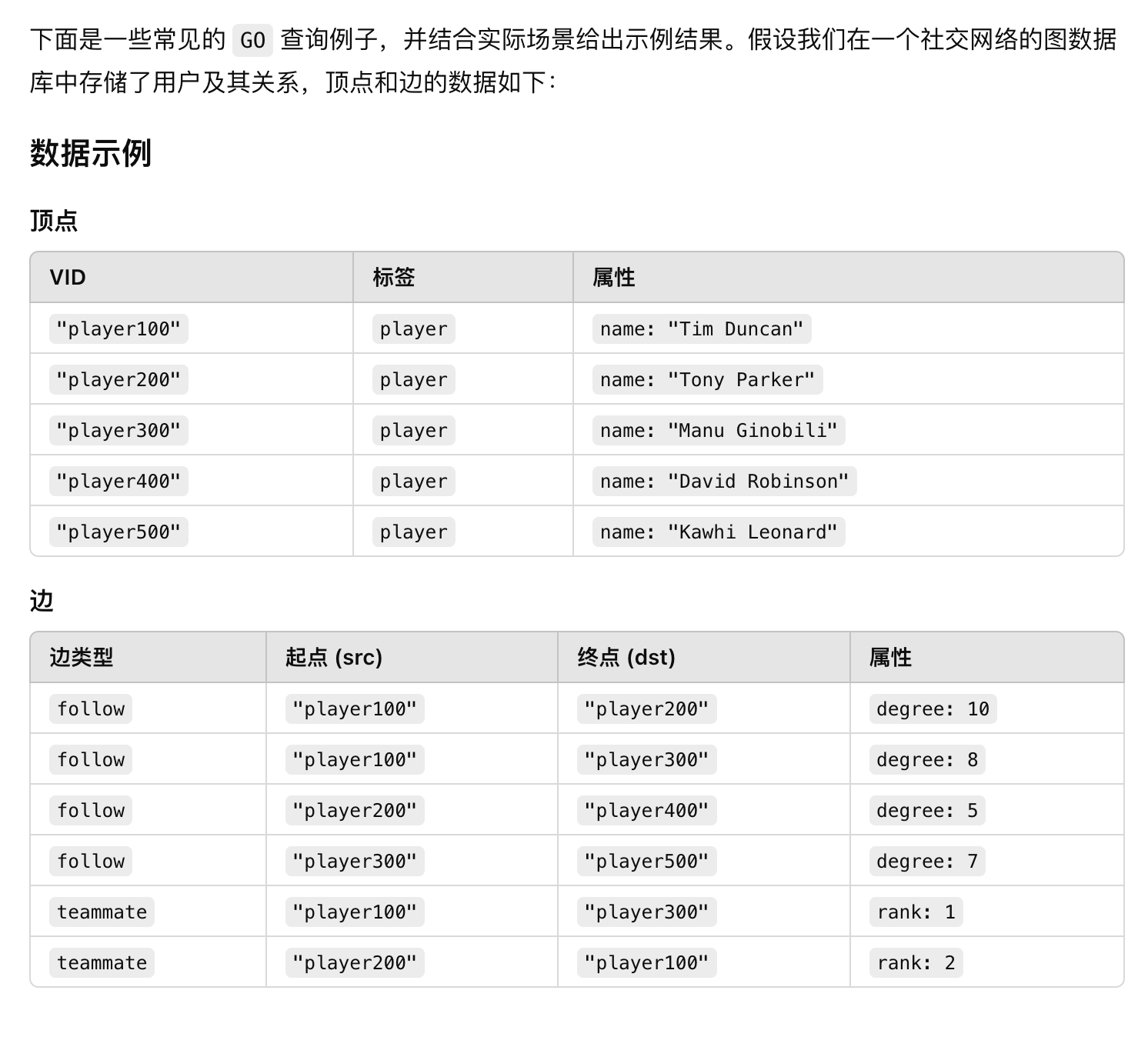
示例 1:获取某个顶点的直接邻居
GO 1 STEP FROM "player100" OVER follow
YIELD dst(edge) AS neighbor_id, follow.degree AS strength;
示例 2:多步遍历
GO 2 STEPS FROM "player100" OVER follow
YIELD dst(edge) AS neighbor_id, follow.degree AS strength;

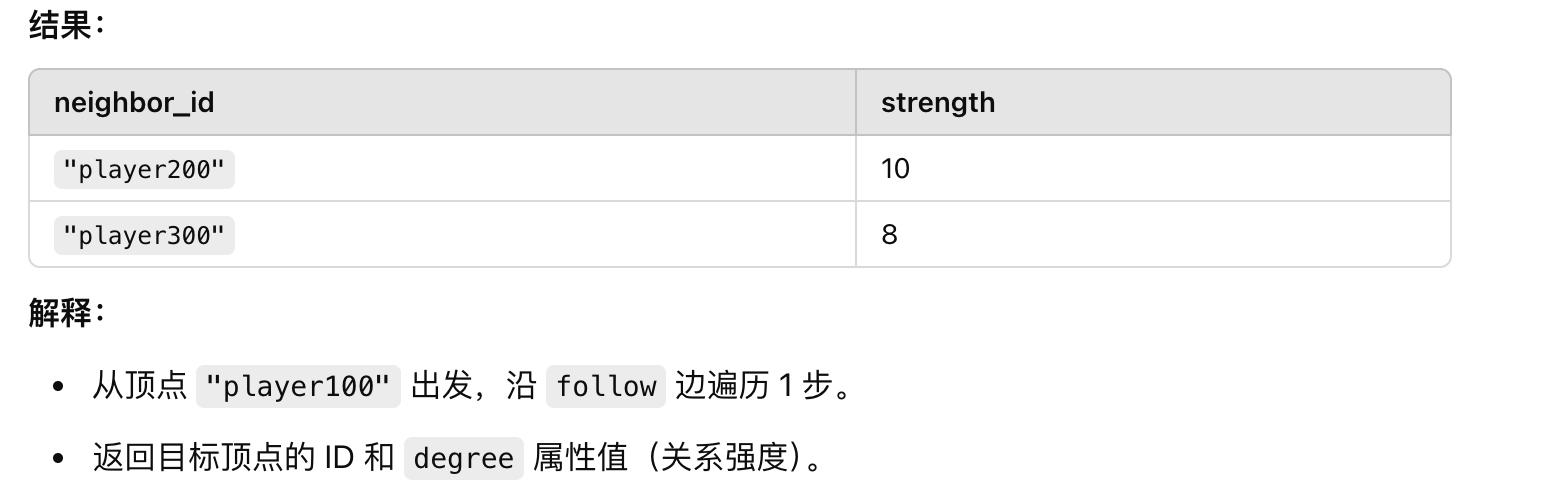
从 "player100" 出发,沿 follow 边,查询 1 步到 4 步范围内的所有目标顶点。
返回每条边目标顶点的 ID (neighbor_id)。
返回边的 degree 属性值 (strength)。
GO 1 TO 4 STEPS FROM "player100" OVER follow
YIELD dst(edge) AS neighbor_id, follow.degree AS strength;
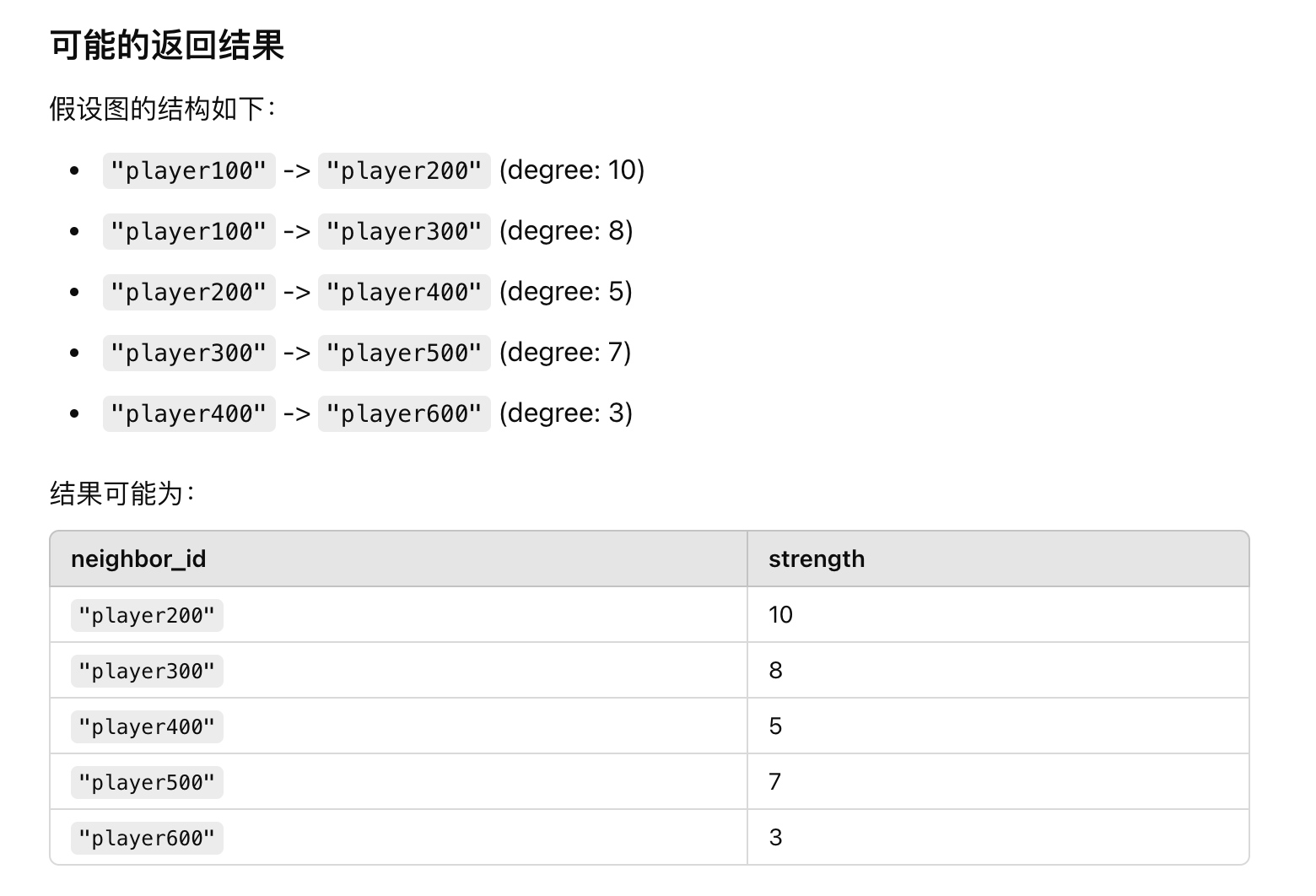
示例 3:带条件过滤
GO 1 STEP FROM "player100" OVER follow
WHERE follow.degree > 8
YIELD dst(edge) AS neighbor_id, follow.degree AS strength;

示例 4:指定边方向
GO 1 STEP FROM "player100" OVER teammate REVERSELY
YIELD src(edge) AS teammate_id, teammate.rank AS team_rank;

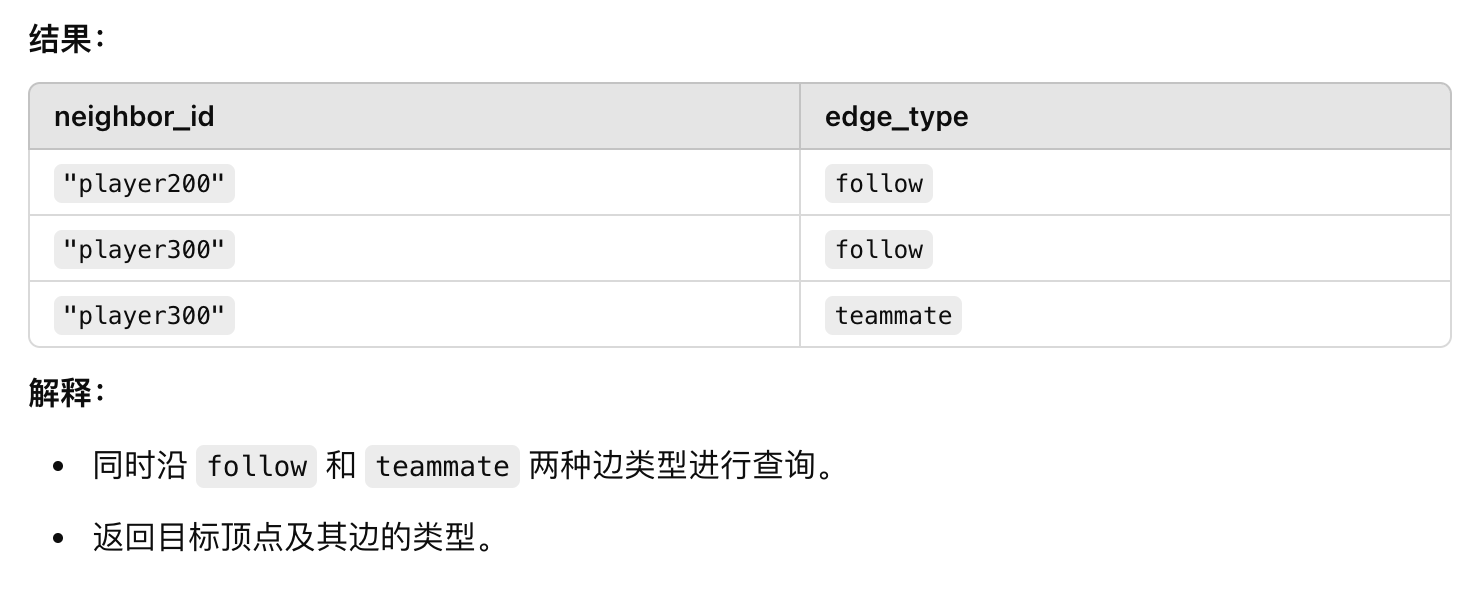
示例 5:多边类型的遍历
GO 1 STEP FROM "player100" OVER follow, teammate
YIELD dst(edge) AS neighbor_id, type(edge) AS edge_type;
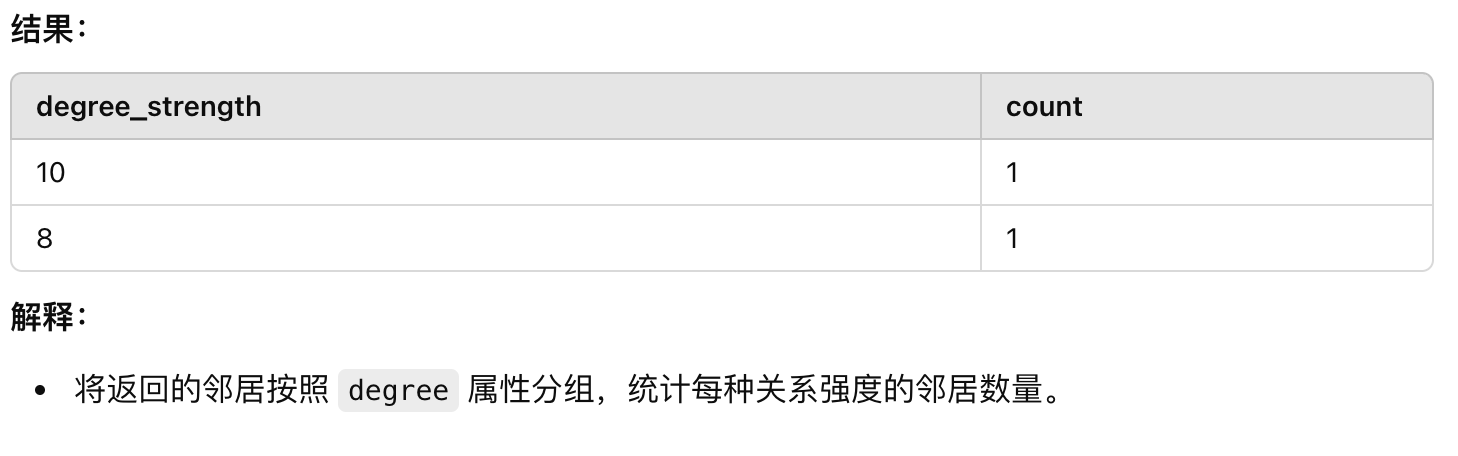
示例 6:分组统计
GO 1 STEP FROM "player100" OVER follow
GROUP BY follow.degree
YIELD follow.degree AS degree_strength, COUNT(*) AS count;
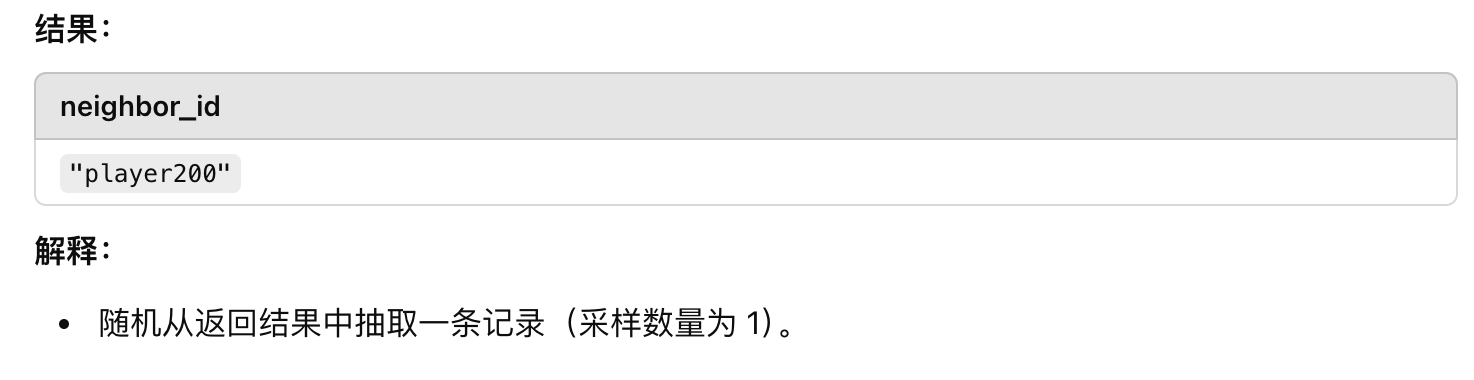
示例 7:随机采样
GO 1 STEP FROM "player100" OVER follow
SAMPLE 1
YIELD dst(edge) AS neighbor_id;
示例 8:分页查询
GO 1 STEP FROM "player100" OVER follow
ORDER BY follow.degree DESC
LIMIT 1;

示例 9:复杂查询组合
GO 2 STEPS FROM "player100" OVER follow
WHERE follow.degree > 5
YIELD src(edge) AS src_id, dst(edge) AS dst_id, follow.degree AS strength
| ORDER BY strength DESC
LIMIT 2;

3. MATCH语句
MATCH语句提供基于模式(Pattern)匹配的搜索功能,其通过定义一个或多个模式,允许在 NebulaGraph 中查找与模式匹配的数据。在检索到匹配的数据后,用户可以使用 RETURN 子句将其作为结果返回。
文档 https://docs.nebula-graph.com.cn/3.8.0/3.ngql-guide/7.general-query-statements/2.match/
3.1 MATCH语法
MATCH语句的语法相较于其他查询语句(如GO和LOOKUP)更具灵活性。在进行查询时,MATCH语句使用的路径类型是trail,这意味着点可以重复出现,但边不能重复。
MATCH语法的基本结构如下:
MATCH <pattern> [<clause_1>] RETURN <output> [<clause_2>];
pattern:MATCH语句支持匹配一个或多个模式,多个模式之间用英文逗号(,)分隔。例如(a)-[]->(b),(c)-[]->(d)。Pattern 的详细说明请参见模式。clause_1:支持WHERE、WITH、UNWIND、OPTIONAL MATCH子句,也可以使用MATCH作为子句。output:定义需要返回输出结果的列表名称。可以使用AS设置列表的别名。clause_2:支持ORDER BY、LIMIT子句。
注意: 从 3.5.0 版本开始,MATCH语句支持全表扫描,即在不使用任何索引或者过滤条件的情况下可遍历图中点或边。在此之前的版本中,MATCH 语句在某些情况下需要索引才能执行查询或者需要使用LIMIT限制输出结果数量。
使用说明
- 尽量避免执行全表扫描,因为这可能导致查询性能下降;并且如果在进行全表扫描时内存不足,可能会导致查询失败,系统会提示报错。建议使用具有过滤条件或指定 Tag、边类型的查询,例如
MATCH (v:player) RETURN v.player.name AS Name语句中的v:player和v.player.name。 - 可为 Tag、Edge type 或 Tag、Edge type 的某个属性创建索引,以提高查询性能。例如,用户可以为player Tag 创建索引,或者为player Tag 的name属性创建索引。有关索引的使用及注意事项,请参见使用索引必读。
- 目前 MATCH 语句无法查询到悬挂边。
3.1.1 模式
模式文档: https://docs.nebula-graph.com.cn/3.8.0/3.ngql-guide/1.nGQL-overview/3.graph-patterns/
模式(pattern)和图模式匹配,是图查询语言的核心功能,本文介绍 NebulaGraph 设计的各种模式,部分还未实现。
-
单点模式: 点用一对括号来描述,通常包含一个名称。例如:
(a),示例为一个简单的模式,描述了单个点,并使用变量a命名该点。 -
多点关联模式:

-
Tag 模式:

-
属性模式
点和边是图的基本结构。nGQL 在这两种结构上都可以增加属性,方便实现更丰富的模型。
在模式中,属性的表示方式为:用花括号括起一些键值对,用英文逗号分隔,并且需要指定属性所属的 Tag 或者 Edge type。
例如一个点有两个属性:(a:player{name: "Tim Duncan", age: 42})
在这个点上可以有一条边是:(a)-[e:follow{degree: 95}]->(b) -
边模式

-
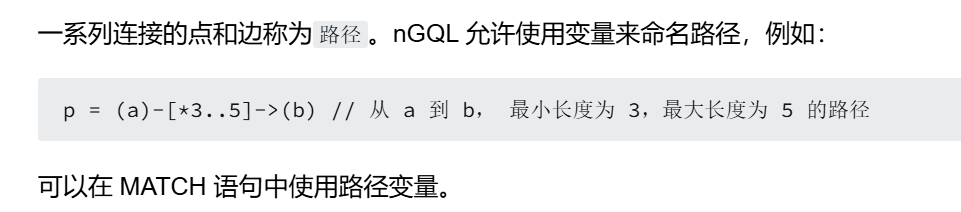
变长模式

-
路径变量
3.2 查询例子
1. 【星影】查询所有顶点(VERTEX)的id
MATCH (v) RETURN id(v);
2. 【星影】在主操作区中打开一个表格面板,展示当前 tag 的数据,并按页加载,每页100条数据,执行以下语句:
MATCH (n:player)
RETURN id(n), n.`player`.`name` AS `name`, n.`player`.`age` AS `age`
SKIP 0 LIMIT 100;
- 上下文:这里的查询限定了标签 player,仅返回所有带有 player 标签的顶点的 ID 及其属性。
- 返回 ID 的范围:只包含具有 player 标签的顶点的 ID。
- 结果:只显示与 player 标签相关的顶点 ID。
- 用途:适合查询特定标签的顶点信息。
3. 【星影】在主操作区中打开一个表格面板,展示当前 edgeType 的数据,并按页加载,每页100条数据,执行以下语句:(需要在边表创建了索引的前提下,如展示失败,可通过【索引】按钮进行索引创建。)
MATCH (src)-[r:follow]->(dst)
RETURN id(src), rank(r), id(dst), r.`degree` AS `degree`
SKIP 0 LIMIT 100;
语句解释
MATCH (src)-[r:follow]->(dst)
MATCH:用于匹配图中的模式。(src) 和 (dst):表示图中的两个顶点,分别是源顶点和目标顶点,src 是变量名表示源顶点,dst 是变量名表示目标顶点。-[r:follow]->:表示从 src 到 dst 的一条有方向的边,边的类型是 follow。r 是变量名,表示边本身。
箭头符号 ->:表示边的方向,从 src 指向 dst。
RETURN id(src), rank(r), id(dst), r.degree AS degree
id(src):返回源顶点 src 的唯一 ID。rank(r):返回边 r 的 排名,通常用于排序或在查询中进行比较。id(dst):返回目标顶点 dst 的唯一 ID。r.\degreeASdegree:返回边 r的degree属性,并将其重命名为degree`,以便查询结果更易读。- degree 是边的一个属性,表示某种度量值,例如该 follow 关系的强度或程度。
SKIP 0
- 从查询结果中跳过前 0 条记录(即不跳过任何记录)。这是分页的一部分,通常用于指定从查询结果的某个位置开始返回数据。
- LIMIT 100
- 限制查询结果的返回条数为 100,即只获取查询结果的前 100 条记录。
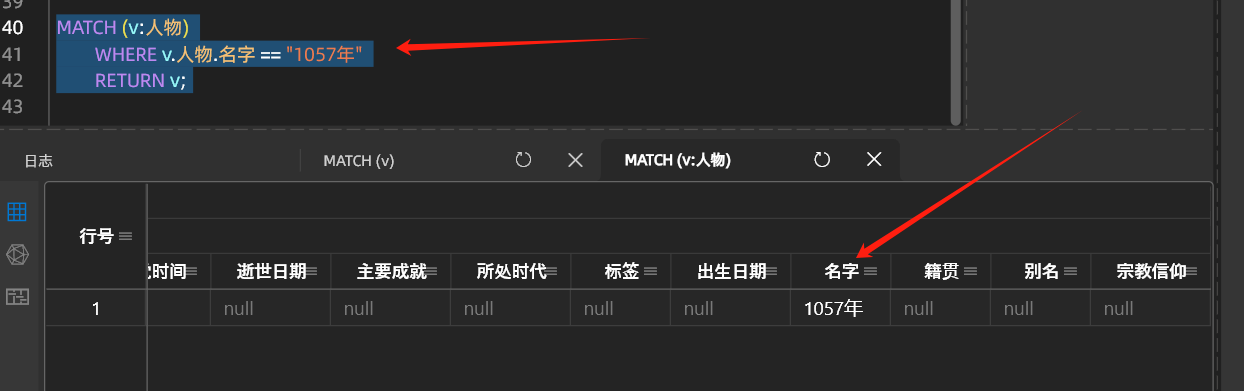
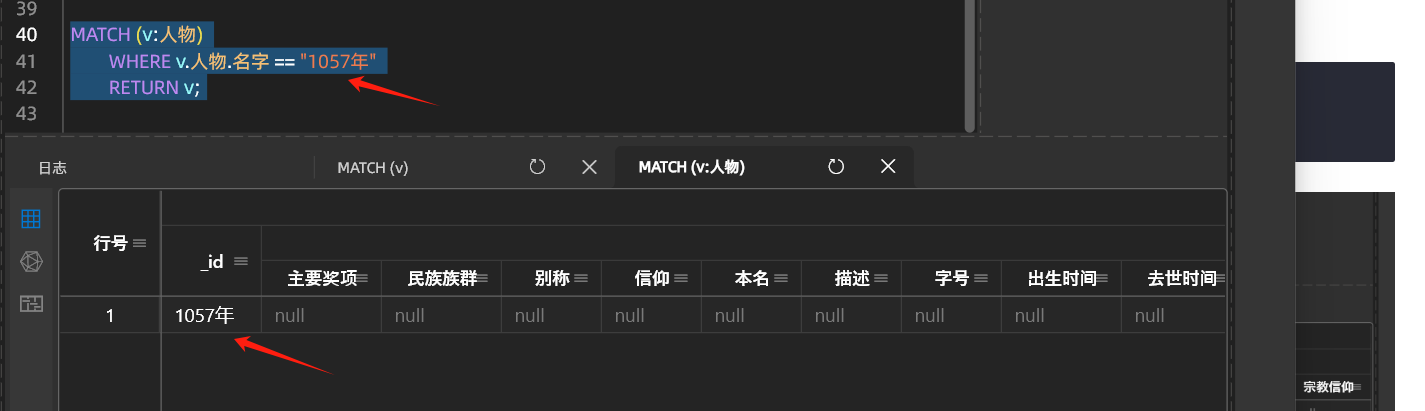
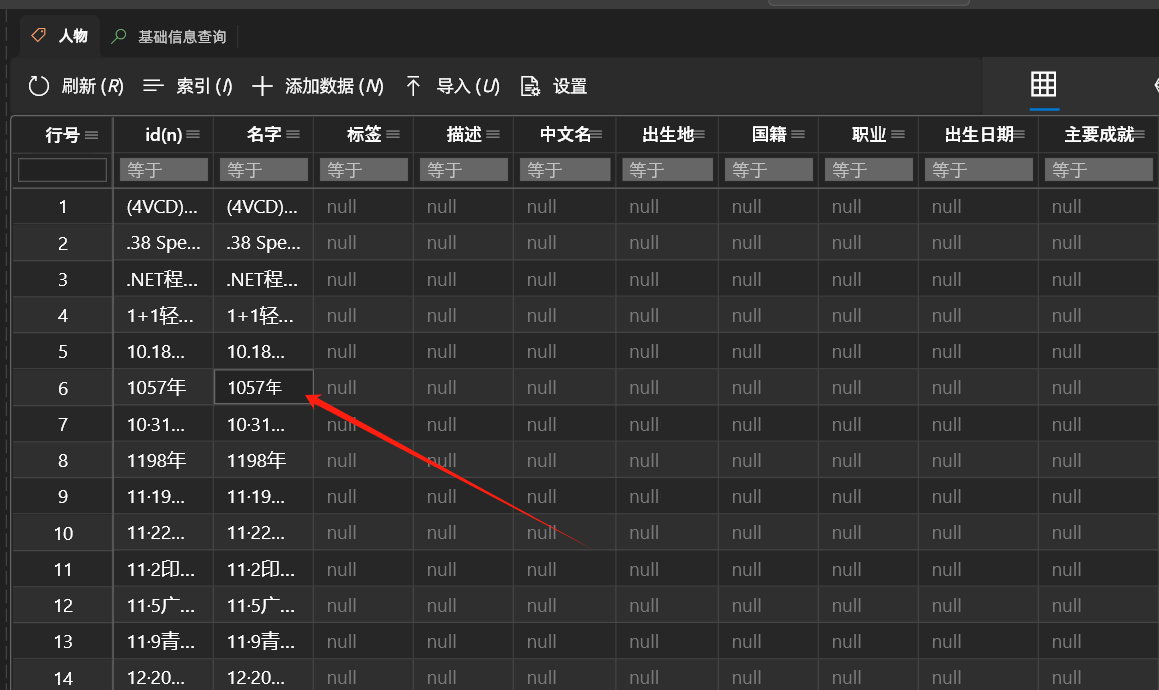
4.通过某个tag的某个属性查询VERTEX
# 注意这里返回的也只有TAG 人物的信息
MATCH (v:人物)
WHERE v.人物.名字 == "1057年"
RETURN v;
4. 查询中一些结果说明
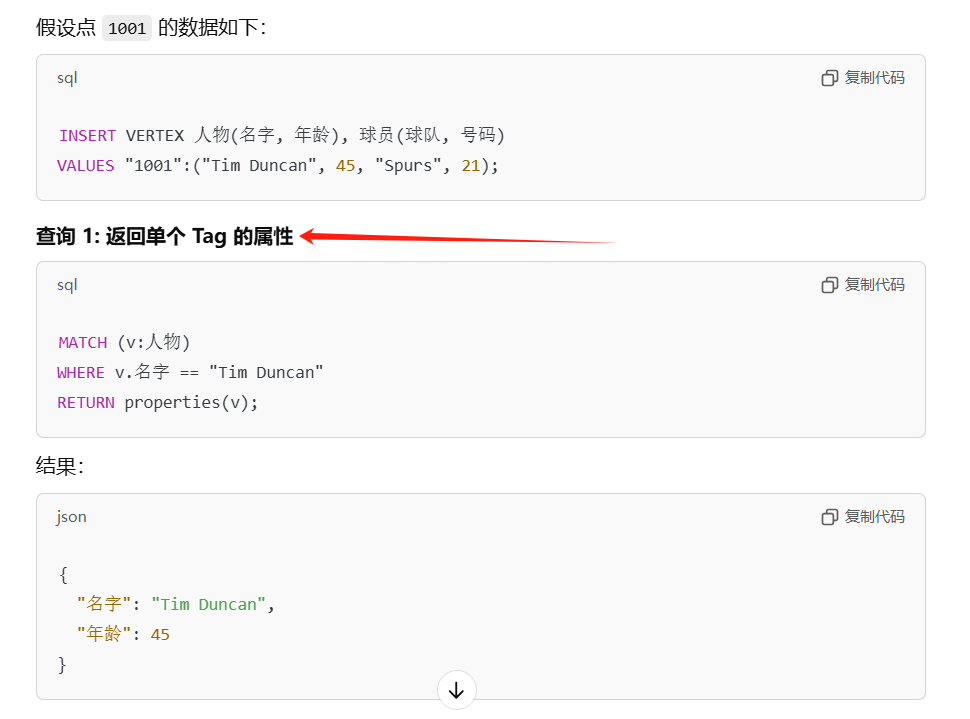
4.1 properties(v) 的作用
- 提取属性集合: properties(v) 返回与点 v 关联的属性键值对,格式是一个 Map,其中键是属性名,值是对应的属性值。
- 精简结果: 与直接 RETURN v 返回点及所有关联的信息(包括所有 Tag 和点 ID)相比,properties(v) 只包含当前查询涉及的属性。
举个例子
假设我们有以下点和标签:
CREATE TAG 人物 (名字 STRING, 年龄 INT);
CREATE TAG 球员 (球队 STRING, 号码 INT);
INSERT VERTEX 人物(名字, 年龄), 球员(球队, 号码) VALUES "1001":("Tim Duncan", 45, "Spurs", 21);
执行以下查询:
MATCH (v:人物)
WHERE v.名字 == "Tim Duncan"
RETURN properties(v);
结果
{
"名字": "Tim Duncan",
"年龄": 45
}
properties(v) 的行为
- properties(v) 返回与查询匹配的点 v 的 当前指定标签 的属性集合。
- 因为你指定了 人物 标签,properties(v) 只返回属于 人物 标签的属性。
- 如果希望获取所有关联标签的属性,需要调整查询方式(见后文示例)。
如何返回所有关联 Tag 的属性?
如果希望获取点 v 的所有标签及其属性,可以省略标签限制:
MATCH (v)
WHERE id(v) == "1001"
RETURN properties(v);
再次说明

4.2 如果我通过某个顶点的tag的某一个属性来查询,然后我还需要返回这个顶点的所有tag详细信息,怎么查询
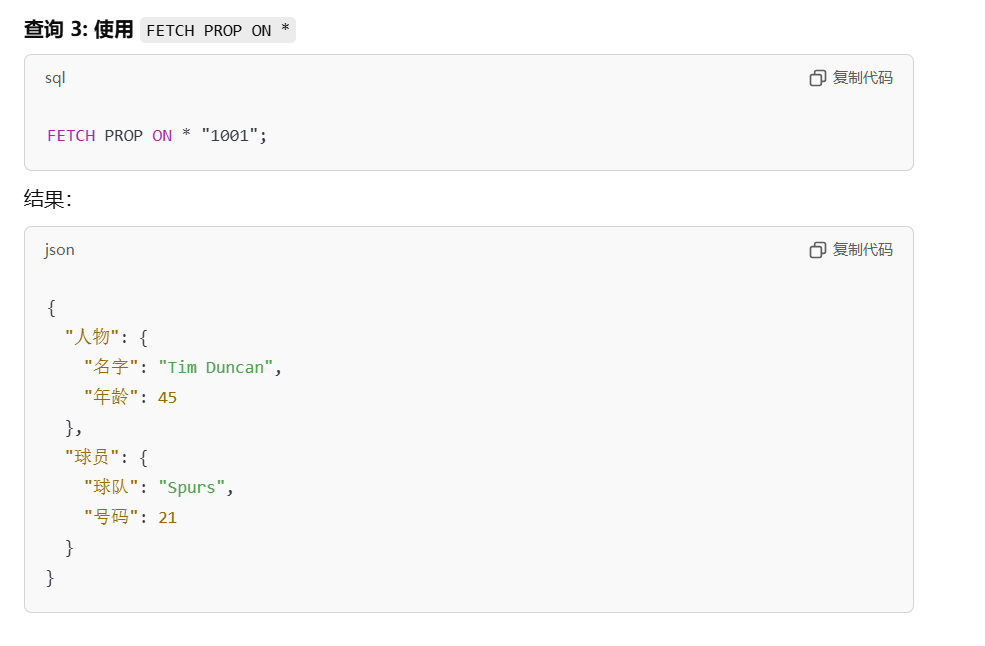
- 查询方法
- 使用
MATCH和FETCH PROP ON *组合查询: - 使用
MATCH根据特定属性找到顶点ID。 - 再用
FETCH PROP ON *根据ID查询顶点的所有标签和属性。

通过两步查询
-- Step 1: 查询满足条件的点的 ID
MATCH (v:人物)
WHERE v.人物.名字 == "1057年"
RETURN id(v) AS vertexId;
-- Step 2: 使用 FETCH 查询所有标签的属性
FETCH PROP ON * vertexId YIELD properties(vertex);
4.3 匹配点的属性
用户可以在 Tag 的右侧用{<prop_name>: <prop_value>}表示模式中点的属性。
# 使用属性 name 搜索匹配的点。
nebula> MATCH (v:player{name:"Tim Duncan"}) \
RETURN v;
+----------------------------------------------------+
| v |
+----------------------------------------------------+
| ("player100" :player{age: 42, name: "Tim Duncan"}) |
+----------------------------------------------------+
使用WHERE子句也可以实现相同的操作:
# 查找类型为 player,名字为 Tim Duncan 的点。
nebula> MATCH (v:player) \
WHERE v.player.name == "Tim Duncan" \
RETURN v;
+----------------------------------------------------+
| v |
+----------------------------------------------------+
| ("player100" :player{age: 42, name: "Tim Duncan"}) |
+----------------------------------------------------+
重点
使用WHERE子句直接匹配点的属性。
# 匹配属性中值等于 Tim Duncan 的点。 ===>执行时间消耗 99.826774 (s)
nebula> MATCH (v) \
WITH v, properties(v) as props, keys(properties(v)) as kk \
WHERE [i in kk where props[i] == "Tim Duncan"] \
RETURN v;
+----------------------------------------------------+
| v |
+----------------------------------------------------+
| ("player100" :player{age: 42, name: "Tim Duncan"}) |
+----------------------------------------------------+
# 匹配 name 属性值存在于 names 列表内的起点,并返回起点和终点的数据。
nebula> WITH ['Tim Duncan', 'Yao Ming'] AS names \
MATCH (v1:player)-->(v2:player) \
WHERE v1.player.name in names \
RETURN v1, v2;
+----------------------------------------------------+----------------------------------------------------------+
| v1 | v2 |
+----------------------------------------------------+----------------------------------------------------------+
| ("player133" :player{age: 38, name: "Yao Ming"}) | ("player114" :player{age: 39, name: "Tracy McGrady"}) |
| ("player133" :player{age: 38, name: "Yao Ming"}) | ("player144" :player{age: 47, name: "Shaquille O'Neal"}) |
| ("player100" :player{age: 42, name: "Tim Duncan"}) | ("player101" :player{age: 36, name: "Tony Parker"}) |
| ("player100" :player{age: 42, name: "Tim Duncan"}) | ("player125" :player{age: 41, name: "Manu Ginobili"}) |
+----------------------------------------------------+----------------------------------------------------------+
这个逻辑
- 获取图数据库中的所有节点。
- 提取每个节点的属性及其键。
- 过滤节点,只保留属性值中包含 “Tim Duncan” 的节点。
- 返回符合条件的节点。
但是这个查询(第一个)耗时:执行时间消耗 99.826774 (s)
4.4 匹配点 ID
用户可以使用点 ID 去匹配点。id()函数可以检索点的 ID。
# 查找 ID 为 “player101” 的点。(注:ID 全局唯一)。
nebula> MATCH (v) \
WHERE id(v) == 'player101' \
RETURN v;
+-----------------------------------------------------+
| v |
+-----------------------------------------------------+
| ("player101" :player{age: 36, name: "Tony Parker"}) |
+-----------------------------------------------------+
要匹配多个点的 ID,可以用WHERE id(v) IN [vid_list]或者WHERE id(v) IN {vid_list}。
# 查找与 `Tim Duncan` 直接相连的点,并且这些点的 ID 必须是 `player101` 或 `player102`。
nebula> MATCH (v:player { name: 'Tim Duncan' })--(v2) \
WHERE id(v2) IN ["player101", "player102"] \
RETURN v2;
+-----------------------------------------------------------+
| v2 |
+-----------------------------------------------------------+
| ("player101" :player{age: 36, name: "Tony Parker"}) |
| ("player101" :player{age: 36, name: "Tony Parker"}) |
| ("player102" :player{age: 33, name: "LaMarcus Aldridge"}) |
+-----------------------------------------------------------+
# 查找 ID 为 player100 和 player101 的点,并返回 name 属性。
nebula> MATCH (v) WHERE id(v) IN {"player100", "player101"} \
RETURN v.player.name AS name;
+---------------+
| name |
+---------------+
| "Tony Parker" |
| "Tim Duncan" |
+---------------+
4.5 匹配连接的点
用户可以使用--符号表示两个方向的边,并匹配这些边连接的点。
从 nGQL 2.x 起,--符号表示出边或入边,不再用于注释。
# name 属性值为 Tim Duncan 的点为 v,与 v 相连接的点为 v2,查找 v2 并返回其 name 属性值。
nebula> MATCH (v:player{name:"Tim Duncan"})--(v2:player) \
RETURN v2.player.name AS Name;
+---------------------+
| Name |
+---------------------+
| "Manu Ginobili" |
| "Manu Ginobili" |
| "Dejounte Murray" |
...
用户可以在--符号上增加<或>符号指定边的方向。
# `-->` 表示边从 v 开始,指向 v2。对于点 v 来说是出边,对于点 v2 来说是入边。
nebula> MATCH (v:player{name:"Tim Duncan"})-->(v2:player) \
RETURN v2.player.name AS Name;
+-----------------+
| Name |
+-----------------+
| "Tony Parker" |
| "Manu Ginobili" |
+-----------------+
如果需要扩展模式,可以增加更多点和边。
# name 属性值为 Tim Duncan 的点为 v,指向点 v2,点 v3 也指向点 v2,返回 v3 的 name 属性值。
nebula> MATCH (v:player{name:"Tim Duncan"})-->(v2)<--(v3) \
RETURN v3.player.name AS Name;
+---------------------+
| Name |
+---------------------+
| "Dejounte Murray" |
| "LaMarcus Aldridge" |
| "Marco Belinelli" |
...
如果不需要引用点,可以省略括号中表示点的变量。
# 查找 name 属性值为 Tim Duncan 的点 v, 点 v3 与 v 指向同一个点,返回 v3 的 name 属性值。
nebula> MATCH (v:player{name:"Tim Duncan"})-->()<--(v3) \
RETURN v3.player.name AS Name;
+---------------------+
| Name |
+---------------------+
| "Dejounte Murray" |
| "LaMarcus Aldridge" |
| "Marco Belinelli" |
...
4.6 匹配路径
连接起来的点和边构成了路径。用户可以使用自定义变量命名路径。
# 设置路径 p,其模式为 name 属性值为 Tim Duncan 的点 v 指向相邻的点 v2。返回所有符合条件的路径。
nebula> MATCH p=(v:player{name:"Tim Duncan"})-->(v2) \
RETURN p;
+--------------------------------------------------------------------------------------------------------------------------------------+
| p |
+--------------------------------------------------------------------------------------------------------------------------------------+
| <("player100" :player{age: 42, name: "Tim Duncan"})-[:serve@0 {end_year: 2016, start_year: 1997}]->("team204" :team{name: "Spurs"})> |
| <("player100" :player{age: 42, name: "Tim Duncan"})-[:follow@0 {degree: 95}]->("player101" :player{age: 36, name: "Tony Parker"})> |
| <("player100" :player{age: 42, name: "Tim Duncan"})-[:follow@0 {degree: 95}]->("player125" :player{age: 41, name: "Manu Ginobili"})> |
+--------------------------------------------------------------------------------------------------------------------------------------+
4.7 匹配边
# 匹配对应边并返回 3 条数据。
nebula> MATCH ()<-[e]-() \
RETURN e \
LIMIT 3;
+----------------------------------------------------+
| e |
+----------------------------------------------------+
| [:follow "player101"->"player102" @0 {degree: 90}] |
| [:follow "player103"->"player102" @0 {degree: 70}] |
| [:follow "player135"->"player102" @0 {degree: 80}] |
+----------------------------------------------------+
4.8 匹配 Edge type
和点一样,用户可以用:<edge_type>表示模式中的 Edge type,例如-[e:follow]-。
# 匹配所有 edge type 为 follow 的边。
nebula> MATCH ()-[e:follow]->() \
RETURN e;
+----------------------------------------------------+
| e |
+----------------------------------------------------+
| [:follow "player102"->"player100" @0 {degree: 75}] |
| [:follow "player102"->"player101" @0 {degree: 75}] |
| [:follow "player129"->"player116" @0 {degree: 90}] |
...
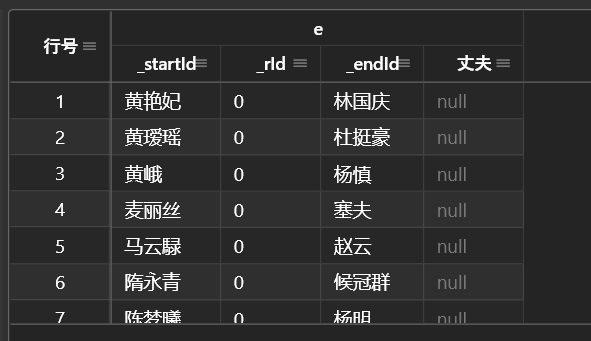
MATCH () -[ e : 丈夫 ]->()
RETURN e;
4.9 匹配边的属性
用户可以用{<prop_name>: <prop_value>}表示模式中Edge type 的属性,例如[e:follow{likeness:95}]。
nebula> MATCH (v:player{name:"Tim Duncan"})-[e:follow{degree:95}]->(v2) \
RETURN e;
+--------------------------------------------------------+
| e |
+--------------------------------------------------------+
| [:follow "player100"->"player101" @0 {degree: 95}] |
| [:follow "player100"->"player125" @0 {degree: 95}] |
+--------------------------------------------------------+
- 方向性:
- 箭头 -> 指定了边的方向,意味着查询中将匹配从 v 节点指向 v2 节点的边。
- 如果边的方向是从 v2 指向 v,则此查询不会匹配。
无方向查询
MATCH (v:player{name:"Tim Duncan"})-[e:follow{degree:95}]-(v2)
RETURN e;
使用WHERE子句直接匹配边的属性。
nebula> MATCH ()-[e]->() \
WITH e, properties(e) as props, keys(properties(e)) as kk \
WHERE [i in kk where props[i] == 90] \
RETURN e;
+----------------------------------------------------+
| e |
+----------------------------------------------------+
| [:follow "player125"->"player100" @0 {degree: 90}] |
| [:follow "player140"->"player114" @0 {degree: 90}] |
| [:follow "player133"->"player144" @0 {degree: 90}] |
| [:follow "player133"->"player114" @0 {degree: 90}] |
...
+----------------------------------------------------+
匹配多个 Edge type
使用|可以匹配多个Edge type,例如[e:follow|:serve]。第一个 Edge type 前的英文冒号(:)不可省略,后续 Edge type 前的英文冒号可以省略,例如[e:follow|serve]。
nebula> MATCH (v:player{name:"Tim Duncan"})-[e:follow|:serve]->(v2) \
RETURN e;
+---------------------------------------------------------------------------+
| e |
+---------------------------------------------------------------------------+
| [:follow "player100"->"player101" @0 {degree: 95}] |
| [:follow "player100"->"player125" @0 {degree: 95}] |
| [:serve "player100"->"team204" @0 {end_year: 2016, start_year: 1997}] |
+---------------------------------------------------------------------------+
匹配多条边
用户可以扩展模式,匹配路径中的多条边。
nebula> MATCH (v:player{name:"Tim Duncan"})-[]->(v2)<-[e:serve]-(v3) \
RETURN v2, v3;
+----------------------------------+-----------------------------------------------------------+
| v2 | v3 |
+----------------------------------+-----------------------------------------------------------+
| ("team204" :team{name: "Spurs"}) | ("player104" :player{age: 32, name: "Marco Belinelli"}) |
| ("team204" :team{name: "Spurs"}) | ("player101" :player{age: 36, name: "Tony Parker"}) |
| ("team204" :team{name: "Spurs"}) | ("player102" :player{age: 33, name: "LaMarcus Aldridge"}) |
...
匹配定长路径
用户可以在模式中使用:<edge_type>*<hop>匹配定长路径。hop必须是一个非负整数。
nebula> MATCH p=(v:player{name:"Tim Duncan"})-[e:follow*2]->(v2) \
RETURN DISTINCT v2 AS Friends;
+-----------------------------------------------------------+
| Friends |
+-----------------------------------------------------------+
| ("player100" :player{age: 42, name: "Tim Duncan"}) |
| ("player125" :player{age: 41, name: "Manu Ginobili"}) |
| ("player102" :player{age: 33, name: "LaMarcus Aldridge"}) |
+-----------------------------------------------------------+
匹配最短路径
用户可以使用allShortestPaths返回起始点到目标点的所有最短路径。
nebula> MATCH p = allShortestPaths((a:player{name:"Tim Duncan"})-[e*..5]-(b:player{name:"Tony Parker"})) \
RETURN p;
+------------------------------------------------------------------------------------------------------------------------------------+
| p |
+------------------------------------------------------------------------------------------------------------------------------------+
| <("player100" :player{age: 42, name: "Tim Duncan"})<-[:follow@0 {degree: 95}]-("player101" :player{age: 36, name: "Tony Parker"})> |
| <("player100" :player{age: 42, name: "Tim Duncan"})-[:follow@0 {degree: 95}]->("player101" :player{age: 36, name: "Tony Parker"})> |
+------------------------------------------------------------------------------------------------------------------------------------+
用户可以使用shortestPath返回起始点到目标点的任意一条最短路径。
nebula> MATCH p = shortestPath((a:player{name:"Tim Duncan"})-[e*..5]-(b:player{name:"Tony Parker"})) \
RETURN p;
+------------------------------------------------------------------------------------------------------------------------------------+
| p |
+------------------------------------------------------------------------------------------------------------------------------------+
| <("player100" :player{age: 42, name: "Tim Duncan"})<-[:follow@0 {degree: 95}]-("player101" :player{age: 36, name: "Tony Parker"})> |
+------------------------------------------------------------------------------------------------------------------------------------+


















 3万+
3万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











