




 本文解析了以太坊MerklePatriciaTrie的源码,重点关注RLP编码规则、Trie数据结构(包括reader和tracer)、数据库管理和节点操作方法(如get和update)。
本文解析了以太坊MerklePatriciaTrie的源码,重点关注RLP编码规则、Trie数据结构(包括reader和tracer)、数据库管理和节点操作方法(如get和update)。
1. Merkle Patricia Trie 源码分析
0.1 RLP编码:json 未知编码 byte 解码_以太坊RLP编码_最暖最珍贵的博客-优快云博客
RLP(RECURSIVE LENGTH PREFIX) 递归长度前缀序列化方式,还有常见的就是json序列化方式.(序列化是将任意的数据结构编码为有结构的二进制数据byte arrays)

RLP函数的定义(递归函数定义):
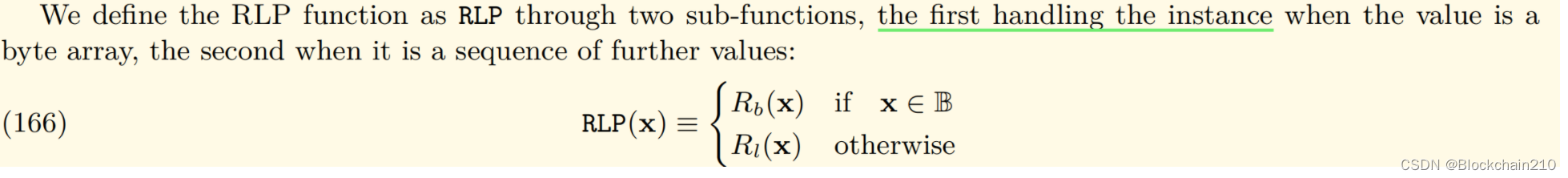
RLP函数的5条编码规则(通过以下规则,我们可以通过字节数组推导出值):
-
如果值在[0,127]之间的单个字节,其编码是其本身.

-
如果byte数组的长度l<=55,编码的结果是数组本身,再加上128+l作为前缀.
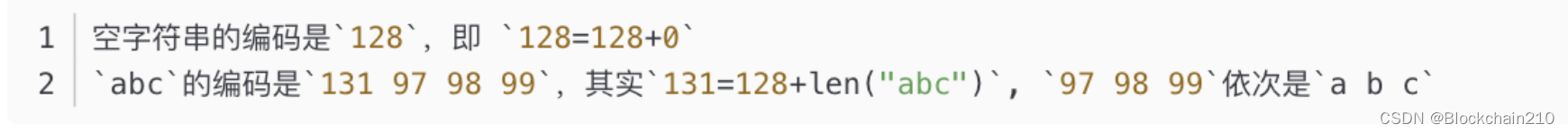
-
如果数组长度大于55,编码结果第一个值是183(128+55)加数组长度的编码的长度,然后是数组长度本身的编码,最后是byte数组的编码.
比如编码一个重复1024次"a",且结果是
185 1 0 97 97 97 ...因为长度大于55,所以1024的2进制表示:0000,0100,0000,0000
按照大端序:0000,0000,0001,0000=> 所以按照16进制表示:0010,省略前面的0,长度为2.
-
如果列表(字节数组的数组) 长度小于55,编码结果第一位是192加列表长度的编码的长度,然后依次连接各个子列表的编码.

["abc","def"]的编码结果是200| 131 97 98 99 | 131 100 101 102 |是实际不存在的,只是便于我们理解而存在
1.1 Trie的概述
包位置:go-ethereum/trie
该包用New方法在数据库(database)构建一个trie.
-
无论何时trie执行一个commit操作,生成的节点都会在集合中被收集并返回.
-
一旦trie被提交,它就再也不会被使用(Once the trie is committed,it’s not usable anymore.)
-
Callers 不等不在更新的trie database上重新创建一个new root的trie.
1.1.1 trie的提供的接口:
-
New方法:建立一个trie
func New(id *ID, db *Database) (*Trie, error) -
NewEmpty方法:构建一个空的trie(这个所谓的空是指创世区块中StateRoot所对应的MPT树)
func NewEmpty(db *Database) *Trie { //types.EmptyRootHash是创世根hash的作用. tr, _ := New(TrieID(types.EmptyRootHash), db) return tr }// TrieID constructs an identifier for a standard trie(not a second-layer trie) // with provided root. It's mostly used in tests and some other tries like CHT trie. func TrieID(root common.Hash) *ID { return &ID{ StateRoot: root, Owner: common.Hash{ }, Root: root, } }
1.2 trie package中的Trie的数据结构(重点在于reader和tracer字段)
reader字段用于检索MPT树的节点;tracer用来追踪MPT树的变化
type Trie struct{
root node
owner common.Hash
//标记该Trie是否被提交,如果提交了那么该trie就不会被使用(最新状态也不可见)
committed bool
//追踪自从上次hash操作开始被插入的叶子节点数量
unhashed int
//reader是trie检索节点的处理函数
reader *trieReader
//tracer是追踪trie改变的工具
// 每次提交操作之后将会被重置.
tracer *tracer
}
其可以用如下图来表示Trie的数据结构 
1.2.1 新建Trie
func New(id *ID, db *Database) (*Trie, error) {
//db *Database 包是在go-ethereum/trie/database.go
//创建可以检索MPT树的处理函数,详见1.2.2Reader
reader, err := newTrieReader(id.StateRoot, id.Owner, db)
if err != nil {
return nil, err
}
trie := &Trie{
owner: id.Owner,
reader: reader,
tracer: newTracer(),//新建追踪器,
}
//接下来如何找到MPT的root,详见1.2.6
if id.Root != (common.Hash{
}) && id.Root != types.EmptyRootHash {
//详见1.2.7:如何寻找MPT的root node?(resolveAndTrack)
rootnode, err := trie.resolveAndTrack(id.Root[:], nil)
if err != nil {
return nil, err
}
trie.root = rootnode
}
}
id *ID: 数据结构表示如下: 决定了该创建的MPT树是状态树还是存储树

状态树(state trie)需要StateRoot和Root(且StateRoot字段和Root字段相同);存储树(storage trie)需要StateRoot,Owner(因为存储树是相对于一个智能合约的,所以需要合约地址)以及Root
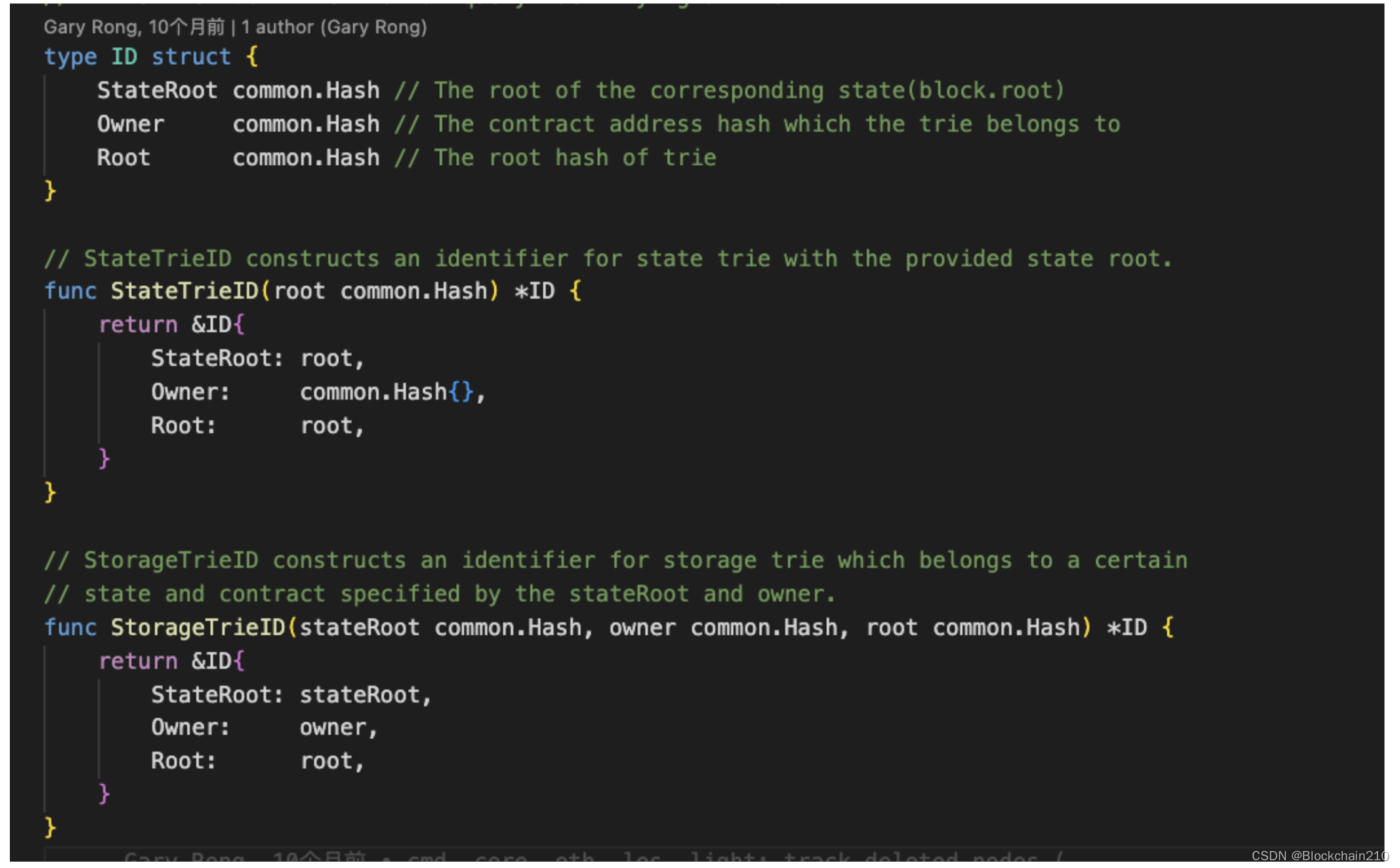
需要值得注意的是:
ID.StateRoot是指区块的Root字段
ID.Root是指该MPT树的根节点的hash值
1.2.2 Reader(检索器)数据结构及方法
代码位置: go-ethereum/trie/trie_reader.go
// reader接口包装了trie存储的节点方法.
type Reader interface{
Node(owner common.Hash, path []byte, hash common.Hash) ([]byte, error)
}
对 上述接口的实现结构体
type trieReader struct{
owner common.Hash
reader Reader
banned map[string]struct{
} // Marker to prevent node from being accessed, for tests
}
创建TrieReader方法:newTrieReader()
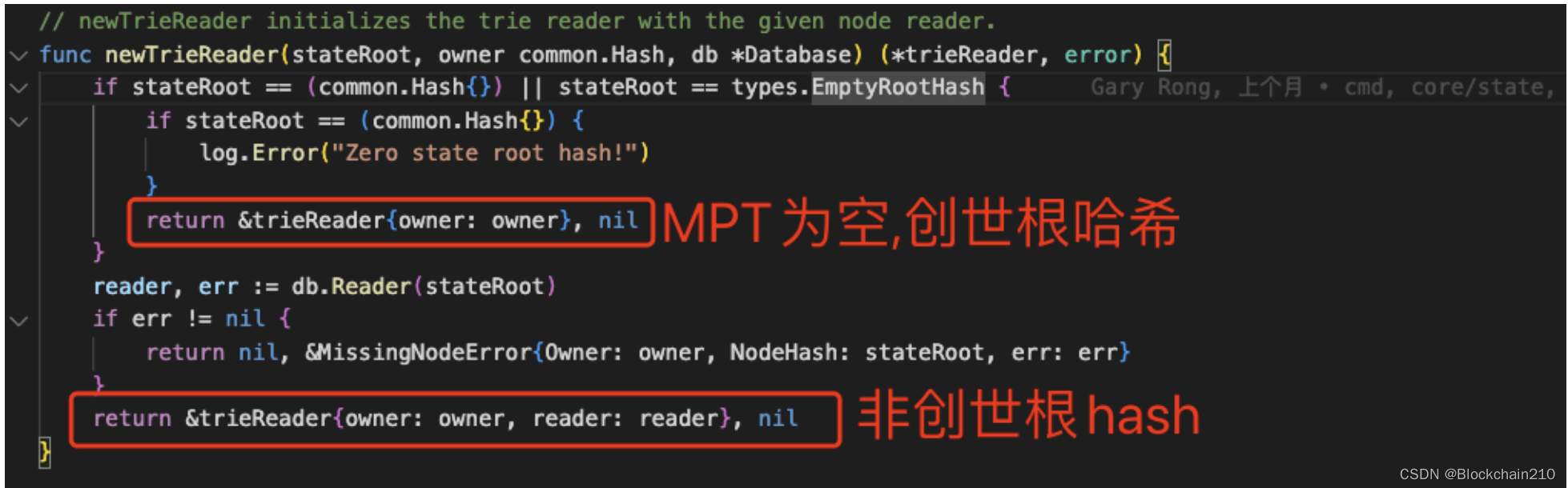
实际上trieReader的reader字段是由db *Database 中的Reader方法所创建的,详见1.2.4
EmptyRootHash =common.HexToHash("56e81f171bcc55a6ff8345e692c0f86e5b48e01b996cadc001622fb5e363b421")
上述的hash值称为创世根hash即在创世区块中的StateRoot

1.2.3 Database 数据结构
代码位置go-ethereum/trie/database.go
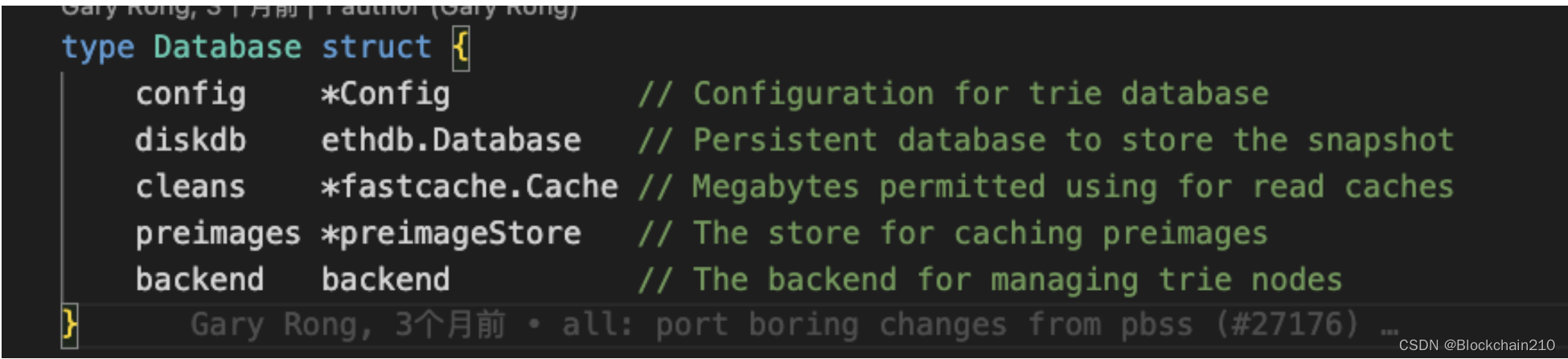
对于树的节点的管理,我们定义了backend接口,只要实现该接口中的方法就可以实现MPT树的节点管理.
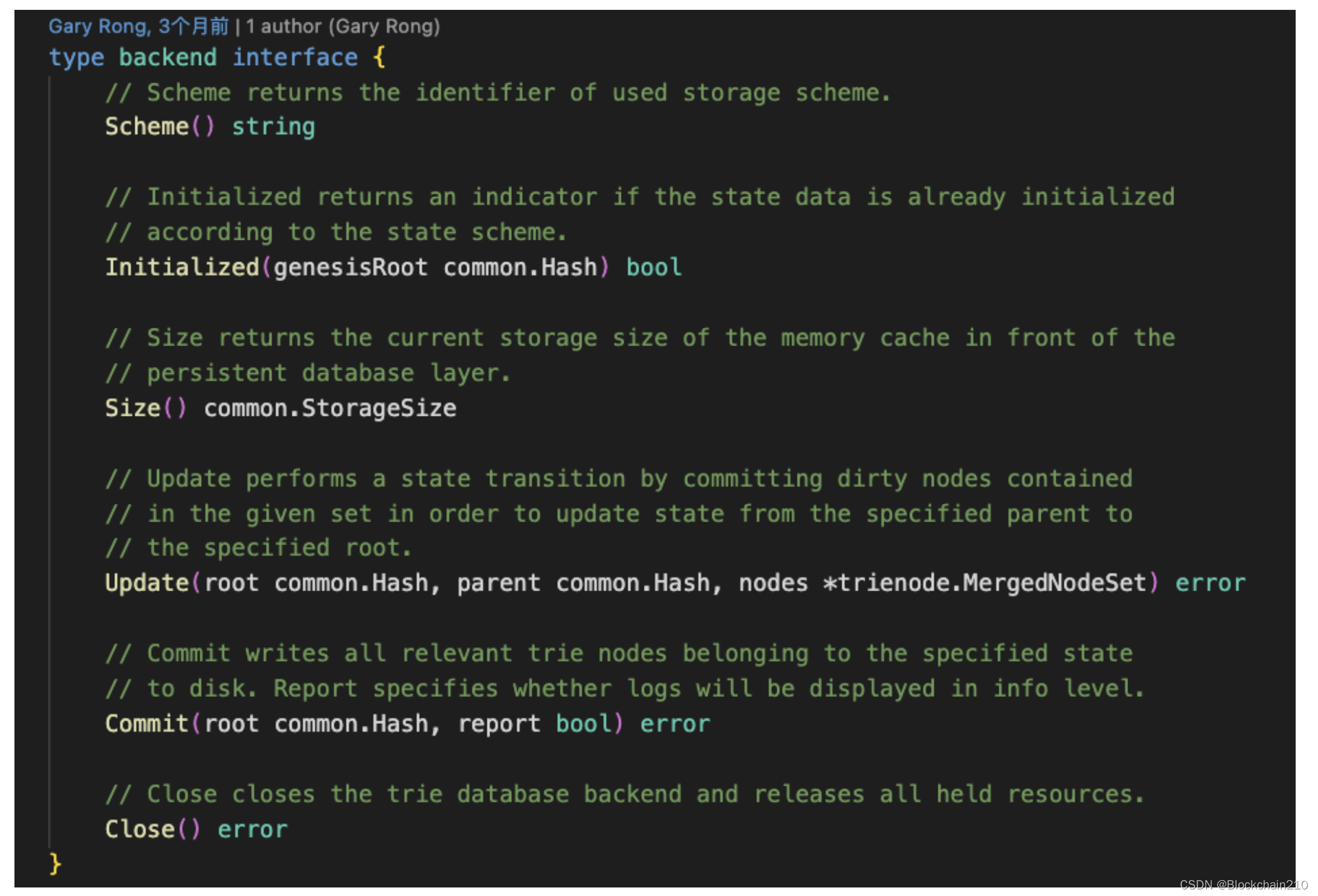
1.2.4 Database.Reader()方法

实际上是利用hashdb package的Reader方法,详见
1.2.5 Tracer(追踪器)数据结构及方法
代码位置: go-eth
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 892
892

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











