







 本文介绍了如何使用Python的Selenium库结合ChromeDriver来爬取动态网页数据,具体应用在爬取网易云音乐播放数超过500万的歌单和QQ音乐榜单上。在爬取网易云音乐时,遇到HTML未运行JavaScript的问题,通过Selenium解决了。同时,文章提到了QQ音乐榜单爬取时的数量标签中文处理和翻页URL的动态拼接方法。
本文介绍了如何使用Python的Selenium库结合ChromeDriver来爬取动态网页数据,具体应用在爬取网易云音乐播放数超过500万的歌单和QQ音乐榜单上。在爬取网易云音乐时,遇到HTML未运行JavaScript的问题,通过Selenium解决了。同时,文章提到了QQ音乐榜单爬取时的数量标签中文处理和翻页URL的动态拼接方法。
感谢提供素材的同学,无论好坏,高低,我都真心佩服你:参考文章地址:https://mp.weixin.qq.com/s/AXr8BjR_tU-E9YBo-mLVlg
爬取网易云音乐榜单
在上一篇的文章中,总结了爬虫的四个步骤,之后的爬虫也大都会按照这四个步骤去分析。因为这样分析更有利于我们去看清问题所在,看看我们爬虫所面对的难点是在那个步骤上,然后我们也可以做到心里有数,让我们去学习更加有目标。
在这里定下一个小目标:爬取网易云播放数大于500万的歌单
我们第一步可能会去尝试着去使用前面的urllib去获取网页源代码,在这里我们先尝试一下:获取的东西是什么?
代码:
html = urlopen('http://music.163.com/#/discover/playlist/?order=hot&cat=%E5%85%A8%E9%83%A8&limit=35&offset=0') print(html)
结果:
<http.client.HTTPResponse object at 0x000001ADFBE16198>
很明显,我们按照这种方法是没有办法拿到源代码的,

现在的问题就是:我们获取不到源代码。我们也发现问题是:网站的HTML页面没有运行javaScript,那我们的问题是让我们爬取的html页面运行javaScript即可。
文章中的解决方法是 Selenium + PhantomJS (因为时代的变迁,PhantomJS已经不被selenium所支持)
我的解决方法是:Selenium + ChromeDriver
selenium是一款十分神奇的工具--------作者(我)这样觉得
使用selenium需要自己去下载,如果是基于pycharm开发,那么可以使用File-->settings
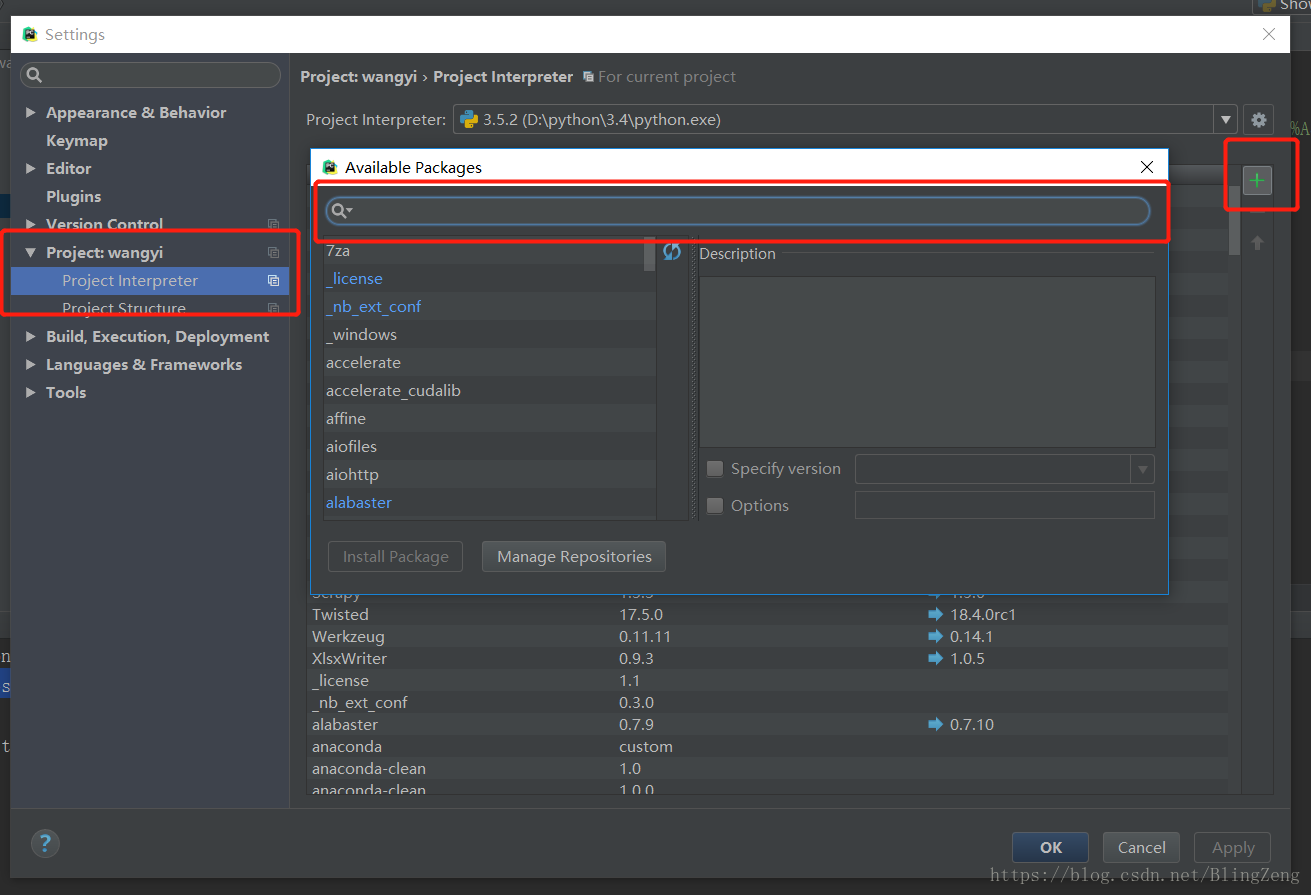
来添加selenium.
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









