




 本文探讨了机器学习中的过拟合现象,通过线性回归实例展示了过拟合与欠拟合的区别。过拟合是模型结构复杂、过度匹配训练数据导致在新数据上表现不佳,而欠拟合则是模型过于简单无法捕获数据规律。过拟合的原因包括模型参数过多和训练数据不足。奥卡姆剃刀原则指出应选择最简单的模型。解决过拟合的方法包括降低模型复杂度、增加训练数据和正则化。
本文探讨了机器学习中的过拟合现象,通过线性回归实例展示了过拟合与欠拟合的区别。过拟合是模型结构复杂、过度匹配训练数据导致在新数据上表现不佳,而欠拟合则是模型过于简单无法捕获数据规律。过拟合的原因包括模型参数过多和训练数据不足。奥卡姆剃刀原则指出应选择最简单的模型。解决过拟合的方法包括降低模型复杂度、增加训练数据和正则化。
点击上方“潜心的Python小屋”关注我们,第一时间推送优质文章。
前言
大家好,我是潜心。由于在小组会上提到了“过拟合”现象,发现自己很难给它下一个标准且规范的定义。因此查了一些资料,并简单做了下实验,进行简单整理。
本文约3k字,预计阅读15分钟。
过拟合与欠拟合
以一个简单的线性回归开始
简单的线性回归能够直观的反应过拟合和欠拟合的现象。首先我们随机生成若干个符合某二次多项式函数的点,并加入噪声,作为训练集。然后我们使用三个简单的线性模型(1次项回归,2次多项式回归、5次多项式回归)【注:多次项回归本质来说还是一个线性模型】来进行拟合,最后可视化,如下图所示。
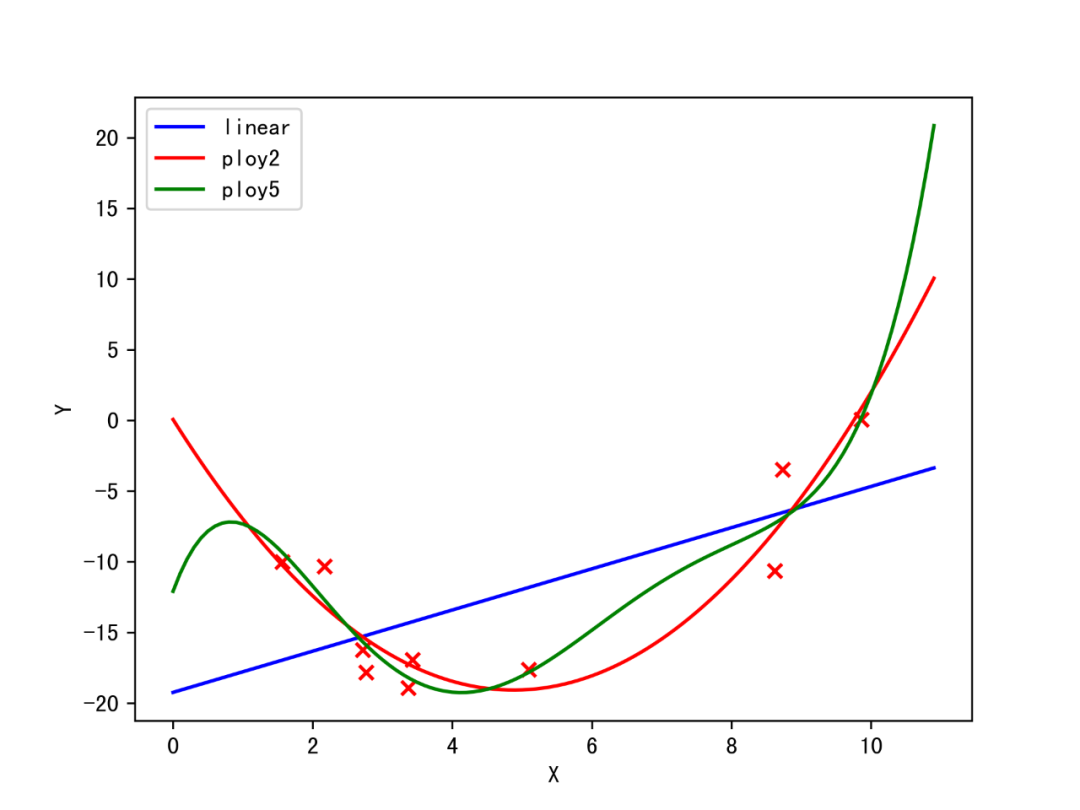
我们发现,1次项的模型结构简单,但拟合结果其他二者更差,无法捕捉数据中的规律,所以该模型出现了欠拟合的现象。
5次多项式回归的全部特征为: (此处我们在最简单的线性回归中只使用了1个特征
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 831
831

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









