




 本文介绍了协同过滤中的隐语义模型,该模型通过隐含特征联系用户兴趣和物品,常用于推荐系统。矩阵分解是实现隐语义模型的主要方法,包括基础的矩阵分解、添加偏置的矩阵分解和SVD++模型。这些模型能够结合用户和物品的偏置、隐式反馈等因素,提高推荐准确性。
本文介绍了协同过滤中的隐语义模型,该模型通过隐含特征联系用户兴趣和物品,常用于推荐系统。矩阵分解是实现隐语义模型的主要方法,包括基础的矩阵分解、添加偏置的矩阵分解和SVD++模型。这些模型能够结合用户和物品的偏置、隐式反馈等因素,提高推荐准确性。

点击上方“蓝字”关注我们

协同过滤(二)
Mar 26, 2020

本期介绍介绍协同过滤中的隐语义模型。
本文约2k字,预计阅读12分钟。
上篇文章【解析协同过滤方法】讲述了协同过滤的概念:只依赖于「过去的用户行为」,例如用户以前的交易或对物品的评分,而不需要创建显式的用户/物品的具体信息,这种方法被称为协同过滤。以及对协同过滤主要的方法之一-----「基于邻域的方法(the neighborhood approach)」进行了详细的阐述,并且分析了「基于用户的协同过滤」与「基于物品的协同过滤」的优缺点。
本篇文章将介绍协同过滤中另一种主要的方法-----「隐语义模型(latent factor model)」。
隐语义模型
自从Netflix Prize比赛举办以来,隐语义模型逐渐成为推荐系统主流的模型算法。其实该算法最早在文本挖掘领域被提出,用于找到文本的隐含语义。它的核心思想是通过隐含特征(latent factor)联系用户兴趣和物品。具体来说是通过将物品和用户都转换为相同的「隐含特征空间(latent factor space)」,从而使它们直接具有可比性。隐含特征空间试图通过根据用户反馈自动推断出的特征(factor)来表征物品和用户,从而解释评分。
参考[1],举个例子,对于电影来说,发现的特征(factor)可能会衡量「明显的维度」,例如喜剧与戏剧、电影中动作的数量、或对儿童的定向;「一些不太明确的维度」,例如角色发展的深度或古怪的程度;亦或者是「完全无法解释的维度」。对于用户来说,每个因素都会衡量用户对在相应电影的喜欢程度。
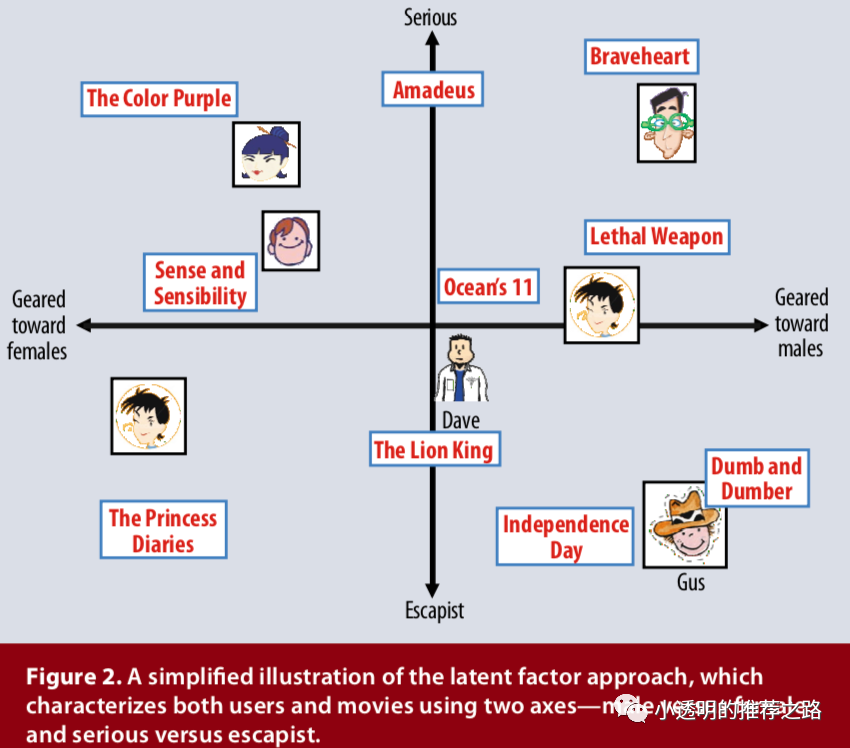
下图以二维的简化示例说明了这种想法。考虑两个假设维度,分别是女性和男性(x轴)以及严肃(Serious)与逃避现实的(escapist)(y轴)。对于此模型,相对于电影的平均评分,用户对电影的预测评分将等于电影和用户在图表上位置的点积。例如,Gus喜欢《Dumb and Dumber》,讨厌《The Color Purple》,并且将《Braveheart》评为平均水平。请注意,某些电影(例如《Ocean‘s 11》)和用户(例如Dave)的特征在这两个维度上都相当中立。
矩阵分解
矩阵分解(Matrix Factorization)是LFM(隐语义模型)中最主要的方法之一。最开始是Simon Funk等人[2]在2006年Netflix Prize比赛中,使用了Funk-SVD模型。之后一些研究进行了改进,如2008年Koren等人提出的SVD++以及基于邻域方法和SVD的整合[3]、2009年Koren等人[2]提出在基础的矩阵分解中引入用户和物品的偏置、隐式反馈、时间动态性、置信水平来进行建模,(具体可参考另一篇文章【论文导读】MATRIX FACTORIZATION TECHNIQUES FOR RECOMMENDER SYSTEMS)。
接下来我们简单的介绍下以上提到的部分模型:1、最基础的矩阵分解模型;2、添加偏置的矩阵分解模型;3、SVD++模型;
1.基础的矩阵分解模型
矩阵分解模型将用户和物品都映射到维数为 的联合潜在因子空间,并将用户和物品的交互建模为两者之间的内积操作。
定义:对于每一个物品 表征为隐向量 ,每一个用户 表征为隐向量
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 938
938

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









