







热火朝天的前言:
Agent火到停不下来!每天刷到新动态,根本追不上……
在当今快速发展的科技浪潮中,大模型Agent正成为推动人工智能发展的关键力量。它们如同拥有无限潜力的宝藏,等待着我们去挖掘和优化。本文将深入探讨大模型Agent的优化路径,从参数驱动到参数无关的策略,分析各种方法的优势与挑战,并展望未来的发展方向。这不仅是一场技术的探索,更是对智能未来的思考。让我们一起揭开大模型Agent优化的神秘面纱,探索其背后的技术炼金术。
大模型智能体优化方法综述:基于大型语言模型的Agent优化策略全解析的基本方法:以下论文链接
arXiv链接:
https://arxiv.org/abs/2503.12434
论文将现有方法分为两大类:
前者涵盖监督微调、强化学习(例如PPO、DPO)以及微调与强化学习相结合的混合策略,重点探讨了轨迹数据生成、奖励函数设计以及优化算法等核心模块。
后者则通过Prompt工程、外部工具调用、知识检索等手段,在不改动模型参数的情况下,对Agent的行为进行优化。
一:为什么我们需要专门优化LLM智能体?
近年来,以GPT-4、PaLM和DeepSeek为代表的大型语言模型(LLM)不仅在语言理解和生成任务中表现出色,还在推理、规划以及复杂决策等高阶能力上展现了非凡潜力。
这促使越来越多的研究者开始探索将LLM作为智能体(Agent)使用,研究其在自动决策和通用人工智能(AGI)方向的应用前景。与传统强化学习智能体不同,LLM智能体无需依赖显式的奖励函数,而是通过自然语言指令、Prompt设计以及上下文学习(In-Context Learning, ICL)来完成复杂任务。
这种基于“文本驱动”的智能体范式具备极高的灵活性与泛化能力,能够跨任务理解人类意图,执行多步骤操作,并在动态环境中进行高效决策。目前,研究者已通过任务分解、自我反思机制、记忆增强技术以及多智能体协作等方法进一步提升其性能,应用场景覆盖软件开发、数学推理、具身智能、网页导航等多个领域。
然而值得注意的是,LLM的核心训练目标是预测下一个token,而非专门为长期规划或交互式学习的智能体任务设计,这一固有特性也为其优化与应用带来了独特的挑战。
这也使得LLM作为Agent时面临一些挑战:
1- 在复杂任务中,其长程规划和多步推理能力较弱,容易出现错误累积;
2- 缺乏持续性记忆机制,难以基于历史经验进行反思和优化;
3- 对新环境的适应能力有限,难以动态应对变化场景。
开源LLM在Agent任务中的表现普遍不如GPT-4等闭源模型,而闭源模型的高昂成本与不透明性,促使优化开源LLM以提升其Agent能力成为当前研究的重要方向。
然而,现有的综述研究要么聚焦于大模型本身的优化方法,要么仅针对Agent的某些局部能力(如规划、记忆或角色扮演)进行探讨,未能将“LLM智能体优化”作为独立且系统的研究领域进行全面分析。
为此,研究团队填补了这一空白,首次以“基于LLM的Agent优化技术”为核心议题展开系统化综述。通过构建统一框架,归纳方法路径,并对比不同技术的优劣与适用场景,为该领域的研究提供了全面的技术视角和实践指导。
二.参数驱动的LLM智能体优化
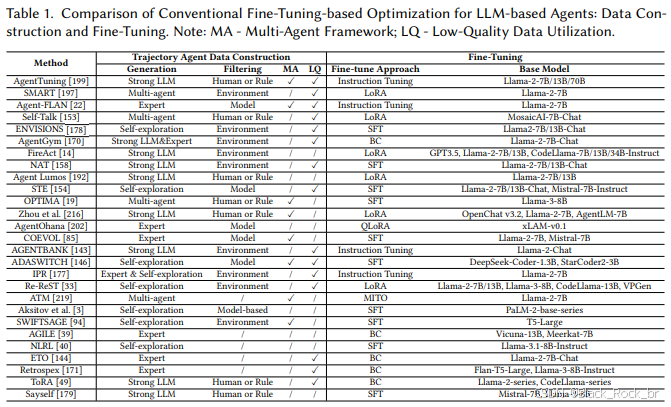
在参数驱动的LLM优化中,作者将其分为3个方向。
1.基于常规微调的优化
第一个方向是通过常规微调实现优化,这一过程分为两个关键步骤:首先,构建适用于Agent任务的高质量轨迹数据;其次,利用这些轨迹数据对Agent进行微调以提升性能.
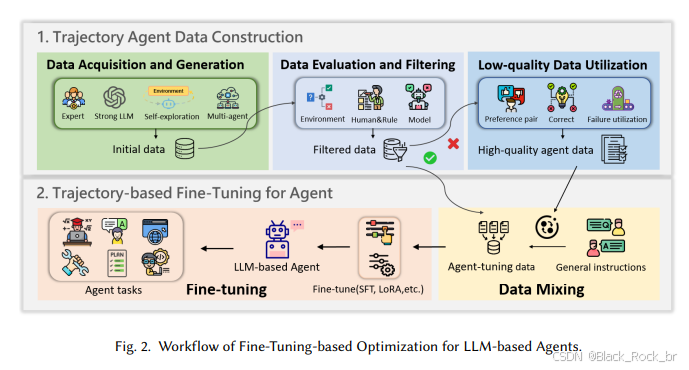
高质量轨迹数据的构建始于初始数据的获取与生成。这一过程不仅需要收集多样化的轨迹数据,还要求这些数据与目标任务高度对齐,从而确保模型能够进行有效的学习.
2.主流方法可分为以下四类:
专家标注数据:由人类专家精心设计,质量高且与目标对齐紧密,堪称微调的“黄金标准”。然而,其高昂的人力成本和难以扩展的特性,使其更多地作为优质补充数据使用。
强LLM自动生成数据:借助GPT-4等大模型,结合ReAct、CoT等策略生成轨迹,效率极高,适合大规模数据构建。但这种数据依赖于大模型,存在成本高昂、偏差传播等问题。
Agent自主探索数据:通过开源模型自主与环境交互生成轨迹,成本低且能摆脱闭源模型的依赖。不过,其探索能力有限,需要配合后续筛选机制来去除低质量数据。
多智能体协作生成数据:通过多个Agent协同完成复杂任务流程,提升数据的多样性和交互复杂度。但这种方法的系统设计更为复杂,稳定性和资源成本也是面临的挑战。
3.其次,数据的评估与过滤。
生成的轨迹数据质量往往存在较大差异,因此对数据进行评估和筛选成为一项关键步骤。
作者将主流的评估方法总结为以下三类:
3.1. 基于环境的评估
这种方法通过任务是否成功、环境奖励等外部反馈来衡量轨迹质量。其优势在于实现简单且自动化程度高,但缺点是反馈信号过于粗略,仅关注最终结果,难以捕捉推理链条中的潜在问题。
3.2. 基于人工或规则的评估
该方法利用预设规则(如任务完成度、答案一致性、多样性等)或专家人工审核,对数据质量进行精细化控制。这种方法具有较强的适配性和较高的准确性,但需要大量的人工参与以及复杂的设计工作。
3.3. 基于模型的评估
借助强大的语言模型(如GPT-4),对轨迹数据进行自动评分和多维度分析,包括相关性、准确性和完整性等方面,从而构建高效的自动化评估框架。然而,这种方法的局限性在于评估过程依赖于模型本身,可能引入额外的偏差.
在轨迹数据的处理中,除了获取高质量样本外,低质量的不合格轨迹同样具有再利用的价值。目前主流的处理策略包括以下几种:
3.4 对比式利用
通过将正确与错误的样本进行对比,帮助模型更清晰地理解哪些行为是有效的,从而提升其判别能力。
3.5错误修正型方法
对失败的轨迹进行识别和修正,将其转化为可用的学习数据,进一步优化训练效果。
3.6 直接利用错误样本
不对失败案例进行修正,而是直接将其用于训练,增强模型在面对错误情境时的容错能力和鲁棒性。
在完成高质量轨迹数据的构建后,接下来的关键步骤是微调阶段。通过这一过程,开源大模型能够更好地适应Agent任务,掌握规划、推理与交互等核心能力,这是优化基于LLM智能体性能的重要环节.
三:基于强化学习的优化
与传统的微调方法相比,强化学习为Agent提供了一条更具主动性的学习路径。
通过强化学习,模型不再局限于“模仿”行为,而是能够在环境中主动探索,接受奖励与惩罚的反馈,并动态调整策略,从而在试错中不断成长。
目前,基于强化学习的优化方法主要分为两类:
--基于奖励函数的优化--
--基于偏好对齐的优化--
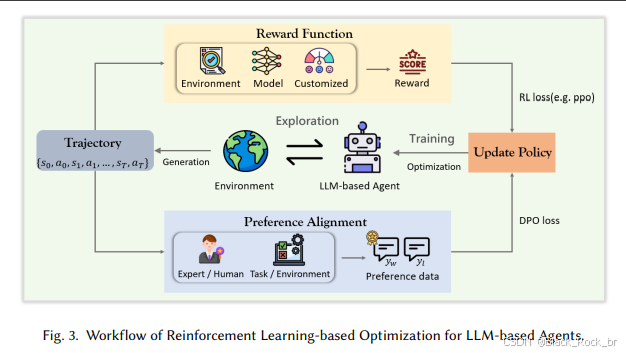
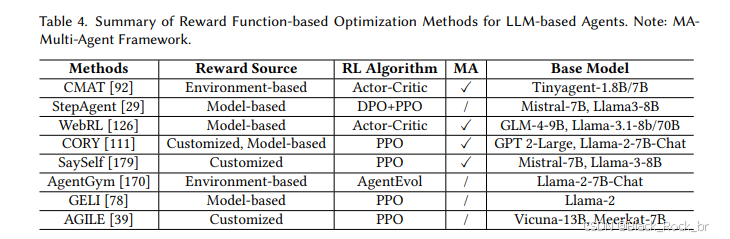
1.首先来看基于奖励函数的优化。
在强化学习中,奖励函数扮演着智能体“指挥棒”的角色,引导模型通过不断调整策略来优化行为。通过明确设定“做得好 vs 做错了”的标准,Agent能够从与环境的交互中更精细、更稳健地学习。
作者根据奖励来源的不同,将当前方法划分为以下三类:
1.1基于环境的奖励
这种方法直接依据任务是否完成来打分,简单直观且自动化程度高。然而,它通常只关注最终结果,忽略了中间步骤的质量,可能无法全面反映任务执行过程中的细节。
1.2. 基于模型的奖励
由大语言模型(LLM)或辅助模型对轨迹进行评估,这种方法特别适用于环境反馈稀疏的场景,能够提供更细致的反馈信号。不过,其效果高度依赖于评估模型的质量,可能存在一定的偏差。
1.3.自定义奖励函数
研究者根据具体任务需求,设计多维度的奖励函数,不仅考核任务完成度,还关注策略的稳定性、协作效率等指标。这种方法灵活且强大,但设计成本较高,且难以在不同任务间泛化.
接下来是基于偏好对齐的优化方法。
与传统强化学习依赖奖励函数的训练方式相比,偏好对齐提供了一条更直接、更轻量化的优化路径。
这种方法不再需要繁琐的奖励建模,而是让Agent学会“哪些行为更符合人类或专家的偏好”,从而提升其输出质量。
其中,代表性方法是**DPO(Direct Preference Optimization)**,这是一种更为简洁的离线强化学习方式。DPO通过人类或专家的偏好数据,直接对样本进行“正负对比”训练,从而实现模型的高效优化.
根据主要偏好数据来源,作者将这类优化方法分为以下两类:
--专家/人工偏好数--:通过专家示范或人类标注来构建正负样本(优质轨迹与错误轨迹对比),数据质量高但难以实现大规模扩展,且覆盖面相对有限。
--任务或环境反馈--:依据任务表现(如成功率、分数等)自动构建偏好对,适用于动态任务场景,但依赖于反馈机制的合理设计。
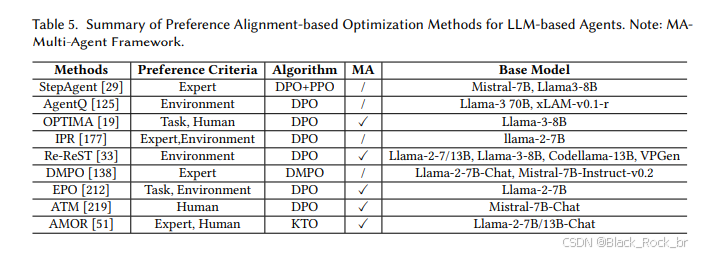
总体而言,偏好对齐方法在训练效率和部署便捷性方面表现出色,不过其效果高度依赖于偏好数据的质量和覆盖范围,更适合那些结构清晰、反馈明确的任务场景。相比之下,奖励函数类方法则更擅长应对复杂多变的环境,但相应的成本也更高。
2.混合参数微调方法
单一的优化方法存在各自的局限性——常规微调虽然稳定高效,但缺乏动态应变能力;强化学习(RL)尽管灵活强大,却伴随着巨大的计算开销。
因此,越来越多的研究开始探索混合微调策略,试图结合两者的优点,从而构建更强大的LLM智能体。这类工作主要分为以下两类:
2.1,顺序式两阶段训练
这是当前的主流方法,采用“先SFT、后RL”的思路。
- 阶段一:行为克隆微调(SFT)
使用专家轨迹或高质量策展数据对模型进行预训练,为其奠定基础能力。
- 阶段二:强化学习优化(PPO / DPO)
在环境反馈或人类偏好基础上,通过强化学习进一步精调模型策略,提升其适应性和表现。
2.2,交替优化
这种方法引入迭代交替机制,在SFT和RL之间进行多轮切换,从而实现细粒度的性能提升。通过不断在行为克隆和强化学习之间调整,模型能够更全面地吸收两种方法的优势,达到更优的效果.
四:参数无关的LLM智能体优化
与参数微调不同,参数无关的优化方法无需更新模型权重,而是通过调整Prompt、上下文设计以及外部信息结构,在资源受限或轻量部署场景中展现出显著的优势。
作者将这类方法归纳为五类核心策略:
第一类:基于经验的优化
通过引入记忆模块或历史轨迹数据,让Agent能够“复盘”过去的行为,从成功与失败的经验中提炼策略,从而增强其长期适应性。
第二类:基于反馈的优化
Agent通过自我反思或外部评估机制不断修正自身行为,形成迭代优化的闭环。此外,部分方法还通过元提示(Meta-Prompt)优化全局指令结构,进一步提升泛化能力.
第三类:基于工具的优化
这种方法让Agent学会使用外部工具(如搜索引擎、计算器、API等)来增强执行能力。一些研究专注于优化工具调用策略,另一些则训练Agent构建更高效的任务-工具映射路径.
第四类:基于RAG的优化
结合检索增强生成(RAG)技术,通过实时从数据库或知识库中获取相关信息,增强推理过程。这种方法在知识密集型任务和动态变化的场景中表现尤为突出.
第五类:多Agent协作优化
多个LLM Agent通过角色分工、信息共享与反馈机制协同完成任务,从而实现“1+1>2”的协同智能效果。这种策略特别适用于复杂任务的分解与执行.
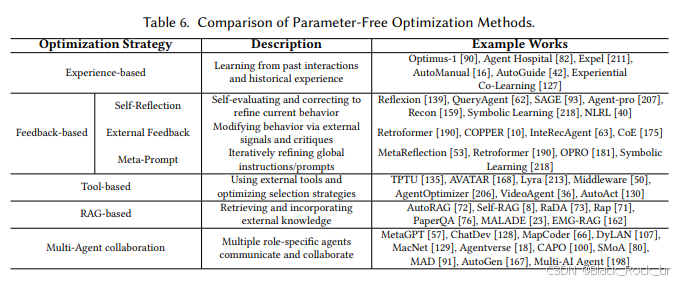
参数无关优化,让LLM Agent在不动模型的前提下,变得更“聪明”、更“适应”、也更“轻巧”。
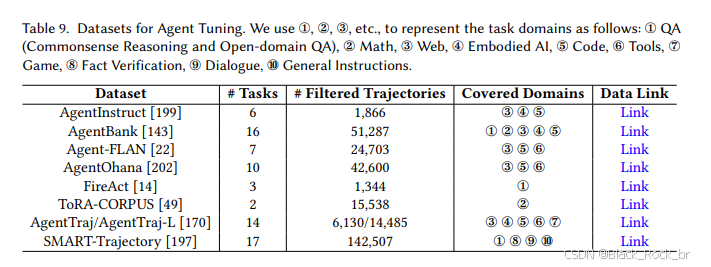
五:数据集与基准
将数据和基准分为用于评估和微调的两个大类。
评估任务分为两类。
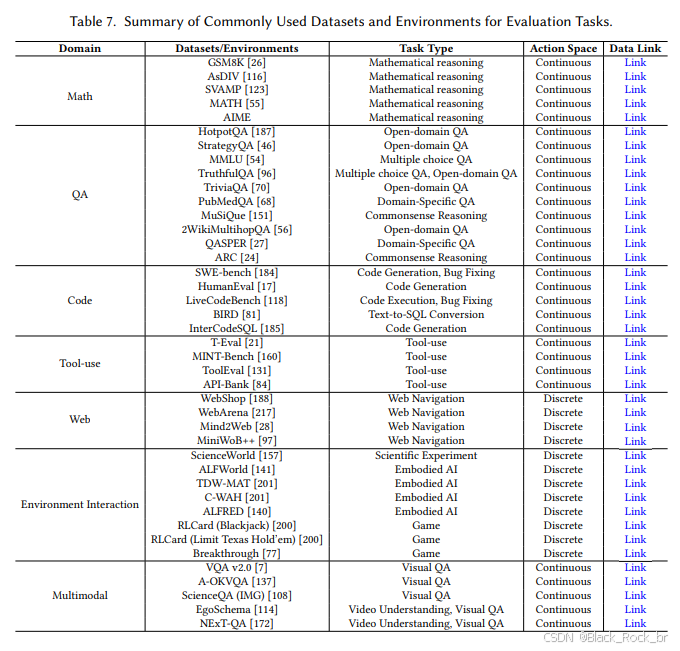
第一类,通用评估任务。
即按一般任务领域分类,如数学推理,问题推理(QA)任务,多模态任务,编程等。
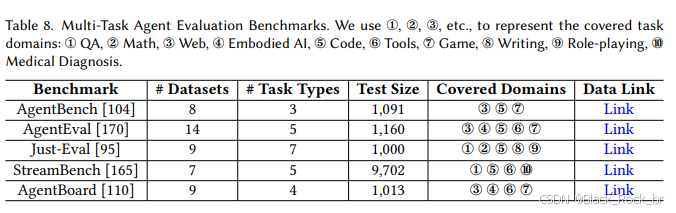
第二类,多任务评估基准。
跨各种任务评估基于LLM的智能体,测试它们概括和适应不同领域的能力。
Agent微调数据集,则是针对Agent微调而精心设计的数据,以提高LLM Agent在不同任务和环境中的能力。
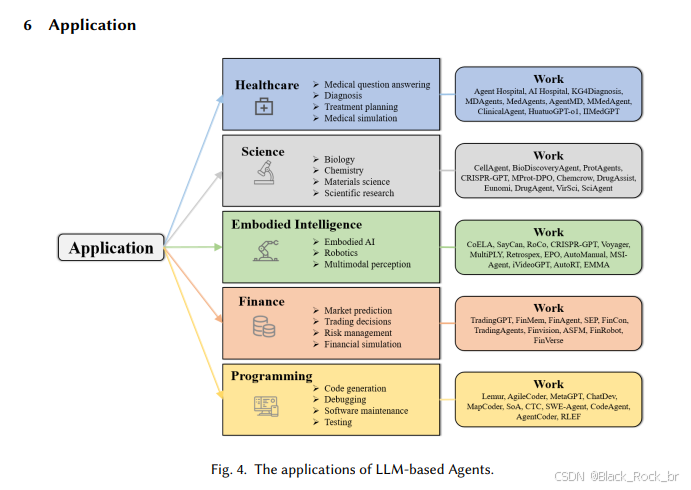
六:应用
随着优化方法的不断成熟,基于LLM的智能体已在多个真实场景中崭露头角,逐渐从实验室走向实际应用:

















 8696
8696

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









