






核心亮点
- V2Edit:无需训练的多功能编辑框架
V2Edit 是一款简单却功能强大的工具,专注于通过指令引导实现视频和3D场景的高效编辑,且无需额外训练。
-协同机制与渐进式编辑
框架引入了一种创新的协同机制,能够系统化地控制视频扩散模型中的去噪过程。同时支持渐进式编辑,在保留原始视频内容完整性的同时,精准完成编辑指令。所有功能整合于一个统一框架中,灵活应对多种编辑需求。
- 高质量与广泛适用性
V2Edit 在各类视频和3D场景编辑任务中表现出色,不仅在现有方法无法解决的复杂任务上展现了卓越能力,还确立了该领域最先进的性能标准,为视频和3D编辑带来了突破性进展。


一:核心速览
1-解决的核心问题
1. 1视频编辑中的技术难题
当前的视频编辑方法在处理时间一致性、快速移动的相机轨迹、复杂运动以及显著的时间变化时面临重大挑战,导致编辑结果不够流畅或自然。
1.2.原始内容保留与编辑目标的平衡
现有的训练自由模型在完成编辑指令时,往往难以有效保留原始视频内容。此外,这些方法通常需要大量超参数调优,增加了使用门槛和复杂性。
1.3 3D场景编辑的一致性问题
传统视频编辑方法在处理大规模相机运动和显著时间变化时,难以生成具有强3D一致性的编辑结果,导致3D场景编辑的质量和真实感不足。
通过针对性地解决上述问题,V2Edit 提供了一种创新且高效的解决方案,显著提升了视频和3D场景编辑的效果与适用性。
2-提出的解决方案
2. 1V2Edit框架:无需训练的指令引导编辑工具
提出了一种创新的、无需训练的框架——V2Edit,用于实现基于指令引导的视频和3D场景编辑。该框架通过简洁的设计实现了多功能性,适用于多种复杂的编辑任务。
2. 2渐进式策略:化繁为简的任务分解
针对复杂编辑需求,采用渐进式策略,将整体任务拆解为一系列更易处理的子任务。每个子任务逐步完成,确保编辑过程既高效又精准,同时兼顾原始内容的保留与目标编辑效果的实现。
2. 3协同控制机制:多维度精细调控
引入协同控制机制,通过对初始噪声、每一步去噪过程中引入的噪声,以及文本提示与视频内容之间的交叉注意力图进行系统化管理,精确控制每个子任务的执行。这一机制有效平衡了编辑指令的完成度与原始内容的忠实度。
2.4 “渲染-编辑-重建”流程:从视频到3D场景的扩展
为了将视频编辑能力延伸至3D场景编辑,提出了一种“渲染-编辑-重建”方法。首先,通过固定相机轨迹渲染3D场景生成视频;接着,利用视频编辑技术对渲染结果进行修改;最后,根据编辑后的视频重建3D场景,从而实现高质量的3D内容编辑。
通过以上方案,V2Edit在视频和3D场景编辑领域展现了强大的通用性和卓越的性能。
3-采用的核心技术
3.1.视频扩散模型:无需训练的高效编辑基础
借助预训练的视频扩散模型,实现无需额外训练的视频编辑能力,为复杂任务提供强大的技术支持。
3.2.噪声调度器:语义信息传递与低频特征保留
通过逐步添加噪声的方式,在编辑过程中有效传递语义信息,同时保留原始视频的低频特征,确保内容的自然过渡和高质量输出。
3.3. 交叉注意力图:精准控制原始内容保留
在去噪阶段,利用模型的交叉注意力图动态调整原始内容与编辑指令之间的平衡,实现对原始视频细节的精确保留。
3.4. 3D一致性重建:时间一致性的强3D效果保障
通过渲染视频的时间一致性特性,确保从编辑后的视频重建的3D场景具有高度的空间和时间一致性,从而生成逼真且连贯的3D效果。
这些技术的有机结合,使V2Edit在视频和3D场景编辑中展现出卓越的性能和广泛的适用性。
4-实现的效果
4.1. 高质量视频编辑:应对复杂场景的卓越表现
V2Edit 在多种高难度视频编辑任务中展现了强大的能力,能够轻松处理更长的视频、更快的相机运动以及更大的时间变化,生成流畅且高质量的编辑结果。
4.2. 高质量3D场景编辑:突破性支持显著几何变化
该框架支持复杂的几何变化(如对象插入等操作),这是现有3D场景编辑方法难以实现的功能,为3D内容创作带来了全新的可能性。
4.3. 高效编辑:快速收敛与自动化处理
V2Edit 无需耗时的逐视图调整,通过高效的渐进式策略和协同控制机制,确保快速收敛,大幅提升了编辑效率,节省了时间和人力成本。
4.4. 行业领先的性能:树立新标杆
在视频和3D场景编辑领域,V2Edit 凭借其创新的技术方案和卓越的编辑效果,确立了最先进的性能标准,成为当前领域的领先者。
通过这些优势,V2Edit 不仅解决了传统方法的痛点,还为视频和3D编辑开辟了更广阔的应用前景。
二:方法概述
V2Edit 借助预训练的视频扩散模型作为核心,构建了一个多功能的视频编辑框架,无需依赖配对数据集进行特定任务的训练。如下图2所示,该框架采用渐进式编辑策略,将复杂的编辑任务分解为多个更易于处理的子任务,逐步完成编辑目标。
为了在实现高质量编辑的同时有效保留原始视频内容,本文提出了一种无需训练的保留控制机制。该机制通过对扩散过程中的三个关键要素进行系统化管理,确保编辑结果的精准性和一致性:
1. 初始噪声:用于初始化编辑过程,奠定基础内容结构;
2. 去噪步骤中添加的噪声:在每一步去噪过程中动态调整,传递语义信息并优化编辑效果;
3. 文本提示与视频内容的交叉注意力图:通过注意力机制精确控制编辑指令与原始内容之间的平衡。
这一方法通过统一的保留控制策略,避免了繁琐的超参数调优,能够在高效应用编辑指令的同时,稳健地保留视频的原始元素,从而实现高质量的编辑输出。
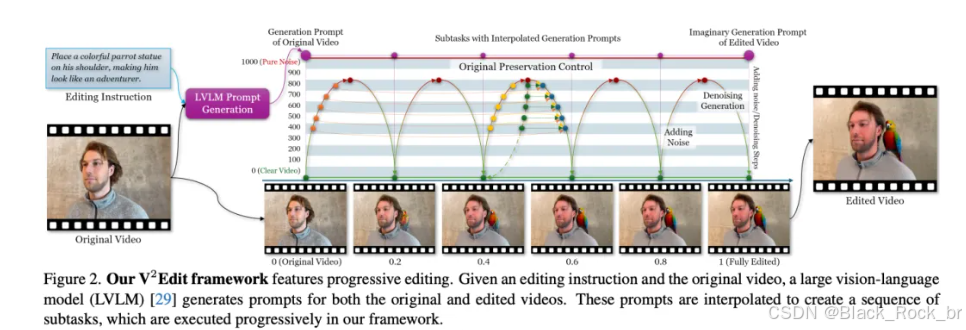
提示生成方法
本文利用大视觉语言模型(LVLMs)将用户输入的编辑指令转化为两个描述性提示:一个用于描述原始视频内容,另一个用于描述编辑后的目标效果。这一过程至关重要,因为大多数文本到视频扩散模型需要明确的提示来理解视频内容本身。通过生成这些定制化的提示,V2Edit 框架能够引导底层扩散模型精准执行指令驱动的编辑任务,同时有效保留原始视频的结构与完整性,确保编辑结果既符合预期又自然流畅。
原始内容保留的控制机制
为了在编辑过程中有效保留原始视频内容,V2Edit 引入了三种相互补充的控制机制:
1. 初始噪声控制:通过管理扩散过程中的初始噪声,保留视频的低频信息,确保基础结构的完整性;
2. 去噪噪声调节:在每一步去噪过程中动态调整添加的噪声,以保护语义细节,避免关键信息丢失;
3. 交叉注意力图对齐:利用交叉注意力图强化文本提示与视频内容之间的对齐关系,确保编辑指令与原始内容的协调性。
这三种机制协同作用,在实现高效编辑的同时,最大限度地保留了原始视频的核心元素,从而在各类复杂编辑任务中展现出稳定且高质量的表现。下图3展示了本文保留控制方法的可视化效果。
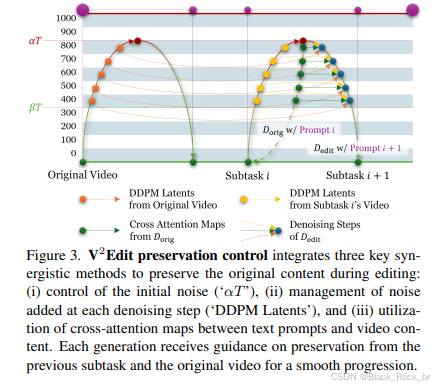
基本公式与控制机制
扩散模型生成视频的基本框架

初始噪声控制

每步噪声控制

生成控制的交叉注意力图

控制机制之间的协同作用

视频编辑全流程

基于进展的编辑过程
不同编辑任务对原始内容保留的需求各不相同。简单的编辑任务在较低或较高的保留控制下都能成功,而复杂任务(如显著改变外观)可能因保留控制过于严格而失败。为适应这种需求变化,V2Edit 采用了一种**基于进展的策略**,将复杂任务分解为一系列更简单的子任务。由于每个子任务较为简单,更容易在保留原始内容和完成编辑目标之间取得平衡,从而可以应用一致的保留控制策略,无需针对不同任务单独调整。
如上图2和图3所示,在每个子任务中,V2Edit 同时执行两个生成过程:
1. 使用原始提示重新生成当前子任务视频;
2. 使用编辑提示生成下一个子任务视频。
其中,第二个生成过程由从原始视频中提取的**交叉注意力图**和**DDPM隐空间变量**指导,并通过混合系数进行调节。
通过这种双重指导机制,V2Edit 在每个子任务中逐步完成编辑目标,确保高质量和语义一致性。该方法有效平衡了原始内容保留与编辑指令的完成,实现了子任务间的平滑过渡,避免了设计复杂多级控制机制的麻烦。
V2Edit 不仅具备出色的原生视频编辑能力,还通过“渲染 - 编辑 - 重建”(RER)流程,实现了高效的 3D 场景编辑。具体来说,先沿固定相机轨迹渲染原始场景视频,再利用 V2Edit 进行编辑,最后从编辑后的视频重建并重新渲染场景。为保障 3D 一致性,文中对渐进式编辑框架进行了调整,让每个子任务的编辑视频都能重建为 3D 并重新渲染,供下一子任务使用。这种调整借助了渲染视频的时间平滑性和重建的 3D 一致性,确保编辑视频 3D 一致性强劲。与以往需反复迭代更新数据集、额外训练的 3D 编辑方法不同,本文方法稳定高效,仅需少量扩散生成就能达成高质量编辑。而且,编辑视频的时间一致性使得进行显著几何变化(如对象插入)成为可能,此前因每视图编辑结果不一致,这类操作一直颇具挑战。
实践综述:
实验设置
V2Edit 配置
- 底层模型:采用 CogVideoX-5b 作为视频扩散模型,这是一个基于 Diffusion Transformer (DiT) 的文本到视频生成模型,支持类似 SORA 的长描述提示。
- 提示生成:使用 GPT-4o(大型视觉语言模型)为 CogVideoX 生成输入提示。
- 渐进式框架:每个编辑任务最多分解为 6 个子任务,确保复杂任务的逐步完成。对于 3D 场景编辑,V2Edit 独立于具体场景表示方法,选择 NeRFStudio 中的 SplactFacto 或 NeRFacto 作为场景表示。
视频编辑任务
- 数据集:与先前工作一致,使用 DAVIS 数据集中的视频作为源视频。
- 任务生成:由 GPT-4o 根据原始视频内容生成评估任务。
- 基线对比:
- 基于图像的方法:如 Slicedit、Instruct 4D-to-4D(单目场景),这些方法依赖底层图像生成模型。
- 基于视频的方法:包括 CogVideoX-V2V、VideoShop、StableV2V、AnyV2V、BIVDiff(逐帧编辑和整体优化)、CSD 等。
- 对于需要第一帧指导的方法,统一使用 Instruct-Pix2Pix 生成初始帧。
3D 场景编辑任务
- 数据集:主要使用 Instruct-NeRF2NeRF (IN2N) 数据集中的场景进行评估,并引入 NeRFStudio 的户外场景作为更具挑战性的测试任务。
- 相机轨迹:对于 IN2N 数据集,使用官方提供的轨迹;对于其他场景,手动绘制相机轨迹。
- 基线对比:与最先进的 3D 场景编辑方法进行比较,包括 Instruct-NeRF2NeRF (IN2N)、Efficient-NeRF2NeRF 和 V2Edit。
消融研究
为了验证关键组件的效果,本文设计了以下 V2Edit 变体进行消融实验:
1. CogVideoX-V2V:仅使用 CogVideoX 作为底层视频扩散模型,不应用其他控制机制。
2. No Progression (NP):移除渐进式策略,在无进展的情况下单独应用原始保留控制。
---
评估指标
- 多维度评估:从整体视觉质量、原始内容保留和编辑指令完成度三个方面对视频编辑任务进行评价。
- GPT-4o 评分:
- 提供编辑要求、指令及原始/编辑后视频的逐帧内容,要求 GPT-4o 对每个方面打分(1-100 分)。
- 为确保一致性,多个视频同时提交给 GPT-4o 进行评分,并取 20 次独立评估的平均值作为最终结果。
- 辅助评估方法:
- 用户研究:收集用户主观反馈。
- 基于 CLIP 的量化指标:包括 CLIP 文本-图像方向相似性 (CTIDS) 和 CLIP 方向一致性 (CDC),用于补充客观评价。
实验结果
视频编辑:在 DAVIS数据集上的视频编辑可视化结果如下图4所示,更多结果请参见本项目网站。

V2Edit 在面对各种充满挑战的任务时,始终能够出色地完成编辑工作,并生成高保真度的结果。例如,为摩托车手添加一个火焰环让他穿越,或者将快速移动的人变成蝙蝠侠;同时,它还成功地保留了与编辑任务无关的部分,比如在“蝙蝠侠”任务中,网球场的墙壁和布局以及网球运动员的动作得以保留;在“猪”任务中,农场中的物体得以保留;在“天鹅”任务中,河流也得到了保留。相比之下,每个基线方法要么无法完成编辑任务,要么无法保留原始场景中的无关部分,尤其是原始的姿势和动作。值得一提的是,基线方法 CogVideoX-V2V 是在 CogVideoX 上应用 SDEdit 的官方方法,可以视为本文方法的一个变体。该基线方法生成的视频虽然外观良好,但却未能保留原始场景中的大部分信息。这进一步证明了本文保留控制方法的关键性。由此可见,高质量的编辑结果并非源于本文所使用的强大底层 CogVideoX,而是源于本文新颖的原始保留和进展流程。
在 3D 场景编辑方面,结果如图 5 和图 6 所示,更多结果可访问本文项目网站查看。如图 5 所示,V2Edit 在包含显著几何变化的挑战性编辑任务中取得了成功,生成的视频具有清晰的外观和合理的几何结构,尤其是在“小狮子”编辑任务中表现优异。在对象插入任务中,所有基线方法均未能完成大多数任务,要么无法满足编辑要求,要么完全改变了原始场景的外观,或者两者兼而有之。除了面向正面的场景外,V2Edit 在图 6 中的室内或室外场景中也表现出色,能够很好地完成编辑指令并保留原始场景。值得一提的是,通过本文之前自行实现的基于 Flash Attention 的加速技术,编辑一个 72 帧的视频在渐进式框架中每个子任务仅需 10 分钟。因此,一个最多包含六个进展子任务的编辑任务仅需大约一到两个小时即可完成,实现了与简单基线相当的效率,但生成的结果却显著更优。

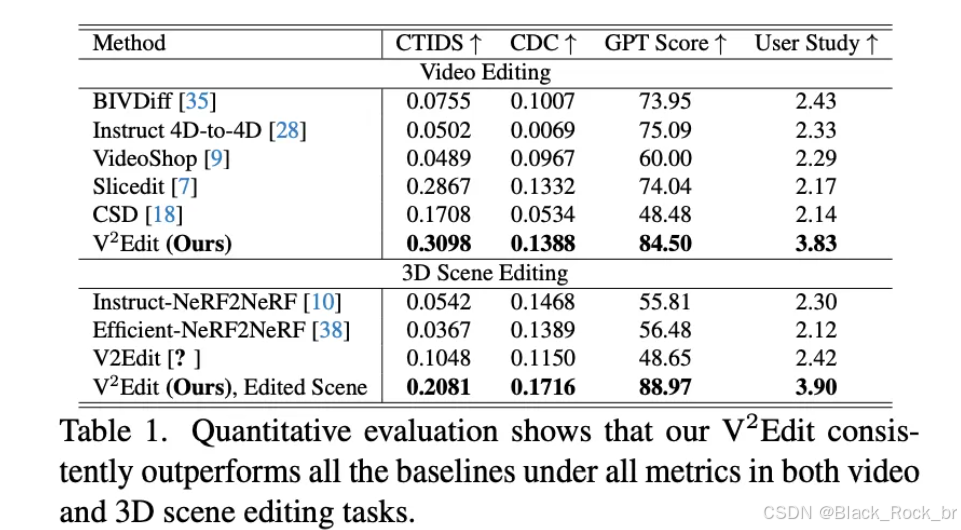
定量评估:本文在几个具有代表性的编辑任务上进行了定量评估,结果如下表1所示,包括一项涉及43名参与者的用户研究,以评估主观质量。本文 V2Edit 在视频和3D场景编辑的所有指标上均一致优于所有基线方法。具体而言,V2Edit 成功平衡了原始内容保留(通过“CDC”指标量化原始场景与编辑场景之间的相邻帧相似性)和编辑任务完成度(通过基于 GPT 的评估和用户研究结果证明)。这些发现确立了 V2Edit 在视频和3D场景编辑领域的最先进地位。
消融研究:如上图4所示,基线方法 CogVideoX-V2V 在各种编辑任务中生成了高质量视频,但始终无法保留原始视频中的无关内容。该基线有效地代表了仅使用初始噪声控制的 V2Edit 变体。这些结果表明,仅依靠强大的视频扩散模型不足以实现高质量编辑,必须结合有效的内容保留机制,这凸显了本文保留控制策略的必要性。此外,如下图7所示,在没有进展框架的情况下直接应用本文内容保留机制会导致复杂任务(例如添加时钟)失败。相比之下,当结合基于进展的编辑策略时,V2Edit 成功构建并优化了时钟,实现了高质量结果。值得注意的是,时钟指针在所有视图中保持一致,展示了出色的3D一致性。这些实验验证了本文内容保留机制和进展框架都是必不可少的,它们不仅确保了内容保留,还实现了编辑任务的完成。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









