






未来引言:
当前,OpenAI的Sora代表着AI视频生成解决方案的技术标杆。成功部署该项目后,用户能够实现高质量视频和图像的自主生成,从而完全摆脱对商业化AI生成服务的依赖。与市面上主流平台相比,Sora不仅具备更强大的生成能力,还突破了传统服务等待时间过长的瓶颈。通常情况下,传统服务生成视频可能需要数小时甚至更久,而Sora则能显著缩短这一时间,为用户提供更高效、更可控的创作体验。
一:部署技能的硬件需求:
硬件【显存】有一定要求:
推荐:16/24GB
至少:8GB
https://github.com/hpcaitech/Open-Sora
当我们浏览md文档后,就会发现,和大多数github项目一样,第一步就是安装环境。一般我们使用conda多一些,所以,我们依然选择conda安装。然而,过程中却报错了...真的让人很崩溃。具体如下:
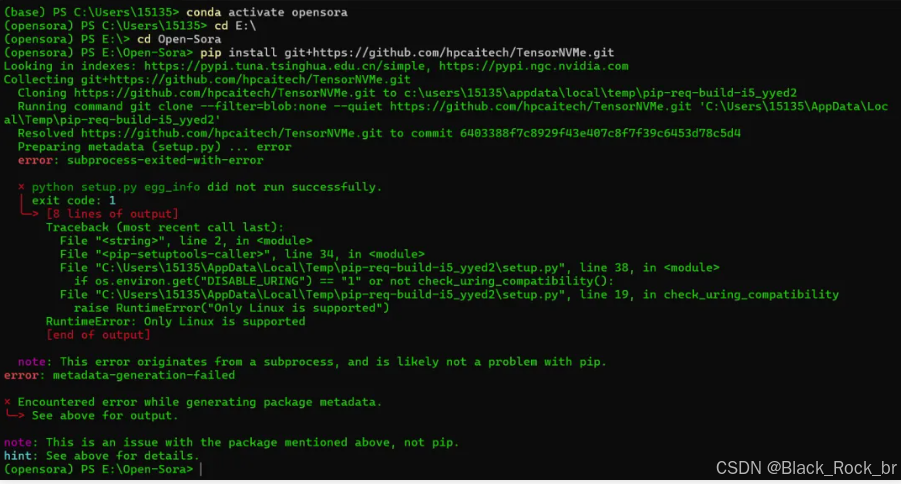
这个时候,我们就可以使用Docker容器了。恰巧的是,官网提供的方法中,除了conda,也有docker。
首先,我们需要进入到官网,安装Docker Desktop。
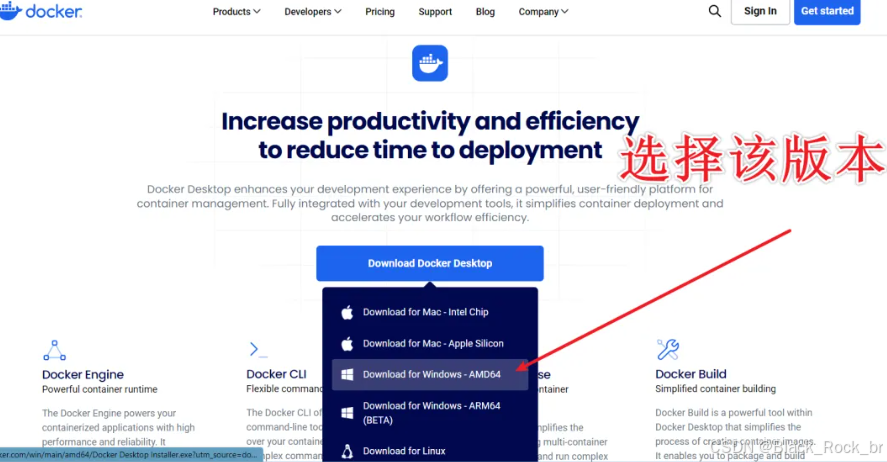
下载后,双击运行Docker Desktop Installer.exe。就会进入到下面这个界面,提示的unpacking files意思是:解压文件中。
这个过程,大约持续5分钟,还是比较快的,结束后的界面如下:
然后点击close,我们就会在桌面上看到一个图标:’
下面,我们双击运行。点击accept。
然后,就会弹出一个登陆界面,长下面这样:
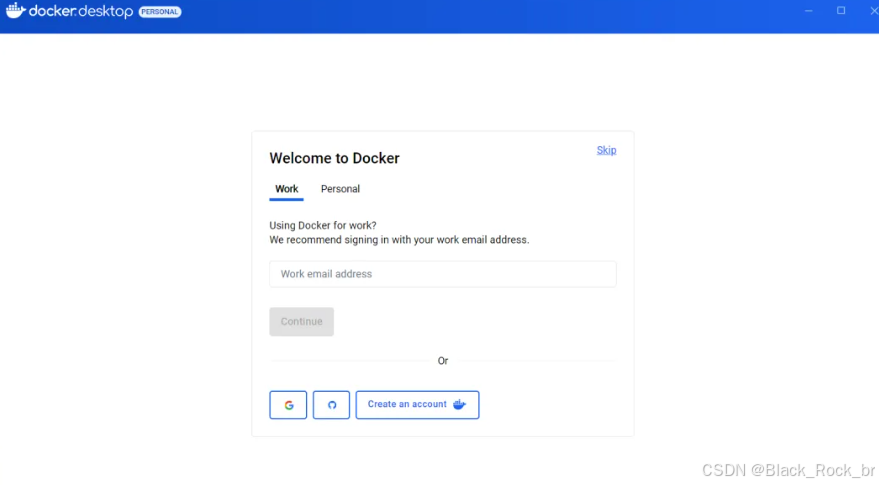
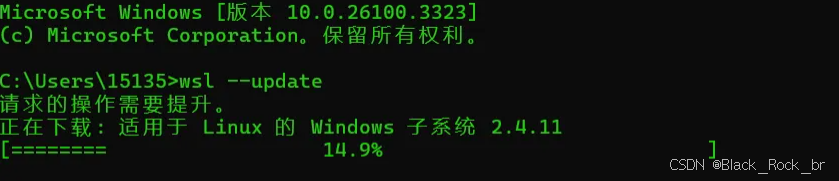
我们可以按照提示打开cmd窗口,输入命令
wsl --update
# 列出所有 WSL 发行版wsl -l -v# 设置 WSL2为默认版本wsl --set-default-version 2

二:项目构建:
第一步,我们已经实现了github项目下载,命令如下:
git clone https://github.com/hpcaitech/Open-Sora然后,我们在cmd中进入下载好的项目文件夹。并且执行以下步骤:
-
创建Dockerfile【由于项目文件夹下已经存在,我们跳过该步】
-
构建Docker镜像
-
运行Docker容器
构建容器命令如下
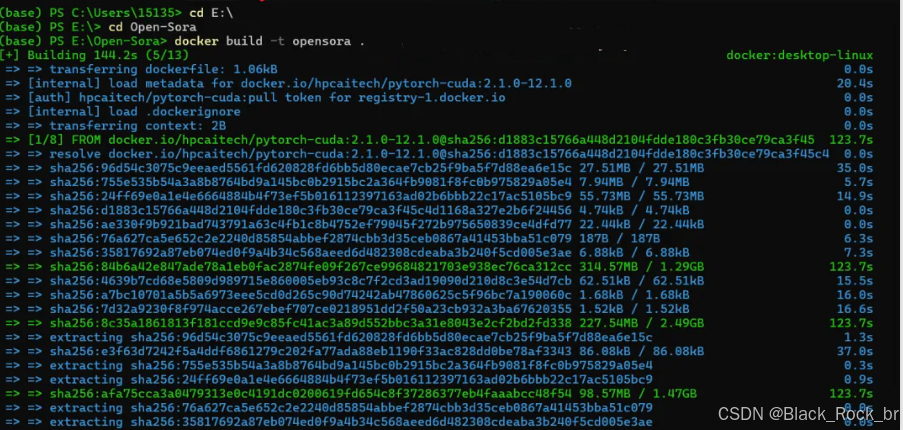
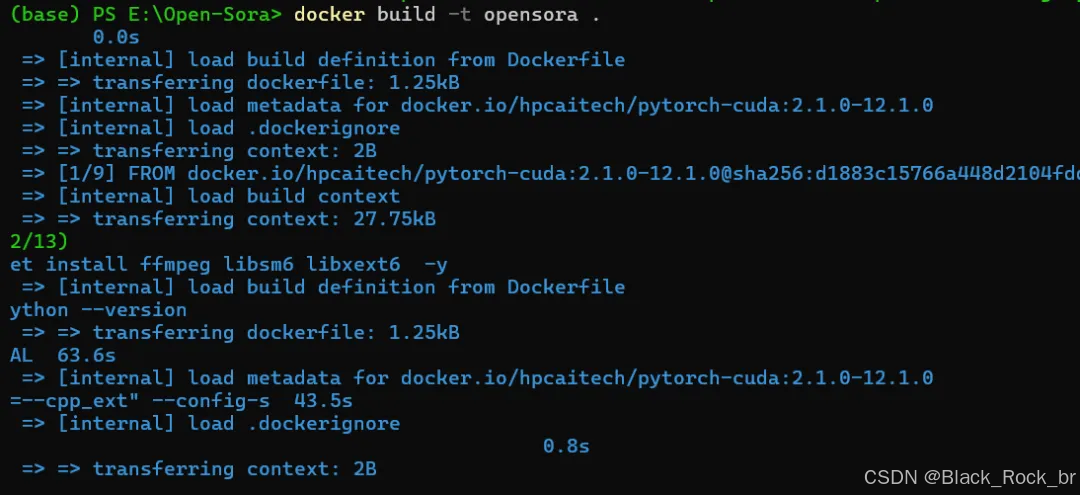
docker build -t opensora .
可以看到这个过程比较耗时,因为是在下载各种依赖包,有的包比较大,好几个G。
不同颜色表示下载完成与否,比如,我的界面上,蓝色表示下载完成,绿色表示正在下载中。在最上面还能看到下载的整理进度。
项目结束后,我们在docker界面端就可以看到,最后一次构建的前面是一个绿色√。
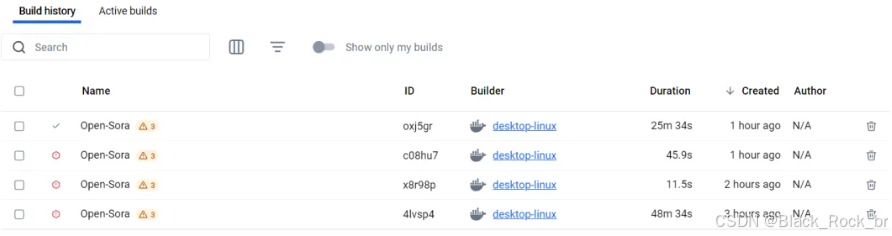
三:启动
我们使用如下命令,来启动刚才构建好的docker容器:
docker run -ti --gpus all -v .:/workspace/Open-Sora opensora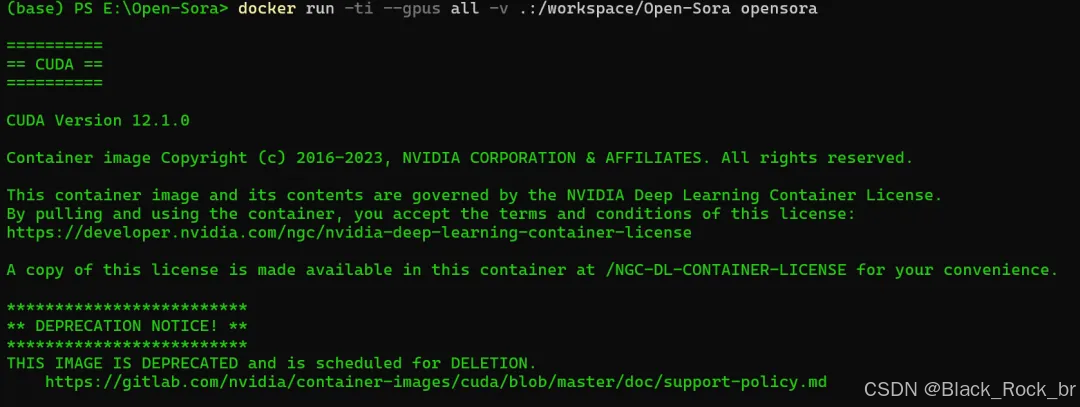
(base) PS E:\Open-Sora> docker run -ti --gpus all -v .:/workspace/Open-Sora opensora============ CUDA ============CUDA Version 12.1.0Container image Copyright (c) 2016-2023, NVIDIA CORPORATION & AFFILIATES. All rights reserved.This container image and its contents are governed by the NVIDIA Deep Learning Container License.By pulling and using the container, you accept the terms and conditions of this license:https://developer.nvidia.com/ngc/nvidia-deep-learning-container-licenseA copy of this license is made available in this container at /NGC-DL-CONTAINER-LICENSE for your convenience.*************************** DEPRECATION NOTICE! ***************************THIS IMAGE IS DEPRECATED and is scheduled for DELETION.https://gitlab.com/nvidia/container-images/cuda/blob/master/doc/support-policy.md(pytorch) root@2197582a12c1:/workspace/Open-Sora#
可以看到,我们已成功启动了一个支持GPU的Docker容器,并进入了项目工作目录。接下来,就可以根据项目文档安装依赖、下载模型、运行代码等。
四:本地使用
打开文件configs/opensora-v1-3/inference/t2v.py,找到 text_encoder 配置部分,修改 from_pretrained 为正确的路径或 Hugging Face 模型名称。
下面,我们使用Open-Sora 1.3 Command Line Inference进行本地预测,直接再命令行中运行以下代码:
from_pretrained="google/t5-v1_1-xxl", #修改后模型
# text to videopython scripts/inference.py configs/opensora-v1-3/inference/t2v.py \--num-frames 97 --resolution 720p --aspect-ratio 9:16 \--prompt "a beautiful waterfall"
为了节约时间,初步看下效果。我们先使用Open-Sora 1.2 Command Line Inference进行本地预测,cmd中运行以下代码
# text to videopython scripts/inference.py configs/opensora-v1-2/inference/sample.py \--num-frames 4s --resolution 720p --aspect-ratio 9:16 \--prompt "a beautiful waterfall"
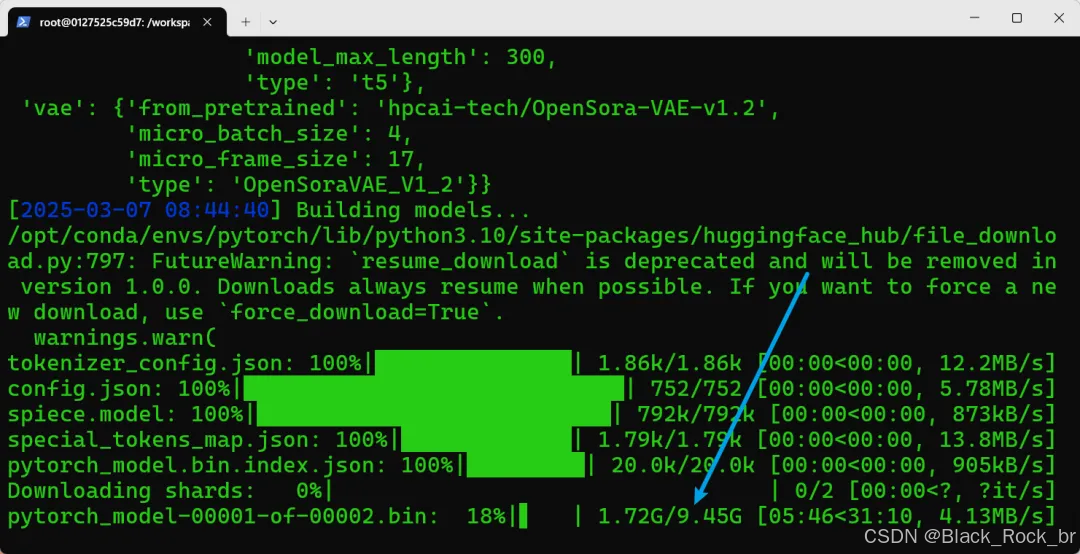
如果报错,说明GPU的显存不够跑通。
如果顺利可以生成你用text文字的生成视频,
小伙伴有gpu适配可以试试!


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









