






微软在其官方网站上宣布了视觉解析框架 OmniParser 的最新版本 V2.0。该版本能够将 DeepSeek-R1、GPT-4o、Qwen-2.5VL 等模型转化为可在计算机上使用的 AI 代理。
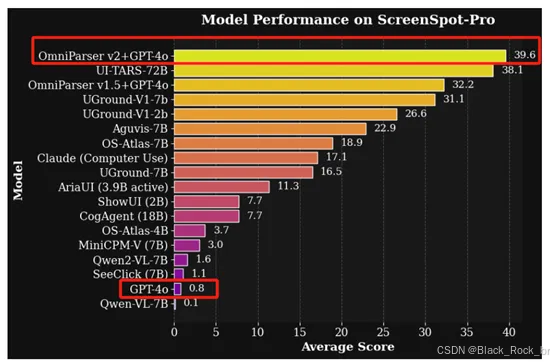
与 V1 版本相比,V2 在检测较小的可交互 UI 元素方面表现更为出色,准确率更高,推理速度更快,延迟大幅降低了 60%。在高分辨率 Agent 基准测试 ScreenSpot Pro 中,V2 与 GPT-4o 结合使用时,准确率达到了令人惊叹的 39.6%,而 GPT-4o 单独使用时的原始准确率仅为 0.8%,整体性能提升显著。
除了 OmniParser V2.0,微软还开源了 Omnitool。这是一个基于 Docker 的 Windows 系统,具备屏幕理解、定位、动作规划和执行等功能,是将大型模型转化为 AI 代理的关键工具。
OmniParser V2简单介绍
目前,将大模型变成Agent的关键难点在于,需要能够可靠地识别用户界面中的可交互图标,同时必须理解截图中各种元素的语义,并准确将预期动作与屏幕上的对应区域关联起来。
而V2通过将用户界面从像素空间“标记化”解析为结构化元素,使得大模型能够理解和操作这些元素。这有点类似于自然语言处理中的分词操作,但针对的是视觉信息。通过这种方式,大模型可以在解析后的可交互元素集合上进行基于检索的下一步动作预测。
OmniParser核心架构
OmniParser的核心思想是将用户界面的视觉信息,转化为易于理解和操作的结构化数据。不过这个过程比较复杂,需要多个模块协作才能完成。
首先,OmniParser需要从用户界面截图中识别出所有可交互的元素,例如,按钮、图标和输入框等。这些元素是用户与界面交互的基础,因此准确地检测它们是至关重要的第一步。
接下来,OmniParser不仅要识别这些元素的位置,还要理解它们的功能和语义。例如,一个带有三个点的图标可能表示“更多选项”,而一个放大镜图标则可能代表“搜索”。这种对功能的深入理解,才能使得大模型能够更准确地预测用户可能需要执行的操作。
为了实现这些目标,OmniParser采用了多阶段的解析流程。在第一阶段,可交互区域检测模块利用深度学习技术,从用户界面截图中识别出所有可能的交互点。这一模块的训练数据集,包含了来自流行网页的67,000张独特截图,每张截图都标注了从DOM树中提取的可交互区域的边界框。
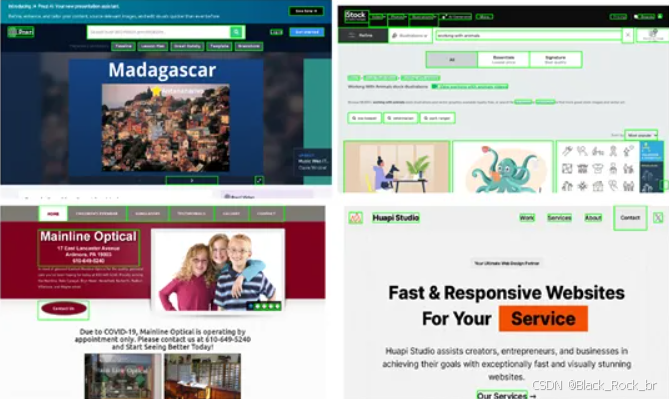
但仅仅识别出可交互元素的位置是不够的。在复杂的用户界面中,一个按钮的形状和颜色可能与其他按钮相似,其功能却截然不同。所以,OmniParser内置了功能语义模块。
该模块的目标是为每个检测到的图标生成一个描述其功能的文本。微软开发了一个包含7,185个图标描述对的数据集,并使用BLIP-v2模型对其进行微调,能够更准确地描述常见应用图标的语义信息。
OmniParser的第三个重要模块是结构化表示与动作生成模块。这一模块将前两个模块的输出整合在一起,形成一个结构化的、类似DOM的UI表示。不仅包含了叠加了边界框和唯一ID的截图,还包含了每个图标的语义描述。
这可以帮助DeepSeek-R1、GPT-4o、Qwen-2.5VL等模型更轻松地理解屏幕内容,并专注于动作预测。例如,当任务是“点击设置按钮”时,OmniParser不仅提供了设置按钮的边界框和ID,还提供了其功能描述,颗显著提高了模型的准确性和鲁棒性。
简单来说,你可以把V2看成是大模型的“眼睛”,可以让其更好地理解和操作复杂的用户界面。
开源地址:https://huggingface.co/microsoft/OmniParser-v2.0
Github:https://github.com/microsoft/OmniParser/
https://github.com/microsoft/OmniParser/tree/master/omnitool


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









