






引言:
我们非常兴奋地向大家介绍Unsloth中的推理功能!DeepSeek的R1研究揭示了一个“顿悟时刻”,即R1-Zero通过使用组相对策略优化(GRPO)自主地学会了在没有人类反馈的情况下分配更多思考时间。
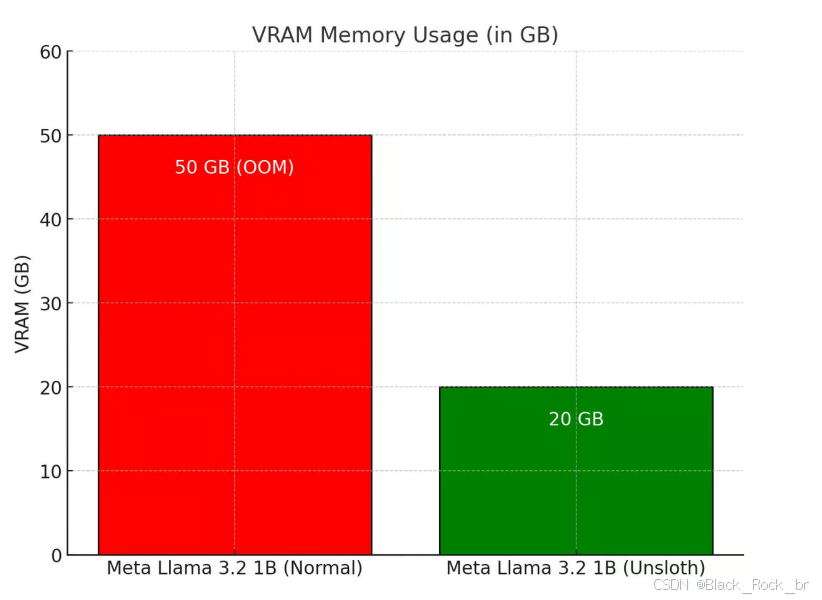
我们对整个GRPO流程进行了增强,使其比Hugging Face + FA2少用80%的显存。这使得你可以在仅7GB显存的情况下,使用Qwen2.5(1.5B)复现R1-Zero的“顿悟时刻”。
试用我们的免费GRPO笔记本:在Colab上运行的Llama 3.1(8B) 若想查看包含Phi-4等其他模型的GRPO笔记本和指南,请访问我们的文档。
http://www.github.com/unslothai/unsloth
GRPO + “Aha”时刻
DeepSeek的研究人员在使用纯粹的强化学习(RL)训练R1-Zero时,观察到了一个“顿悟时刻”。该模型学会了在没有任何人类指导或预定义指令的情况下,通过重新评估其最初的方法来延长思考时间。
在一个测试示例中,尽管我们仅使用GRPO对Phi-4进行了100步的训练,但结果已经十分明显。未使用GRPO的模型没有思考令牌,而经过GRPO训练的模型不仅拥有思考令牌,还给出了正确答案。

通过GRPO重现这一神奇时刻
GRPO是一种强化学习算法,它能够高效地优化响应,而无需依赖价值函数,这与依赖价值函数的近端策略优化(PPO)不同。在我们的笔记本中,我们使用GRPO来训练模型,目标是让模型自主地发展出自我验证和搜索能力,从而创造出一个小小的“顿悟时刻”。
工作原理:
-
模型生成一组响应。
-
每个响应根据正确性或其他由某些设定的奖励函数创建的指标进行评分,而不是基于大型语言模型奖励模型。
-
计算该组响应的平均得分。
-
将每个响应的得分与组平均得分进行比较。
-
模型被强化以偏好得分更高的响应。
举例说明:
假设我们希望模型解决以下问题:
1+1等于多少?>>思考过程/计算过程>>答案是2。
2+2等于多少?>>思考过程/计算过程>>答案是4。
过去,人们需要收集大量的数据来填充思考过程/计算过程。但DeepSeek使用的GRPO算法或其他强化学习算法可以引导模型自动展现推理能力并创建推理痕迹。相反,我们需要创建良好的奖励函数或验证器。例如,如果它得到了正确答案,就给它1分。如果有些单词拼写错误,就减去0.1分。等等!我们可以提供许许多多的函数来奖励这个过程。
使用GRPO
如果你在本地使用Unsloth进行GRPO训练,请务必安装“diffusers”,因为它是GRPO的一个依赖项。
至少等待300步,让奖励真正增加,并且请使用最新版本的vLLM。请注意,我们在Colab上的示例仅训练了一个小时,因此结果不尽如人意。为了获得良好的结果,你需要至少训练12小时(这就是GRPO的工作方式),但请记住这并不是强制性的,因为你可以随时停止训练。
建议至少将GRPO应用于参数量为15亿的模型,以正确生成思考令牌,因为较小的模型可能无法生成。如果你使用的是基础模型,请确保你有一个聊天模板。GRPO的训练损失跟踪现在已直接集成到Unsloth中,消除了对外部工具(如wandb等)的需求。
除了增加对GRPO的支持外,我们还相继支持了在线DPO、PPO和RLOO!更多细节可以在Keith的帖子和博客中看到,其中包含了他如何让在线DPO运行的GitHub分支。GRPO在Google Colab上的最初修改草案也可以在Joey的推文中看到!他们的贡献使我们也能为其他基于生成的强化学习方法提供支持。以下是Unsloth的在线DPO显存消耗与标准Hugging Face + FA2的图表对比。
以下是使用GRPO的总结:
一、优势方面
-
高效优化
-
GRPO作为一种强化学习算法,在优化响应方面表现出色。它无需依赖价值函数,这与传统的近端策略优化(PPO)不同。例如,在训练语言模型时,GRPO能够直接根据奖励函数对模型的输出进行评分和优化,而不需要先估计一个复杂的价值函数来评估每个状态的价值,从而提高了训练效率。
-
-
节省显存
-
使用GRPO可以显著减少显存的使用。与Hugging Face + FA2相比,它能够节省80%的显存。这对于资源有限的用户来说非常有吸引力。比如,一些小型研究团队或者个人开发者可能只有有限的计算资源,GRPO使得他们能够在较低配置的硬件上(如只有7GB显存的设备)复现先进的模型训练成果,像R1 - Zero的“顿悟时刻”就可以在7GB显存下通过Qwen2.5(1.5B)模型来实现。
-
-
自主发展能力
-
模型在GRPO训练过程中能够自主地发展出自我验证和搜索能力。以数学问题求解为例,模型可以学会生成思考令牌,就像人类解题时的思考过程一样。它会先产生一组响应,然后根据奖励函数对每个响应进行评分,通过比较每个响应的得分与组平均得分来强化自身,从而逐渐学会正确的推理和验证过程,这有助于模型更好地理解和解决问题。
-
-
适用性广
-
GRPO可以应用于多种模型。从简单的模型到复杂的模型,如Phi - 4等,都可以通过GRPO进行训练。并且它对于模型的参数量要求相对灵活,虽然建议至少应用于参数量为1.5B的模型来正确生成思考令牌,但对于一些较小的模型,也可以通过适当的调整和优化来使用GRPO,这使得它在不同的应用场景中都有广泛的适用性。
-
-
易于集成和使用
-
在Unsloth等平台中,GRPO的使用变得相对简单。用户只需要按照平台的指南进行操作,例如在本地使用Unsloth进行GRPO训练时,安装必要的依赖项(如“diffusers”),并且使用最新版本的vLLM等。而且训练损失跟踪等功能已经直接集成到了Unsloth中,用户无需再使用外部工具,降低了使用门槛。
-
-
拓展性强
-
GRPO的出现还为其他基于生成的强化学习方法的支持奠定了基础。在Unsloth中,除了GRPO外,还相继支持了在线DPO、PPO和RLOO等方法。这表明GRPO的架构和理念具有很强的拓展性,能够方便地与其他强化学习技术相结合,为未来的模型训练和优化提供了更多的可能性。
-
二、使用注意事项
-
训练时间
-
要获得良好的训练结果,需要一定的训练时间。虽然在一些快速的测试示例中(如在Colab上仅训练一个小时的模型)可能无法得到理想的结果,但通常需要至少12小时的训练时间来让模型充分学习和优化。用户需要有耐心,并且合理安排训练时间,以确保模型能够达到预期的性能。
-
-
模型选择
-
对于较小的模型,可能无法很好地生成思考令牌。因此,在选择模型时,要根据具体的任务和目标来确定模型的规模。如果任务需要模型具备较强的推理能力,建议选择参数量至少为1.5B的模型,并且要确保模型有合适的模板(如聊天模板),以便更好地进行训练和优化。
-
-
奖励函数设计
-
奖励函数的设计至关重要。它直接决定了模型如何被优化。例如,在数学问题求解任务中,如果奖励函数设计不合理,模型可能会偏向于输出错误的答案或者无法生成有效的思考过程。用户需要根据任务的特点,精心设计奖励函数,如正确答案给予高分,拼写错误适当扣分等,以引导模型朝着正确的方向发展。
-

















 1211
1211

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









