







 本文介绍了如何使用Jsoup解析XML文档,包括三种解析方法:parse(File, String),parse(String)和parse(URL, int)。同时详细讲解了Document对象和Element对象的使用,如getElementById、getElementsByTag等方法。此外,还探讨了利用Jsoup的选择器和XPath进行快速查询的方式,为XML数据处理提供了实用技巧。"
123756554,9949616,VirtualBox 21.10 安装Ubuntu 21.10 教程:增强功能与共享文件,"['虚拟机', 'Linux', 'Ubuntu']
本文介绍了如何使用Jsoup解析XML文档,包括三种解析方法:parse(File, String),parse(String)和parse(URL, int)。同时详细讲解了Document对象和Element对象的使用,如getElementById、getElementsByTag等方法。此外,还探讨了利用Jsoup的选择器和XPath进行快速查询的方式,为XML数据处理提供了实用技巧。"
123756554,9949616,VirtualBox 21.10 安装Ubuntu 21.10 教程:增强功能与共享文件,"['虚拟机', 'Linux', 'Ubuntu']
目录
1 xml解析
xml文档操作有两种方式:解析xml和写入xml
写入:将内存中的数据保存到xml文档中。持久化的存储
xml解析:操作xml文档,将文档中的数据读取到内存中
| xml解析方式: | DOM:将标记语言文档一次性加载进内存,在内存中形成一颗dom树 * 优点:操作方便,可以对文档进行CRUD的所有操作 * 缺点:占内存 |
| SAX:逐行读取,基于事件驱动的。 * 优点:不占内存。 * 缺点:只能读取,不能增删改 | |
| xml常见的解析器 | 1. JAXP:sun公司提供的解析器,支持dom和sax两种思想 2. DOM4J:一款非常优秀的解析器 3. Jsoup:jsoup 是一款Java 的HTML解析器,可直接解析某个URL地址、HTML文本内容。它提供了一套非常省力的API,可通过DOM,CSS以及类似于jQuery的操作方法来取出和操作数据。 4. PULL:Android操作系统内置的解析器,sax方式的。 |
2 Jsoup解析器
Jsoup:jsoup 是一款Java 的HTML解析器,可直接解析某个URL地址、HTML文本内容。它提供了一套非常省力的API,可通过DOM,CSS以及类似于jQuery的操作方法来取出和操作数据。
列:使用解析器解析xml文档
导入包 jsoup-1.11.2.jar 并添加到库

创建student.xml文档
<?xml version="1.0" encoding="UTF-8" ?>
<students>
<student number="aa_0001">
<name id="aa_0001">
<xing>张</xing>
<ming>三</ming>
</name>
<age>18</age>
<sex>male</sex>
</student>
<student number="aa_0002">
<name>jack</name>
<age>18</age>
<sex>female</sex>
</student>
</students>代码书写
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
import org.jsoup.select.Elements;
import java.io.File;
import java.io.IOException;
/**
* Jsoup快速入门 Jsoup解析xml
*/
public class Jsoup01_Demo1 {
public static void main(String[] args) throws IOException {
//2.获取Document对象,根据xml文档获取
String path = Jsoup01_Demo1.class.getClassLoader().getResource("student.xml").getPath();//2.1获取student.xml的path
Document document = Jsoup.parse(new File(path), "utf-8");
Elements elements = document.getElementsByTag("name");// //3.获取元素对象 Element
//System.out.println(elements+"\r\r");
Element element = elements.get(1);//3.1获取第一个name的Element对象
String text = element.text();//3.2获取数据
System.out.println(text);
}
}
2.1 3种常见的Jsoup解析方式
常见的Jsoup解析html或xml文档有三种方式:
- parse(File in, String charsetName):解析xml或html文件的。
- parse(String html):解析xml或html字符串
- parse(URL url, int timeoutMillis):通过网络路径获取指定的html或xml的文档对象 Jsoup:工具类,可以解析html或xml文档,返回Document
方式1:parse(File in, String charsetName):解析xml或html文件的
public static void main(String[] args) throws IOException {
//1 获取student.xml文档的字节码文件,类加载器,获取文件路径
String path = Jsoup02_Document.class.getClassLoader().getResource("student.xml").getPath();
//2parse(File in, String charsetName):解析xml或html文件的。
Document document = Jsoup.parse(new File(path), "utf-8");
System.out.println(document);
} 方式2:parse(String html):解析xml或html字符串
public static void main(String[] args) throws IOException {
//1 获取student.xml文档的字节码文件,类加载器,获取文件路径
String path = Jsoup02_Document02.class.getClassLoader().getResource("student.xml").getPath();
//2 parse(String html):解析xml或html字符串
Document document = Jsoup.parse("<?xml version=\"1.0\" encoding=\"UTF-8\" ?>\n" +
"\n" +
"<students>\n" +
"\t<student number=\"aa_0001\">\n" +
"\t\t<name id=\"itcast\">\n" +
"\t\t\t<xing>张</xing>\n" +
"\t\t\t<ming>三</ming>\n" +
"\t\t</name>\n" +
"\t\t<age>18</age>\n" +
"\t\t<sex>male</sex>\n" +
"\t</student>\n" +
"\t<student number=\"aa_0002\">\n" +
"\t\t<name>jack</name>\n" +
"\t\t<age>18</age>\n" +
"\t\t<sex>female</sex>\n" +
"\t</student>\n" +
"\n" +
"</students>");
System.out.println(document);
} 方式3:parse(URL url, int timeoutMillis):通过网络路径获取指定的html或xml的文档对象 Jsoup:工具类,可以解析html或xml文档,返回Document
public static void main(String[] args) throws IOException {
//1 获取student.xml文档的字节码文件,类加载器,获取文件路径
String path = Jsoup02_Document03.class.getClassLoader().getResource("student.xml").getPath();
//2 parse(URL url, int timeoutMillis):通过网络路径获取指定的html或xml的文档对象 Jsoup:工具类,可以解析html或xml文档,返回Document
URL url = new URL("https://www.baidu.com");
Document document = Jsoup.parse(url, 10000);
System.out.println(document);
} 
2.2 Jsoup中document文档对象
Document:文档对象。代表内存中的dom树
* 获取Element对象
* getElementById(String id):根据id属性值获取唯一的element对象
* getElementsByTag(String tagName):根据标签名称获取元素对象集合
* getElementsByAttribute(String key):根据属性名称获取元素对象集合
* getElementsByAttributeValue(String key, String value):根据对应的属性名和属性值获取元素对象集合
列:document对象练习
1 导包jsoup-1.11.2.jar
2 写student.xml文件
<?xml version="1.0" encoding="UTF-8" ?>
<students>
<student number="aa_0001">
<name id="aa_0001">
<xing>张</xing>
<ming>三</ming>
</name>
<age>18</age>
<sex>male</sex>
</student>
<student number="aa_0002">
<name>jack</name>
<age>18</age>
<sex>female</sex>
</student>
</students>3 书写代码
public static void main(String[] args) throws IOException {
//1 获取student.xml文档的字节码文件,类加载器,获取文件路径
String path = Jsoup02_Document04.class.getClassLoader().getResource("student.xml").getPath();
Document document = Jsoup.parse(new File(path), "utf-8");
//3.获取元素对象了。
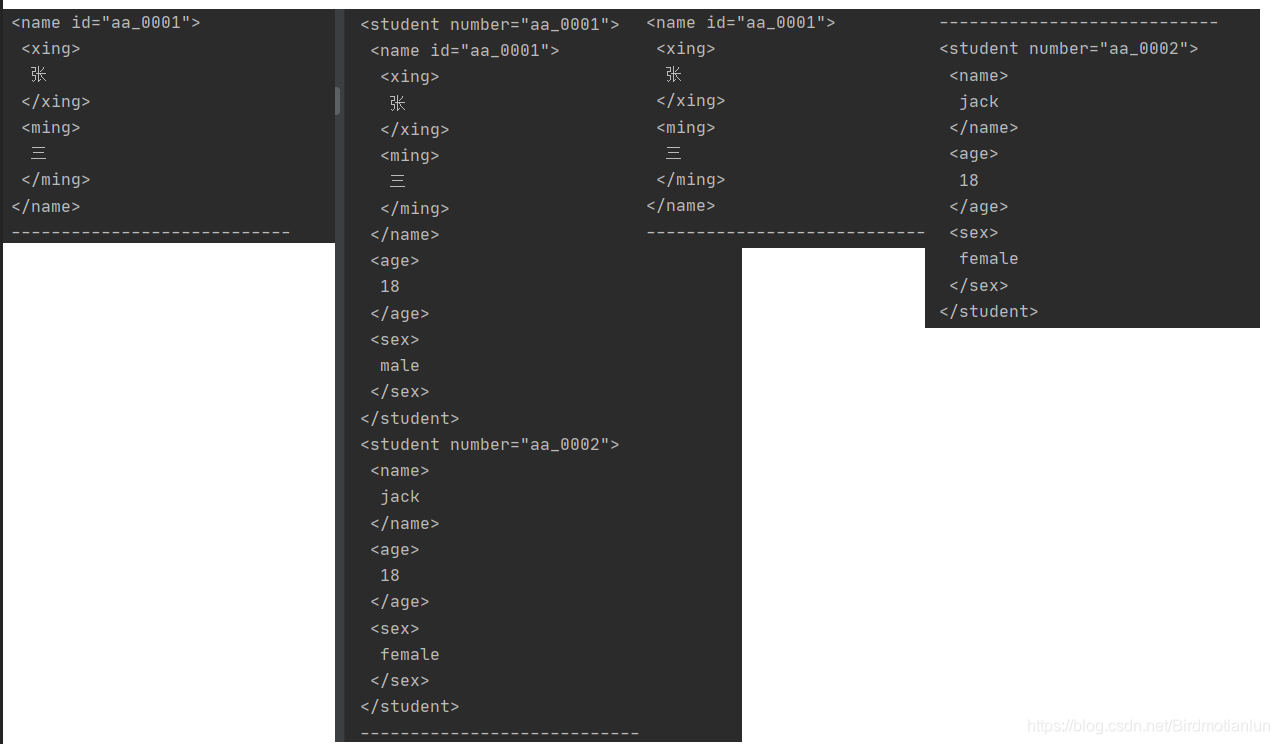
//3.1 getElementById(String id):根据id属性值获取唯一的element对象
Element element = document.getElementById("aa_0001");
System.out.println(element);
System.out.println("----------------------------");
//3.2获取所有student对象 getElementsByTag(String tagName):根据标签名称获取元素对象集合
Elements elements = document.getElementsByTag("student");
System.out.println(elements);
System.out.println("----------------------------");
//3.3 获取属性名为id的元素对象们 getElementsByAttribute(String key):根据属性名称获取元素对象集合
Elements elements1 = document.getElementsByAttribute("id");
System.out.println(elements1);
System.out.println("----------------------------");
//3.4 获取 number属性值为aa_0001的元素对象
Elements elements2 = document.getElementsByAttributeValue("number", "aa_0002");
System.out.println(elements2);
}
2.2 Jsoup中Element元素对象
Element:元素对象
| 获取子元素对象 | * getElementById(String id):根据id属性值获取唯一的element对象 * getElementsByTag(String tagName):根据标签名称获取元素对象集合 * getElementsByAttribute(String key):根据属性名称获取元素对象集合 * getElementsByAttributeValue(String key, String value):根据对应的属性名和属性值获取元素对象集合 |
| 获取属性值 | String attr(String key):根据属性名称获取属性值 |
| 获取文本内容 | String text():获取文本内容 String html():获取标签体的所有内容(包括字标签的字符串内容) |
列:Element对象练习
1 导包jsoup-1.11.2.jar
2 写student.xml文件
<?xml version="1.0" encoding="UTF-8" ?>
<students>
<student number="aa_0001">
<name id="aa_0001">
<xing>张</xing>
<ming>三</ming>
</name>
<age>18</age>
<sex>male</sex>
</student>
<student number="aa_0002">
<name>jack</name>
<age>18</age>
<sex>female</sex>
</student>
</students>3 书写代码
public static void main(String[] args) throws IOException {
//1 获取student.xml文档的字节码文件,类加载器,获取文件路径
String path = Jsoup02_Document04.class.getClassLoader().getResource("student.xml").getPath();
Document document = Jsoup.parse(new File(path), "utf-8"); //2.获取Document对象
//3.1 getElementsByTag(String tagName):根据标签名称获取元素对象集合
Elements elements = document.getElementsByTag("student");
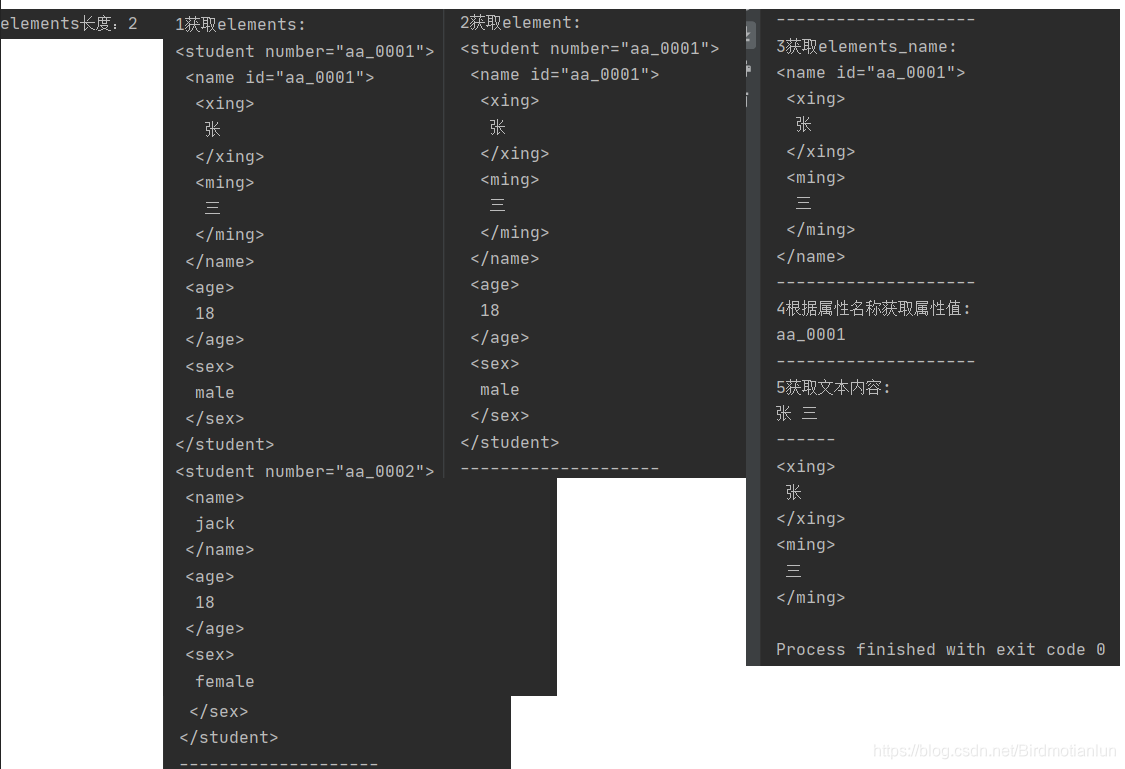
Element element = document.getElementsByTag("student").get(0);
System.out.println("elements长度:"+elements.size()+"\t");
System.out.println("1获取elements:\n"+elements);
System.out.println("--------------------\n"+"2获取element:\n"+element);
//3.2 通过Element对象获取子标签对象
Elements elements_name = element.getElementsByTag("name");
System.out.println("--------------------\n"+"3获取elements_name:\n"+elements_name);
//4 获取属性值 * String attr(String key):根据属性名称获取属性值
String id = elements_name.attr("id");//根据属性名称获取属性值
System.out.println("--------------------\n"+"4根据属性名称获取属性值:\n"+id);
//5 获取文本内容
String text = elements_name.text();
String html = elements_name.html();
System.out.println("--------------------\n"+"5获取文本内容:\n"+text+"\n------\n"+html);
}
3 xml快捷查询方式
xml快捷查询方式有两种方式:1使用jsoup的选择器查询 2 使用XPath查询
3.1 selector:选择器
使用的方法:Elements select(String cssQuery) * 语法:参考Selector类中定义的语法
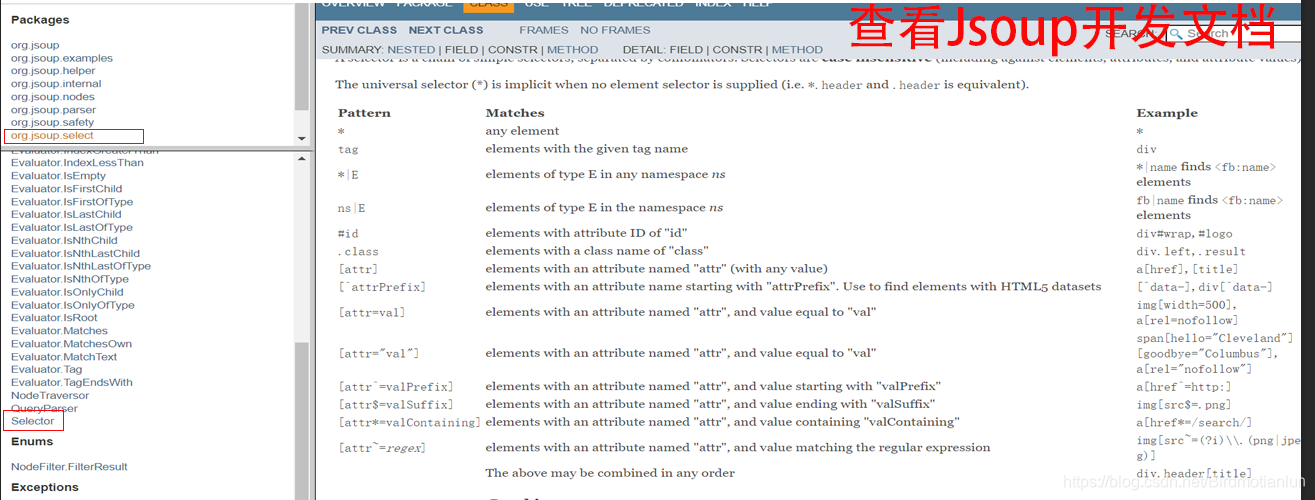
列:selector:实现查询
1 导包jsoup-1.11.2.jar
2 写student.xml文件
<?xml version="1.0" encoding="UTF-8" ?>
<students>
<student number="aa_0001">
<name id="aa_0001">
<xing>张</xing>
<ming>三</ming>
</name>
<age>18</age>
<sex>male</sex>
</student>
<student number="aa_0002">
<name>jack</name>
<age>18</age>
<sex>female</sex>
</student>
</students>3 书写代码
public static void main(String[] args) throws IOException {
//1 获取student.xml文档的字节码文件,类加载器,获取文件路径
String path = Jsoup04_selector.class.getClassLoader().getResource("student.xml").getPath();
Document document = Jsoup.parse(new File(path), "utf-8"); //2.获取Document对象
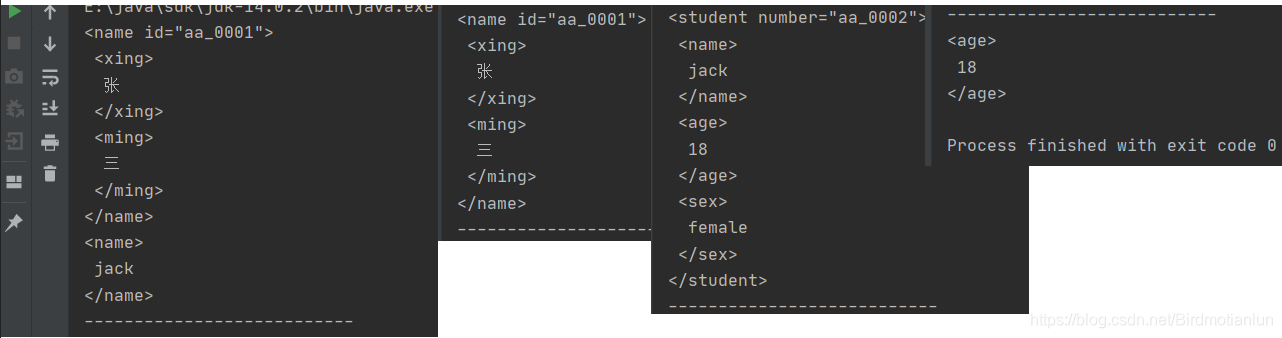
//3 查询name元素
Elements elements_name = document.select("name");
System.out.println(elements_name);
System.out.println("---------------------------");
//3.1 查询id值为aa_0001的元素
Elements element_id = document.select("#aa_0001");
System.out.println(element_id);
System.out.println("---------------------------");
//3.2 获取student标签并且number属性值为aa_0002
Elements elements = document.select("student[number='aa_0002']");
System.out.println(elements);
System.out.println("---------------------------");
// 3.3 获取student标签并且number属性值为aa_0002的age子标签
Elements elements1 = document.select("student[number='aa_0002']>age");
System.out.println(elements1);
}
3.2 XPath查询
XPath:XPath即为XML路径语言,它是一种用来确定XML(标准通用标记语言的子集)文档中某部分位置的语言
查询w3cshool参考手册,使用xpath的语法完成查询
列:XPath:实现查询
1 导包jsoup-1.11.2.jar JsoupXpath-0.3.2.jar
2 写student.xml文件
<?xml version="1.0" encoding="UTF-8" ?>
<students>
<student number="aa_0001">
<name id="aa_0001">
<xing>张</xing>
<ming>三</ming>
</name>
<age>18</age>
<sex>male</sex>
</student>
<student number="aa_0002">
<name>jack</name>
<age>18</age>
<sex>female</sex>
</student>
</students>3 书写代码
public static void main(String[] args) throws IOException, XpathSyntaxErrorException {
//1.获取student.xml的path
String path = Jsoup05_XPath.class.getClassLoader().getResource("student.xml").getPath();
//2.获取Document对象
Document document = Jsoup.parse(new File(path), "utf-8");
//3 根据document对象,创建JXDocument对象
JXDocument jxDocument = new JXDocument(document);
//4 结合xpath语法查询
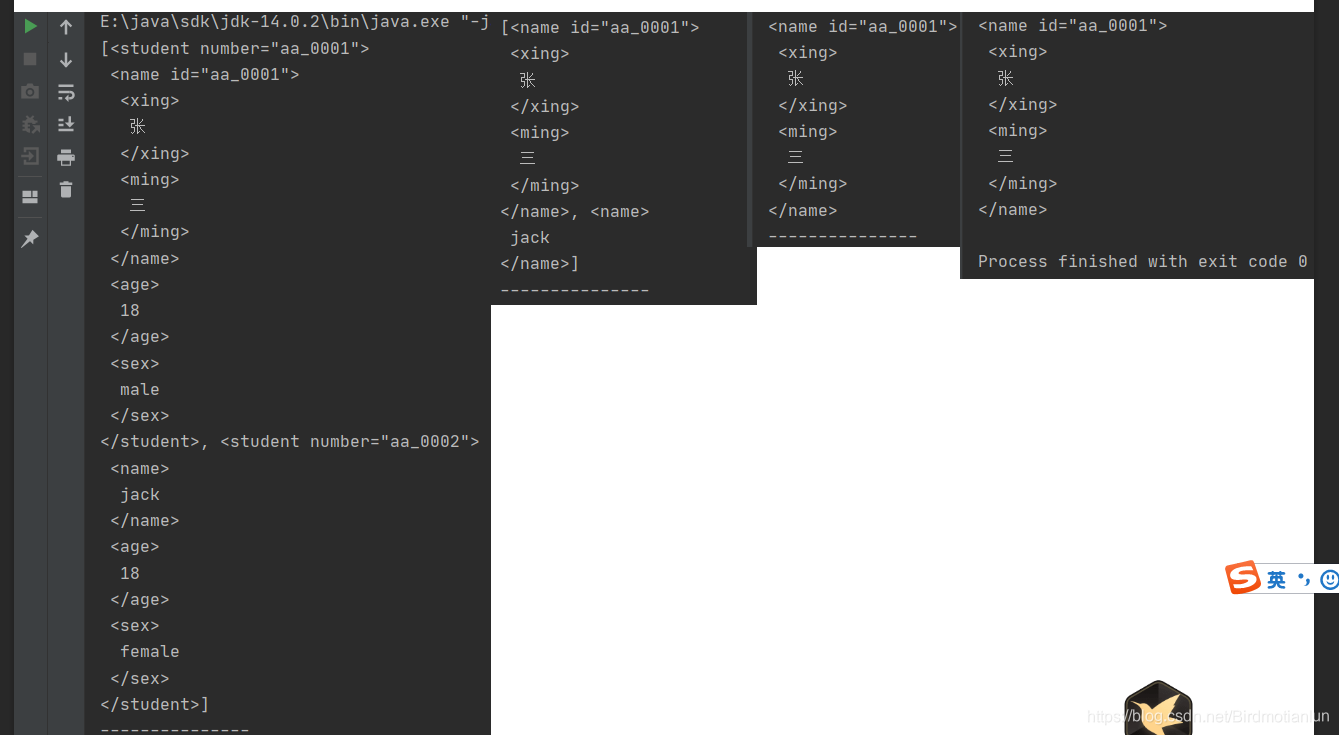
//4.1查询所有student标签
List<JXNode> jxNodes = jxDocument.selN("//student");
System.out.println(jxNodes);
System.out.println("---------------");
//4.2查询所有student标签下的name标签
List<JXNode> jxNodes1 = jxDocument.selN("//student/name");
System.out.println(jxNodes1);
System.out.println("---------------");
//4.3查询student标签下带有id属性的name标签
List<JXNode> jxNodes3 = jxDocument.selN("//student/name[@id]");
for (JXNode jxNode : jxNodes3) {
System.out.println(jxNode);
}
System.out.println("---------------");
//4.4查询student标签下带有id属性的name标签 并且id属性值为aa_0001
List<JXNode> jxNodes4 = jxDocument.selN("//student/name[@id='itcast']");
for (JXNode jxNode : jxNodes4) {
System.out.println(jxNode);
}


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









