



Kafka核心总结
Kafka是目前主流的分布式消息引擎及流处理平台,具有高吞吐、低延迟;可扩展;持久性、可靠性;容错性;高并发的特点。常被企业用来做消息总栈、日志收集、用户活动跟踪、运营指标、实时流处理管道。
1.1Kafka体系架构
Kafka的设计遵循生产者消费者模式,生产者发送消息到broker中的某一个topic的具体分区,消费者从一个或多个分区中拉取数据进行消费。
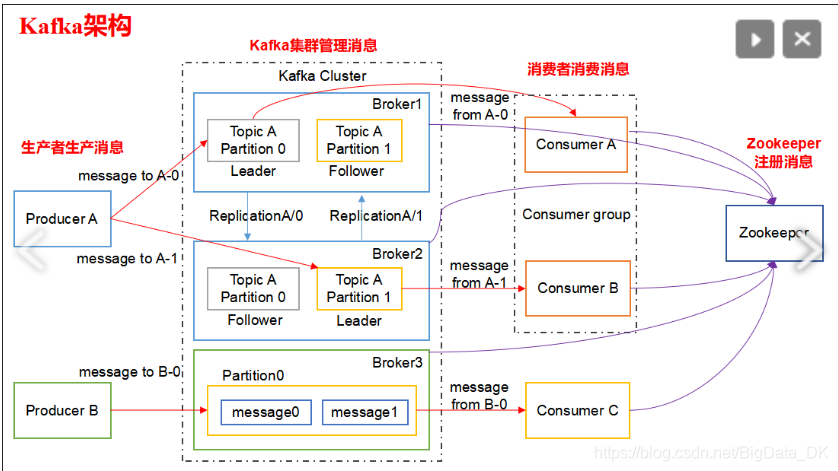
其中,Zookeeper做分布式协调服务,负责存储和管理Kafka集群中的元数据信息,包括集群中的broker信息、topic信息、topic的分区与副本信息等。
1.2基本概念和名词
Producer:生产者,消息产生端。
Broker:Kafka实例,一般一台机器一个broker,多个broker组成kafka集群,一个broker下可以有多个topic,一个topic下可以有多个partition分区,一般建议单个partition的leader数量不超过100。
Consumer:消费者,消息消费端.一个partition中的消息只能被同一个消费组中的一个消费者消费,同分区内数据有序。
Topic:主题,服务端消息的逻辑存储单元。内含若干Partition。
Partition:Topic下的分区,分布式存储在各个broker中,实现发布与订阅的负载均衡。
message:消息,Kafka服务端实际存储的数据,每一条消息都有一个key、一个value以及消息时间戳timestamp组成。
offset:偏移量,分区中消息的位置。
2.1Kafka的消息发送机制
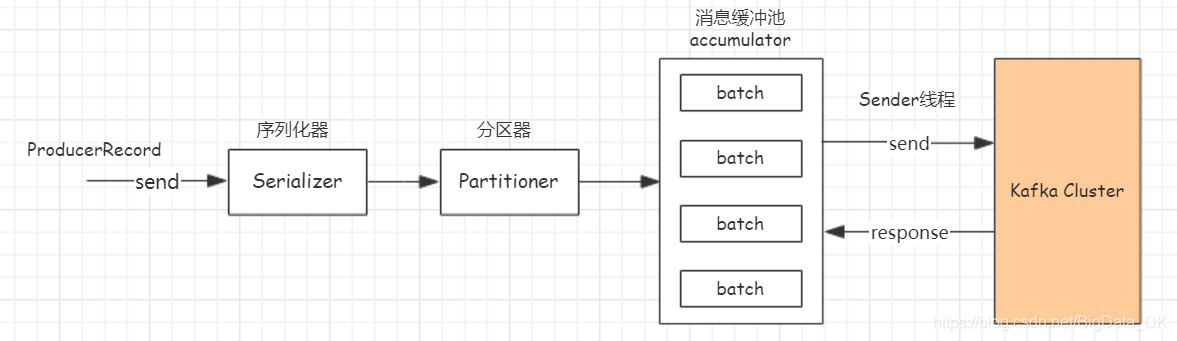
2.1.1异步发送
自0.8.2引入新版本的Producer API,完全采用异步方式发送消息。生产端构建的ProducerRecord先是经过keySerializer、valueSerializer序列化后,在经过Partition分区器处理,决定消息落到topic具体的某个分区当中,最后把消息发送到客户端的消息缓冲池accumulator当中,交给Sender的线程发送到broker端。其中accumulator的最大大小是由参数buffer.memory控制,默认是32M,当生产的消息的速度过快导致buffer满,将阻塞max.block.ms时间,超时抛异常,所以buffer的大小可以根据适当调整。
2.1.2批量发送
发送到缓冲buffer中的消息将会被分为一个一个batch,分批次发送到broker端,批次大小有参数batch.size控制,默认大小是16kb。,当减小batch大小有利于降低消息延迟,增大batch有利于提高吞吐量。当生成的消息未到16kb时,通过控制参数linger.ms,该参数控制batch的最大空闲时间,超过改时间也将发送消息到broker端。
2.1.3消息重试
当网络抖动等原因导致消息发送失败的时候,开启由参数retries控制的重试次数时,Producer端将会尝试再次发送消息。
附赠常见kafka面试32题(过往记忆大数据)
https://www.iteblog.com/archives/2605.html

















 1468
1468

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









