sklearn--CountVectorizer提取的词频矩阵的表示
最新推荐文章于 2025-08-16 18:40:12 发布





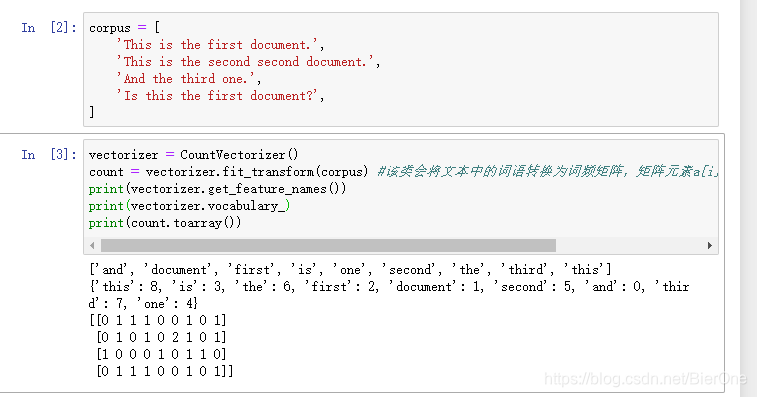
 本文解析了词频矩阵在信息技术中的重要性,介绍了如何通过[4,9]形状的矩阵来量化文本中词汇的分布,展示了如何在文档分类和文本分析中利用这种矩阵进行统计。
本文解析了词频矩阵在信息技术中的重要性,介绍了如何通过[4,9]形状的矩阵来量化文本中词汇的分布,展示了如何在文档分类和文本分析中利用这种矩阵进行统计。
本文解析了词频矩阵在信息技术中的重要性,介绍了如何通过[4,9]形状的矩阵来量化文本中词汇的分布,展示了如何在文档分类和文本分析中利用这种矩阵进行统计。
本文解析了词频矩阵在信息技术中的重要性,介绍了如何通过[4,9]形状的矩阵来量化文本中词汇的分布,展示了如何在文档分类和文本分析中利用这种矩阵进行统计。
 2323
2323

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言