




 本文介绍了如何详细爬取拉勾网的职位信息。首先分析页面发现换页是通过ajax的POST请求完成,接着获取请求地址并构造请求参数。通过对响应内容的JSON结构分析,确定了需要提取的字段。接着编写爬虫代码,成功抓取到数据,并将JSON数据转换为CSV格式保存,便于后续处理。
本文介绍了如何详细爬取拉勾网的职位信息。首先分析页面发现换页是通过ajax的POST请求完成,接着获取请求地址并构造请求参数。通过对响应内容的JSON结构分析,确定了需要提取的字段。接着编写爬虫代码,成功抓取到数据,并将JSON数据转换为CSV格式保存,便于后续处理。
1.进入拉钩网,(调到注册页可删掉url详情后缀直接登陆主页)
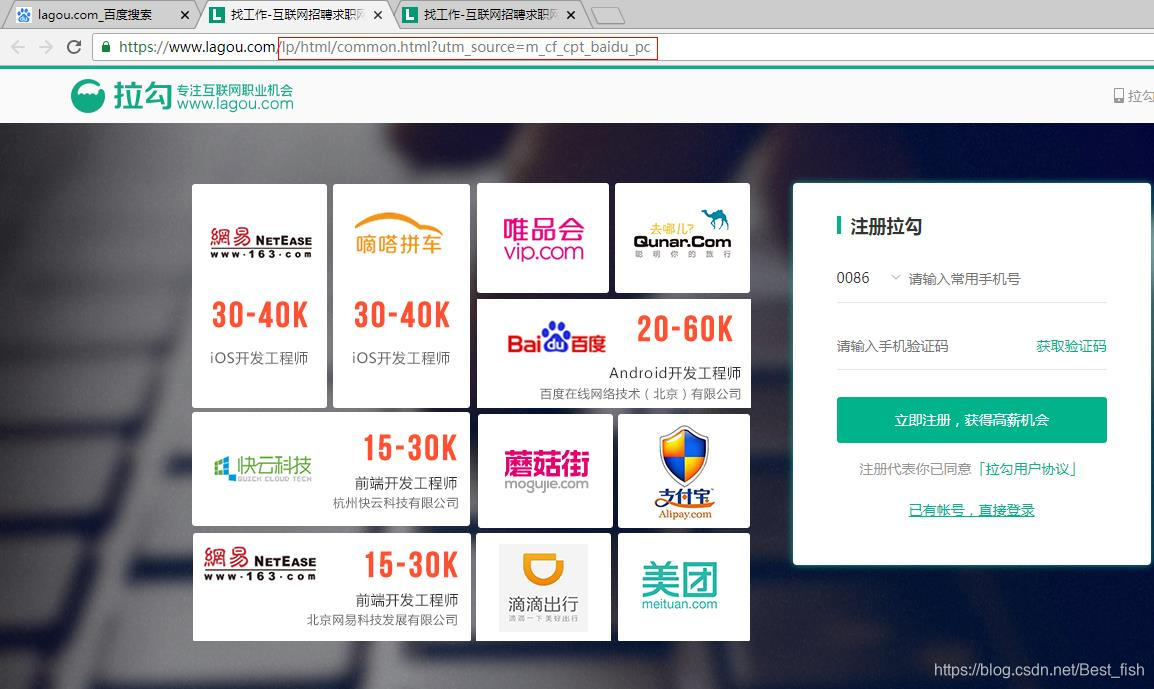
2.选定一个城市一种职位,分析一下页面,发现点击第一页第二页换页时url地址栏并未发生变化,可以判断是ajax发送的请求,且显示是post请求
拿到实际的请求地址,并构造查询字符串和请求体内容
-
https://www.lagou.com/jobs/positionAjax.json?gj=3%E5%B9%B4%E5%8F%8A%E4%BB%A5%E4%B8%8B&px=default&city=%E6%B7%B1%E5%9C%B3&needAddtionalResult=false
-
first: true
pn: 1 # 页码
kd: 深圳python #自己所输入的查询关键字
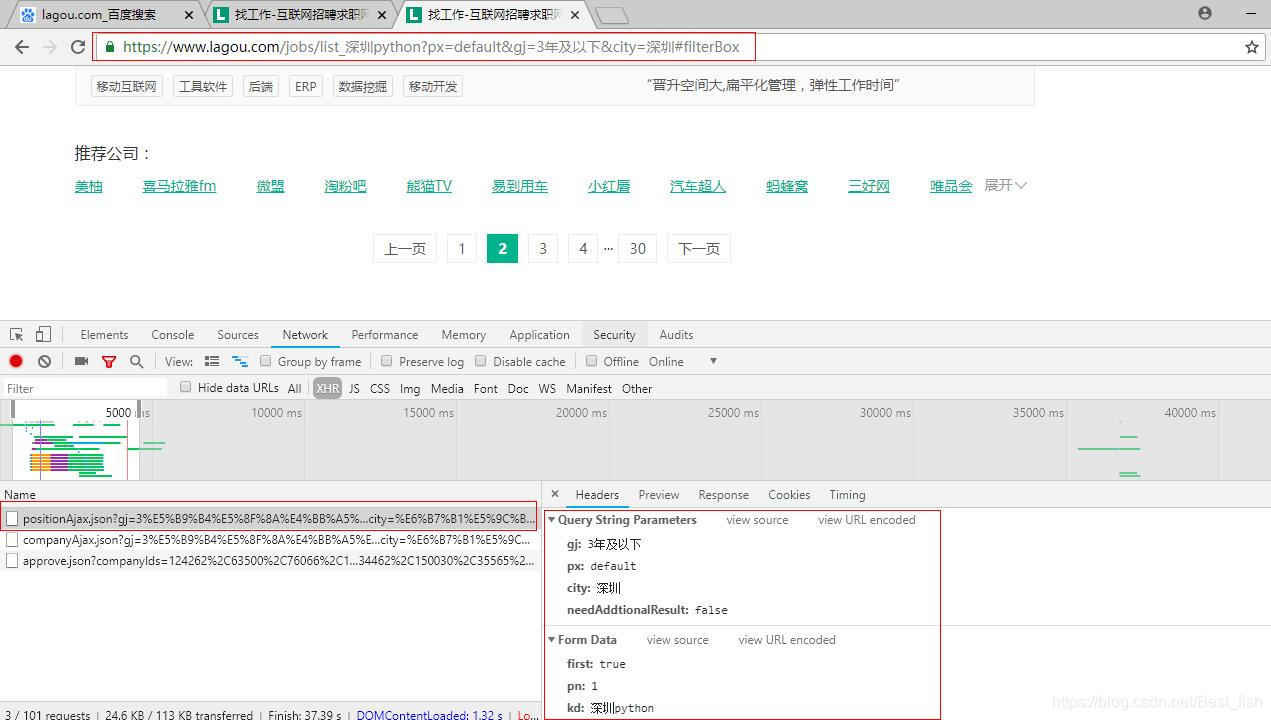
3.看了下页面,每页是15个招聘信息,将响应的Response内容粘贴到json解析器里查看了json的结构,确定要提取的内容
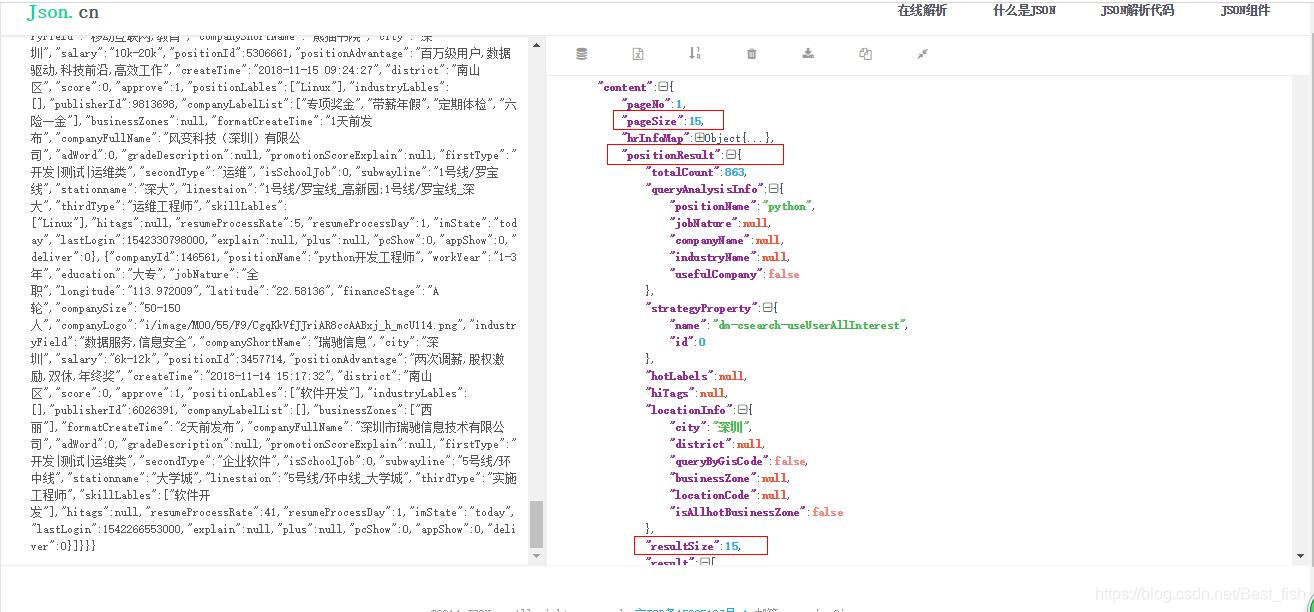
4.提取的内容:
result_list = jsonpath(json_obj, "$..result")[0] # 要加[0]取到数据列表
"""jsonpath取到的任何数据它都会自己在外面加 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 2214
2214

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









