




 本文介绍了一种使用Python的requests和re模块从西刺代理网站抓取IP地址的方法。通过定义get_ip函数,设置请求头模拟浏览器行为,获取网页内容并用正则表达式解析出IP列表。
本文介绍了一种使用Python的requests和re模块从西刺代理网站抓取IP地址的方法。通过定义get_ip函数,设置请求头模拟浏览器行为,获取网页内容并用正则表达式解析出IP列表。

import requests
import re
def get_ip():
url = "http://www.xicidaili.com/"
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.87 Safari/537.36'}
response = requests.get(url, headers=headers)
html = response.content.decode()
ip_list = re.findall("""<td class="country"><img src="http://fs.xicidaili.com/images/flag/cn.png" alt="Cn" /></td>
<td>(.*?)</td>""", html)
print(ip_list)
if __name__ == '__main__':
get_ip()
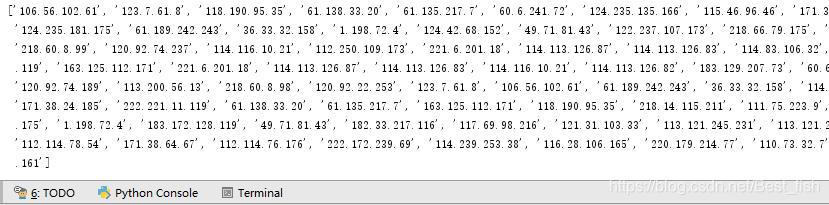
结果如下:

















 1441
1441

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









