



目录
✅一、含义
-
GBDT(Gradient Boosting Decision Tree)梯度提升树
用很多棵“弱”回归树逐步纠错、叠加成一个强模型。每一轮拟合的是上一轮损失函数的一阶负梯度(残差的推广)。常见实现:sklearn.ensemble.GradientBoosting*、LightGBM(也是GBDT家族,但用直方图与叶子生长策略做了大量工程优化)。 -
XGBoost(eXtreme Gradient Boosting)
在GBDT思想上做了工程与数学两端的“加料”:二阶近似(用一阶梯度G与二阶H)+ 正则化(L1/L2/叶子数惩罚)+ 列/行采样 + 稀疏感知 + 并行 + 早停 + 外存训练等。每一轮拟合的是二阶展开后的目标函数。常见实现:xgboost官方库(XGBClassifier/XGBRegressor/XGBRanker)。
✅二、核心区别(一张表看完)
| 维度 | 传统GBDT(如sklearn) | XGBoost |
|---|---|---|
| 梯度信息 | 一阶 | 一阶 + 二阶(更稳定、分裂更精准) |
| 正则化 | 一般仅 shrinkage(学习率)与行采样 | 叶子L1/L2、叶子数惩罚γ、行/列采样全套 |
| 列采样 | 通常不支持 | colsample_bytree/bylevel/bynode |
| 缺失/稀疏 | 需补值 | 稀疏感知,自动学习“缺失走向” |
| 并行/工程 | 较弱 | 高度优化,支持并行、外存、早停 |
| 树增长策略 | 多为层级(level-wise) | 默认层级,可选 lossguide |
| 类别特征 | 需编码 | 近年版本支持原生/或安全的一键编码;也可手动One-Hot |
| 易用性 | API简单,上手快 | 参数多、可控性强,调参空间大 |
| 速度/规模 | 中等 | 通常更快、更能扛大数据 |
✅三、拟合目标
1. GBDT
-
GBDT 第 T 轮:第 t轮把新树ft(x) 当作对当前模型预测的“修正量”,直接去拟合上一轮损失的一阶负梯度(伪残差),即拟合 真实值 y 和 前 T−1轮累计预测值 y^(T−1)的差值。
-
换句话说:GBDT 拟合的是 “还剩多少没学到”。
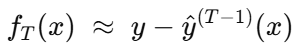
这就是“残差/伪残差”的直观解释。
2. XGBoost
XGBoost 没有直接去拟合“真实值 - 预测值”,而是:
-
不再“只拟合一阶负梯度”,而是把损失函数 ℓ(y,y^)在 y^(T−1) 附近做 二阶泰勒展开,用一阶 gi 与二阶 hi共同决定新树应学到的修正
-

-
新的树fT(x) 拟合的是:
-
一阶信息:预测需要往哪个方向修正(类似残差的作用);
-
二阶信息:修正时需要考虑的“曲率/置信度”(告诉模型“这条残差能不能完全相信”)。
-
👉 直观来说:
-
GBDT:新树只管“我还差多少(残差)”,于是全力去补。
-
XGBoost:新树管的是“我差多少 + 我应该修多少比较稳妥(残差 + 曲率)”。
3. 类比
-
GBDT:像学生做题,发现自己和标准答案差 10 分 → 下一次考试拼命补 10 分。
-
XGBoost:不仅看差 10 分,还看“这 10 分是不是因为一时失误还是题目本来就模糊”。于是可能只补 7 分,因为剩下 3 分不值得强行去追。
4. 总结
-
GBDT 第 T 轮拟合的:真实值与前 T−1 轮预测的差值(残差)。
-
XGBoost 第 T 轮拟合的:不是直接残差,而是 损失函数在当前预测点的一阶+二阶近似结果,即“残差修正 + 稳定性权衡”。
-
总结三句话:
-
GBDT 每轮拟合的是残差(只用一阶信息),追求让训练误差不断下降;
-
XGBoost 在此基础上引入二阶信息和正则化,不仅看误差,还考虑复杂度和稳定性;
-
所以 XGBoost 更稳健、更抗过拟合、工程化优化更多,在大规模应用上更优。
✅四、分裂增益
-
GBDT(以平方损失为例)
选择分裂点看**残差平方和(RSS)**能减少多少;等价的常用形式(只用一阶信息):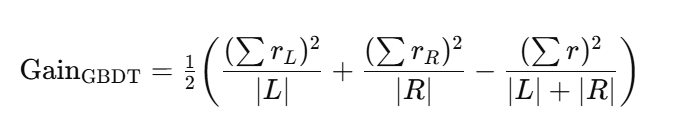
更一般的一阶形式可把 rrr 换为 ggg;本质是“拟合伪残差的SSE下降”。
-
XGBoost
用一阶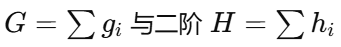 的二阶增益,并含正则:
的二阶增益,并含正则: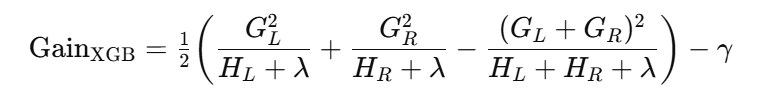
二阶项让高曲率/不稳定的分裂被“降权”,λ,γ\lambda,\gammaλ,γ 又能惩罚过度生长。
小结:
-
GBDT:看“如果在这个点切分,能把残差减少多少”,只依赖一阶信息。
-
XGBoost:切分前会算一笔账:分裂后误差能降多少,还要考虑分裂是否稳定、会不会让模型过于复杂。只有净收益为正,才会切。
👉 结果:XGBoost 的分裂决策更理性,避免了被噪声或异常样本误导。
✅五、目标函数与优化
(这一轮怎么求解最优叶子值)
-
GBDT
目标是最小化经验损失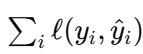 。在每个叶子里,新输出值通常来自对伪残差的均值/线性拟合(平方损失时是残差均值),再配合学习率与子采样抑制过拟合。显式的叶子正则化较弱。
。在每个叶子里,新输出值通常来自对伪残差的均值/线性拟合(平方损失时是残差均值),再配合学习率与子采样抑制过拟合。显式的叶子正则化较弱。 -
XGBoost
目标加入了结构化正则化: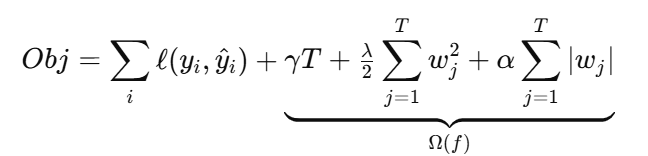
在二阶展开后,每个叶子的最优输出值有闭式解:
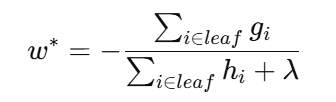
——像“牛顿法”的一步更新:分子是一阶合,分母带二阶合与 L2 正则,使更新更稳健。
小结:
-
GBDT:只关注训练误差,把它不断往下降。复杂度控制主要靠学习率、树深、子采样等策略性手段。
-
XGBoost:在误差之外,还把“模型复杂度的代价”写进目标函数(叶子多少、叶子值大小都会被惩罚)。所以它优化的是“误差下降 − 复杂度成本”的净收益。
👉 结果:GBDT 主要追求降低误差,XGBoost 在降低误差的同时更自律,能抗过拟合。
✅六、 逻辑主线
-
拟合目标:
-
GBDT:学负梯度(伪残差)。
-
XGB:学二阶近似(负梯度 + 曲率调节)。
-
-
目标函数/优化:
-
GBDT:无显式叶子正则,叶子值≈残差均值。
-
XGB:有 Ω(f) 正则;叶子值闭式解 −G/(H+λ) 。
-
-
分裂增益:
-
GBDT:基于一阶(RSS/梯度和)的下降量。
-
XGB:基于一阶+二阶并带惩罚的下降量。
-



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









