



点击上方 "云祁的数据江湖"关注, 星标一起成长

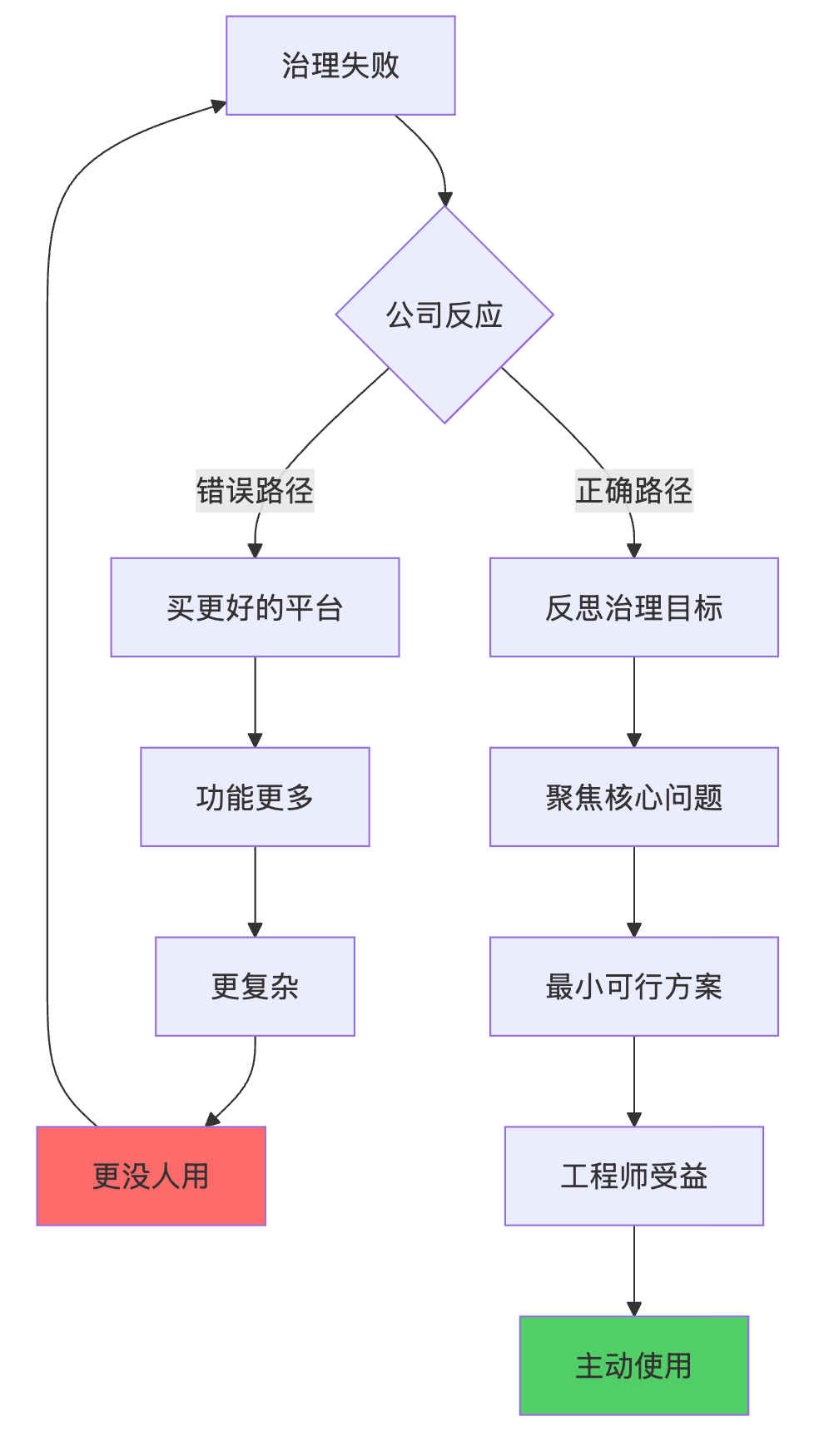
先给结论,不绕弯:大多数公司的数据治理失败,不是因为技术不行, 而是从一开始就 搞反了方向。
很多人以为的治理是:
加规则
上平台
定流程
抓考核
但真实世界里,治理的本质只有一件事:
降低数据使用过程中的摩擦成本。
如果一套治理方案:
让开发更慢
让排查更难
让责任更模糊
那它一定会失败,而且失败得很快。
一、为什么一提"数据治理",大家第一反应是抵触?
只要有人在群里说:
"这个要不要纳入数据治理?"
接下来通常是:
工程师沉默
业务皱眉
管理者兴奋
原因只有一个:"数据治理"这四个字,在很多公司已经被用坏了。
工程师眼里的治理
字段要补 20 个元数据
表血缘有问题,责任在我
口径不一致,我来改
平台规则一堆,排障还得靠自己
一句话总结:
治理 = 额外负担 + 潜在风险
业务眼里的治理
以前能直接查
现在要提申请
口径还更复杂了
他们的直觉是:
治理 ≠ 更好用 治理 = 更麻烦
真正的问题
数据治理长期只在约束供给侧, 却很少优化使用体验。
不解决摩擦,却不断强调规范, 治理必然会变成组织内耗。

二、血缘 / 口径 / 质量:三大"治理幻觉"
很多公司一做治理,就直奔:
血缘
口径
质量
听起来专业,但90% 的公司都踩进了同一批坑。
1️⃣ 血缘幻觉:你以为看见了,其实没用
典型血缘平台:
表 → 表 → 表
字段级血缘密密麻麻
图画得像电路板
但排查问题时,没人用。
因为它回答不了三个关键问题:
出问题该看哪?
谁该负责?
会影响什么?
如果血缘不能解决这三点, 对工程师的实际价值是 0。
🔴 错误的血缘实现
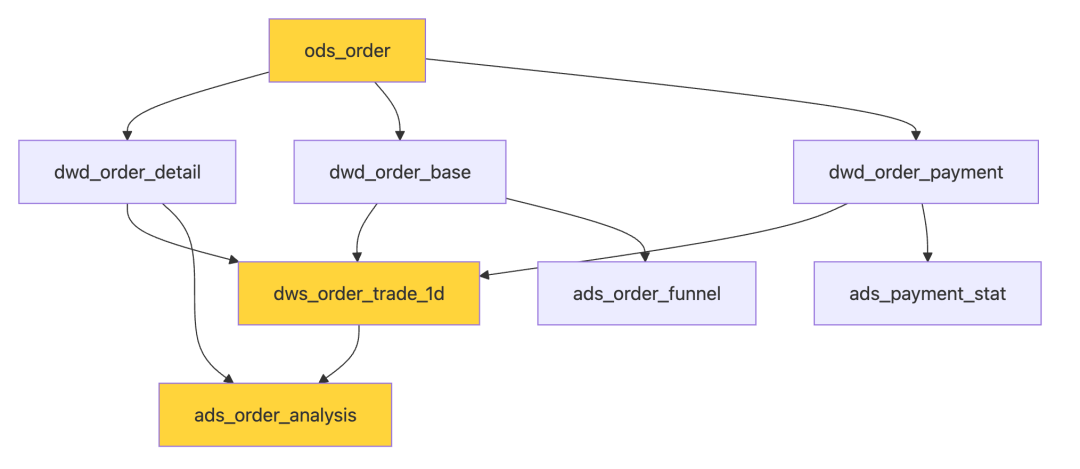
问题:
节点太多,看不清主路径
找不到关键依赖
不知道影响范围
✅ 正确的血缘实现:可操作的血缘
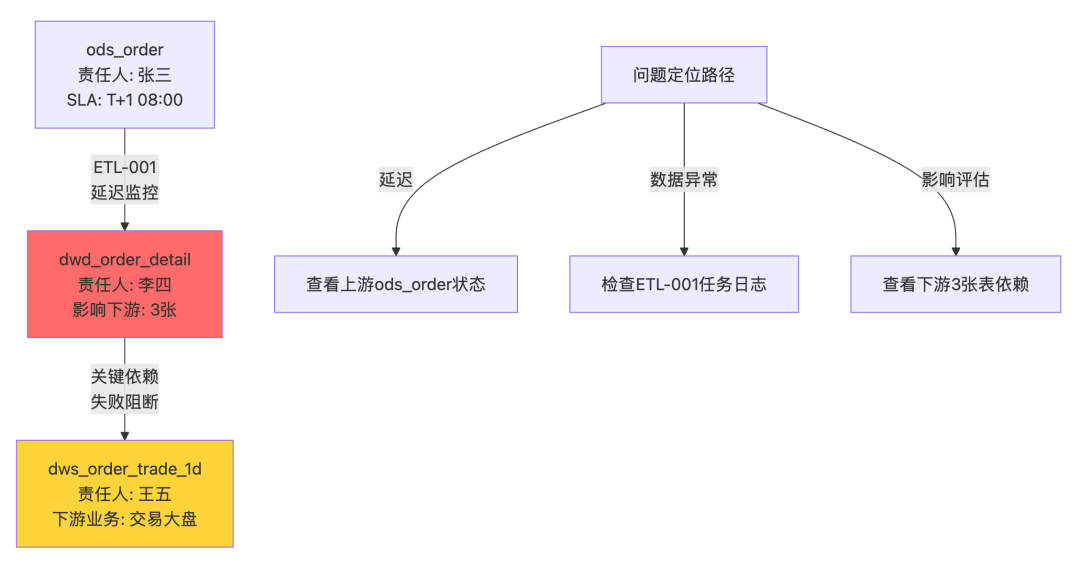
关键改进:
只显示关键路径,不是所有表
每个节点标注责任人和SLA
边上标注任务ID和监控状态
提供明确的排查路径
实战案例:可落地的血缘元数据
-- 表级别元数据(最小可行方案)
CREATETABLE meta_table_lineage (
table_name VARCHAR(200),
owner VARCHAR(50), -- 责任人(必填)
business_scene VARCHAR(200), -- 业务场景(必填)
sla_time VARCHAR(20), -- SLA时间(必填)
upstream_critical TEXT, -- 关键上游(JSON格式)
downstream_count INT, -- 下游表数量
oncall_contact VARCHAR(100), -- 出问题找谁(必填)
last_incident_date DATE, -- 最近一次故障时间
impact_level VARCHAR(20) -- 影响等级:P0/P1/P2
);
-- 示例数据
INSERTINTO meta_table_lineage VALUES (
'dws_order_trade_1d',
'王五',
'交易大盘-首页核心指标',
'T+1 08:00',
'["ods_order", "dwd_order_detail"]',
12,
'王五 @wangwu (微信: wx_wangwu)',
'2024-11-23',
'P0'
);核心思想:
只记录救命信息,不追求完美
能让工程师3分钟定位问题
责任清晰,不让人背锅
2️⃣ 口径幻觉:你统一了定义,却没统一场景
现实中的"统一指标"往往变成:
一张官方指标表
一堆没人敢用的字段
业务继续自己算
原因很简单:
口径不是对错问题,是使用场景问题。
运营要快
财务要准
分析要可解释
强行统一,只会逼着大家绕开你。
🔴 错误的口径治理
-- 所谓的"统一口径"
CREATE TABLE dim_metric_standard (
metric_name VARCHAR(100),
metric_define TEXT,
calculation_logic TEXT,
create_time TIMESTAMP
);
-- 结果是:
-- 1. 定义写得像论文,没人看
-- 2. 业务场景没有覆盖
-- 3. 实际使用时还是各算各的真实场景:
场景 | GMV口径 | 为什么不同 |
|---|---|---|
运营日报 | 下单金额 | 要实时,快速响应 |
财务报表 | 确认收入金额 | 要准确,符合财务准则 |
CEO看板 | 支付金额 | 要直观,反映现金流 |
算法训练 | 去退款后金额 | 要干净,提升模型效果 |
✅ 正确的口径治理:场景化口径管理
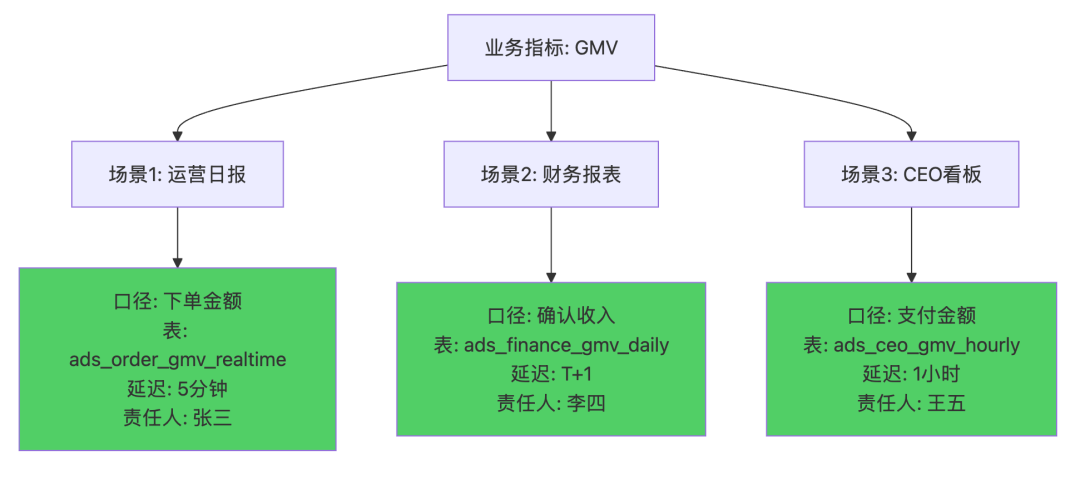
核心改进:
不强求统一,而是明确场景
每个场景提供指定表,不让用户自己算
清晰标注延迟和责任人
实战案例:口径注册表
CREATE TABLE meta_metric_registry (
metric_name VARCHAR(100), -- 指标名称
business_scene VARCHAR(200), -- 业务场景
metric_definition TEXT, -- 口径定义(白话文)
recommended_table VARCHAR(200), -- 推荐使用的表
sql_template TEXT, -- SQL模板
data_latency VARCHAR(50), -- 数据延迟
owner VARCHAR(50), -- 责任人
usage_count INT, -- 使用次数(重要)
last_verify_date DATE -- 最近校验时间
);
-- 示例:GMV指标的场景化管理
INSERTINTO meta_metric_registry VALUES
(
'GMV',
'运营日报-实时监控',
'下单金额,包含未支付订单,用于实时监控业务波动',
'ads_order_gmv_realtime',
'SELECT DATE(order_time) as dt, SUM(order_amount) as gmv FROM ads_order_gmv_realtime WHERE dt = ''${date}'' GROUP BY dt',
'5分钟',
'张三',
1580,
'2024-12-10'
),
(
'GMV',
'财务报表-月度结算',
'确认收入金额,已支付且未退款,符合财务确认准则',
'ads_finance_gmv_daily',
'SELECT DATE(confirm_time) as dt, SUM(confirm_amount) as gmv FROM ads_finance_gmv_daily WHERE dt BETWEEN ''${start_date}'' AND ''${end_date}'' GROUP BY dt',
'T+1',
'李四',
320,
'2024-12-10'
);使用方式:
-- 用户查询时,系统自动推荐
SELECT * FROM meta_metric_registry
WHERE metric_name = 'GMV'
AND business_scene LIKE '%实时%'
ORDER BY usage_count DESC;
-- 返回:推荐使用 ads_order_gmv_realtime
-- 提供SQL模板,直接替换日期即可使用3️⃣ 质量幻觉:你监控了,但问题依旧
常见质量规则:
非空率
波动率
行数校验
结果是:
报警一堆
真问题被淹没
人逐渐麻木
最终:
系统"看起来很安全", 实际没人真正信数据。
🔴 错误的质量监控
# 典型的"过度监控"
quality_rules = [
{"table": "dwd_order", "rule": "not_null", "column": "order_id"},
{"table": "dwd_order", "rule": "not_null", "column": "user_id"},
{"table": "dwd_order", "rule": "not_null", "column": "create_time"},
{"table": "dwd_order", "rule": "range_check", "column": "amount", "min": 0},
{"table": "dwd_order", "rule": "enum_check", "column": "status"},
{"table": "dwd_order", "rule": "row_count_change", "threshold": 0.1},
{"table": "dwd_order", "rule": "duplicate_check", "column": "order_id"},
# ... 100+ 条规则
]
# 结果:
# 1. 每天报警50+条
# 2. 真正的业务问题被淹没
# 3. 所有人屏蔽报警✅ 正确的质量监控:只防致命错误
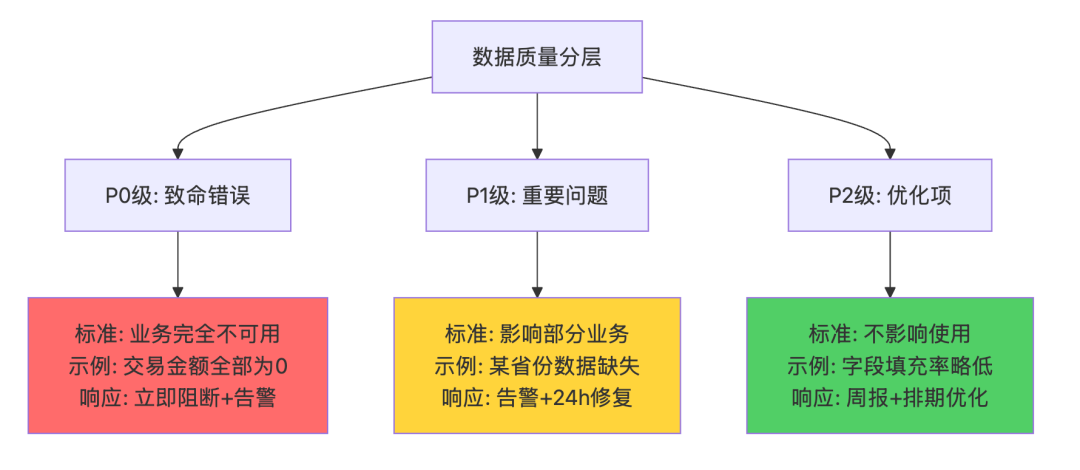
实战案例:最小可行质量监控
# 只监控"真正会让业务炸掉"的问题
critical_quality_rules = {
"dws_order_trade_1d": [
{
"rule_name": "GMV为0检测",
"rule_type": "business_logic",
"sql": """
SELECT COUNT(*) as cnt
FROM dws_order_trade_1d
WHERE dt = '${date}' AND total_gmv = 0
""",
"threshold": 0, # GMV不能为0
"alert_level": "P0",
"action": "阻断下游任务",
"owner": "张三",
"business_impact": "CEO看板数据为0,影响决策"
},
{
"rule_name": "数据延迟检测",
"rule_type": "sla",
"sql": """
SELECT MAX(update_time) as last_update
FROM dws_order_trade_1d
WHERE dt = '${date}'
""",
"threshold": "08:00",
"alert_level": "P0",
"action": "告警+自动重跑",
"owner": "张三",
"business_impact": "早会看不到数据"
}
]
}
# 执行逻辑
def check_quality(table_name, date):
rules = critical_quality_rules.get(table_name, [])
for rule in rules:
result = execute_sql(rule['sql'].replace('${date}', date))
ifnot pass_check(result, rule['threshold']):
# P0级:阻断+告警
if rule['alert_level'] == 'P0':
block_downstream_tasks(table_name)
send_alert(
owner=rule['owner'],
message=f"{rule['rule_name']}失败,业务影响:{rule['business_impact']}",
channel=['电话', '短信', '企业微信']
)
# P1级:告警不阻断
elif rule['alert_level'] == 'P1':
send_alert(
owner=rule['owner'],
message=f"{rule['rule_name']}异常",
channel=['企业微信']
)核心原则:
只监控3-5条真正致命的规则
每条规则必须说清楚业务影响
P0级规则:必须阻断下游
告警必须可操作:告诉我该怎么办
三、"治理平台"为什么救不了命?
很多公司治理受挫后会想:
"是不是我们平台不够好?"
于是开始选型、招标、自研、All in 平台。
但结论很明确:
平台只能放大认知,救不了错误方向。
平台的三大幻觉
幻觉1:功能越多越好
❌ 错误平台功能清单:
- 血缘分析(表级+字段级+代码级)
- 元数据管理(20+个字段)
- 数据地图(全表展示)
- 质量监控(100+规则模板)
- 成本分析
- 数据安全
- 数据资产评估
- ...
结果:每个功能都是半成品,没有一个真正好用✅ 正确平台功能清单:
- 核心表快速查询(只管TOP 50表)
- 责任人一键联系(出问题找得到人)
- 问题快速定位(3步找到根因)
结果:功能少但每个都好用,工程师主动用幻觉2:大而全才专业
某大厂数据治理平台架构:

问题:
建设周期:18个月
团队规模:15人
实际使用率:<5%
工程师反馈:"太复杂,还是用SQL查快"
幻觉3:平台能替代人
真相是:
平台只能降低协作成本,不能替代业务理解。
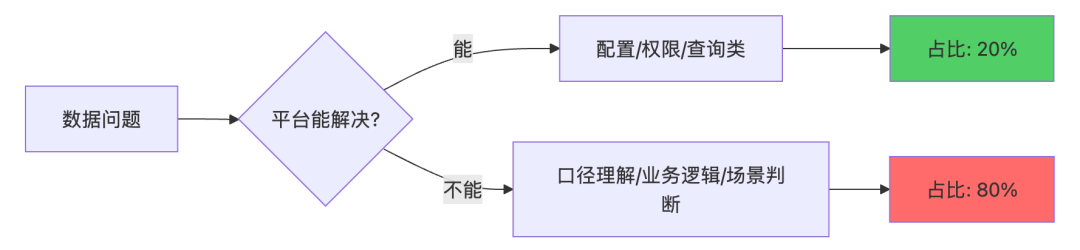
实际工作占比:
平台能解决的(配置、权限、查询):20%
平台解决不了的(口径理解、业务判断):80%
四、正确的数据治理切入顺序
这一节非常关键,顺序错了,后面全是返工。
✅ 唯一正确的顺序
先解决"用得顺不顺", 再谈"规不规范"。
graph TD
A[第一步: 识别高价值表] --> B[找出TOP 10核心表]
B --> C[第二步: 贴着问题治理]
C --> D[这些表最常见的问题是什么?]
D --> E[第三步: 让工程师少背锅]
E --> F[快速定位+责任清晰]
F --> G[第四步: 验证效果]
G --> H{排查时间减少50%?}
H -->|是| I[扩展到更多表]
H -->|否| J[回到第二步调整]
style H fill:#ffd43b
style I fill:#51cf66第一步:只治理高价值、高频数据
先回答:
哪些表用得最多?
出问题影响最大?
从 10 张核心表开始, 永远好过从 1000 张表开始。
如何识别核心表?
-- 方法1:统计查询频率
SELECT
table_name,
COUNT(*) as query_count,
COUNT(DISTINCT user_id) as user_count
FROM query_log
WHERE dt >= DATE_SUB(CURRENT_DATE, 30)
GROUPBY table_name
ORDERBY query_count DESC
LIMIT20;
-- 方法2:统计故障影响
SELECT
table_name,
COUNT(*) as incident_count,
SUM(CASEWHENlevel = 'P0'THEN1ELSE0END) as p0_count
FROM incident_log
WHERE dt >= DATE_SUB(CURRENT_DATE, 90)
GROUPBY table_name
ORDERBY incident_count DESC
LIMIT20;
-- 方法3:询问业务方
-- "如果这张表数据不准,你会怎么办?"
-- 回答"业务就停了" -> 核心表
-- 回答"那就换个表查" -> 非核心表实战案例:某电商公司的核心表清单
表名 | 业务场景 | 查询频次/天 | 故障影响 | 治理优先级 |
|---|---|---|---|---|
dws_order_trade_1d | CEO看板 | 1200+ | P0-业务决策 | 1 |
dws_user_behavior_1d | 用户分析 | 800+ | P1-分析延迟 | 2 |
ads_gmv_hourly | 实时大盘 | 2000+ | P0-实时监控 | 1 |
dwd_order_detail | 订单明细 | 3000+ | P0-多场景依赖 | 1 |
dim_user | 用户维度 | 5000+ | P1-查询慢 | 3 |
治理策略:
优先级1(3张表):完整治理,P0级监控
优先级2(5张表):基础治理,P1级监控
优先级3(其他):只补充责任人信息
第二步:贴着真实问题做治理
不要一上来就:
画蓝图
定模型
写规范
而是问:
这个表最常见的问题是什么?
延迟?口径?含义不清?
治理不是设计题,是排障题。
实战案例:针对性治理
问题1:某表经常延迟,影响早会
# 不是加监控规则,而是:
# 1. 分析延迟原因
问题根因:上游ods表凌晨6点才到,处理需要1.5小时,SLA是7:30但经常超时
# 2. 针对性优化
优化方案:
- 和上游团队协调,ods表提前到5:30
- 优化ETL逻辑,处理时间从1.5h降到40min
- 增加SLA监控,7:00未完成则告警
# 3. 补充治理元数据
meta_table_lineage 添加:
- sla_time: '07:30'
- critical_dependency: 'ods_order (需在05:30前完成)'
- optimization_history: '2024-12优化,处理时间从1.5h降到40min'问题2:某表口径经常被问
# 不是写文档,而是:
# 1. 分析为什么被频繁咨询
问题根因:GMV字段有3个(gmv_total/gmv_paid/gmv_confirm),用哪个不清楚
# 2. 针对性优化
优化方案:
- 在表注释中直接写清楚:
"""
gmv_total: 下单金额,包含未支付
gmv_paid: 支付金额,运营日报用这个
gmv_confirm: 确认收入,财务报表用这个
"""
- 在数据平台查询页面,字段旁边加tooltip提示
- 提供SQL模板,让用户直接复制
# 3. 效果验证
- 优化前:每周被咨询5次
- 优化后:每周被咨询0.5次第三步:让工程师"少背锅"
这是成败的关键:
能否快速定位问题?
责任是否清晰?
是系统问题还是人问题?
如果治理的结果是:
"以后出问题,更容易找到人"
那工程师一定会抵触。
实战案例:故障快速定位系统
# 当 dws_order_trade_1d 数据异常时
# 传统方式:
1. 查看任务日志(10分钟)
2. 找DBA查上游表状态(等待20分钟)
3. 翻看代码找依赖关系(15分钟)
4. 联系上游负责人(可能找不到人)
总耗时:45分钟+
# 治理后方式:
系统自动分析: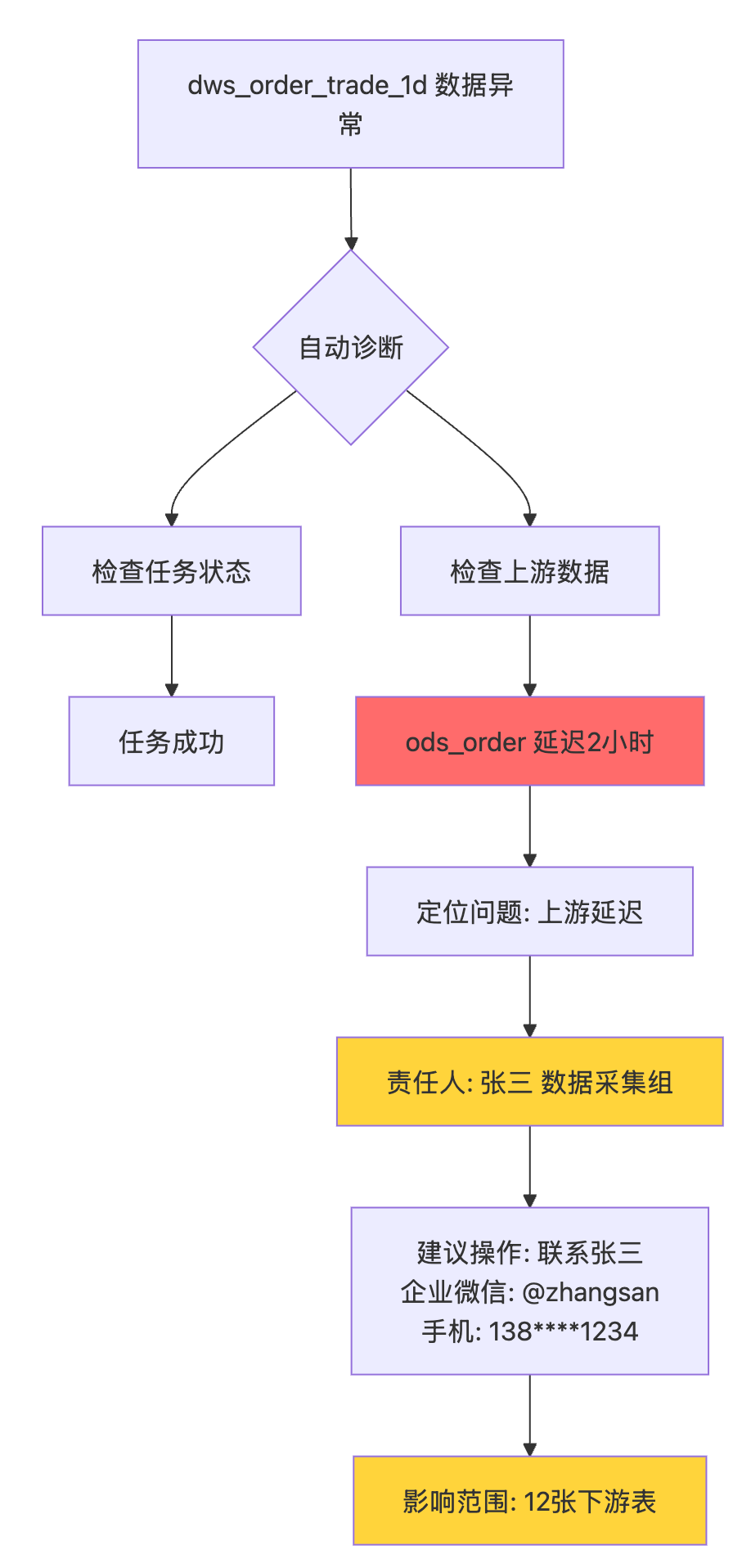
# 系统返回:
{
"table": "dws_order_trade_1d",
"issue": "数据量异常(降低60%)",
"root_cause": "上游表 ods_order 延迟2小时",
"responsible": {
"name": "张三",
"team": "数据采集组",
"contact": "@zhangsan (138****1234)"
},
"impact": {
"downstream_count": 12,
"business_impact": "CEO看板/运营日报 受影响"
},
"suggested_action": "联系张三确认ods_order延迟原因",
"diagnosis_time": "15秒"
}
总耗时:15秒五、工程师视角下的「最小可行治理」
下面是一套可以真实落地的轻治理方案。
核心原则
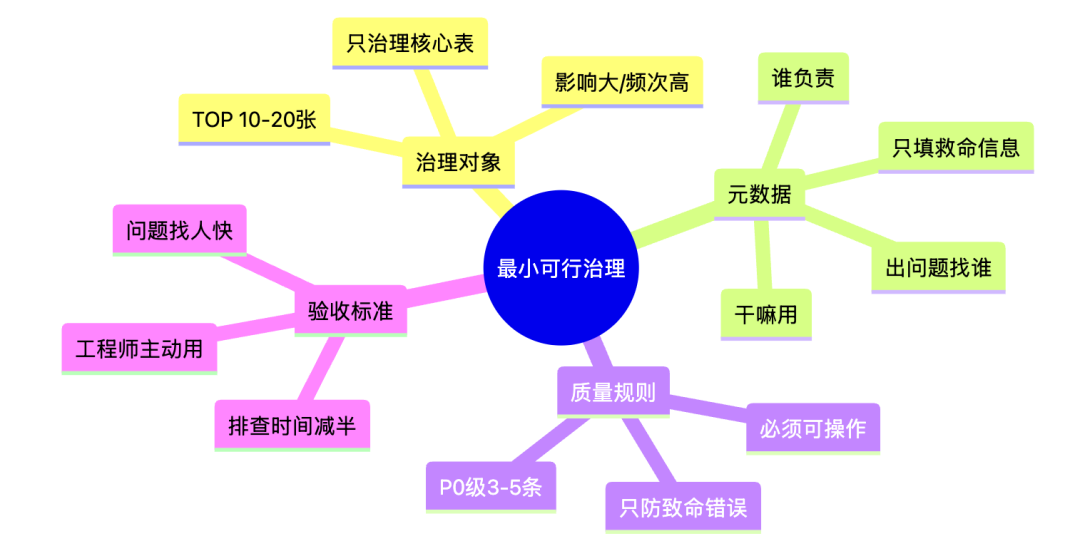
1️⃣ 治理对象要极少
核心事实表
核心指标表
高 SLA 表
不要贪多。
识别标准
# 核心表判断标准
def is_critical_table(table_name):
"""
满足以下任一条件即为核心表:
1. 每天查询 > 100次
2. 依赖的下游表 > 10张
3. 过去3个月出过P0故障
4. 支撑CEO/高管看板
"""
criteria = {
"high_frequency": get_daily_query_count(table_name) > 100,
"high_dependency": get_downstream_count(table_name) > 10,
"high_impact": has_p0_incident(table_name, days=90),
"executive_dashboard": is_in_executive_dashboard(table_name)
}
return any(criteria.values())
# 实际应用
critical_tables = [t for t in all_tables if is_critical_table(t)]
print(f"核心表数量: {len(critical_tables)} / {len(all_tables)}")
# 典型输出:核心表数量: 15 / 8502️⃣ 元数据只填"救命信息"
不追求完美描述,只保留三点:
谁维护
干嘛用
出问题找谁
这比 20 个规范字段都值钱。
最小元数据模型
CREATE TABLE meta_critical_tables (
-- 基础信息
table_name VARCHAR(200) PRIMARY KEY,
table_desc VARCHAR(500), -- 一句话说清楚干嘛用
-- 救命信息(必填)
owner VARCHAR(50) NOTNULL, -- 责任人
oncall_contact VARCHAR(200) NOTNULL, -- 联系方式(企业微信/手机)
business_scene VARCHAR(200) NOTNULL, -- 业务场景
-- SLA信息
sla_time VARCHAR(20), -- 期望完成时间
data_latency VARCHAR(50), -- 实际延迟情况
-- 依赖信息(简化版)
critical_upstream VARCHAR(500), -- 关键上游(JSON数组)
downstream_count INT, -- 下游表数量
-- 故障历史
last_incident_date DATE, -- 最近故障时间
incident_count_3m INT, -- 近3个月故障次数
-- 更新时间
update_time TIMESTAMPDEFAULTCURRENT_TIMESTAMP
);
-- 示例数据
INSERTINTO meta_critical_tables VALUES (
'dws_order_trade_1d',
'订单交易日汇总表,支撑CEO看板和运营日报',
'王五',
'@wangwu (微信: wx_wangwu, 手机: 138****5678)',
'CEO看板、运营日报、财务对账',
'T+1 08:00',
'通常07:30完成',
'["ods_order", "dwd_order_detail", "dim_user"]',
12,
'2024-11-23',
2,
NOW()
);填写要求:
table_desc:用一句话说清楚,不要写技术术语
❌ "基于Kimball维度建模的订单主题宽表"
✅ "订单交易汇总表,用于CEO看板"
oncall_contact:必须能立刻联系上
❌ "数据开发组"
✅ "@wangwu (微信: wx_wangwu, 紧急电话: 138****5678)"
3️⃣ 质量规则只防"致命错误"
不追求完美数据
只防业务不可接受的问题
规则少,但每一条都真的有人 care。
规则设计原则
# 规则分级标准
质量规则分级:
P0级(阻断级):
- 触发条件:数据错误导致业务决策完全错误
- 示例:GMV为0、交易量降低80%、关键字段全为NULL
- 响应:阻断下游任务 + 电话告警
- 数量:每张表不超过3条
P1级(告警级):
- 触发条件:数据不完美但可用
- 示例:某地区数据缺失、延迟超过1小时
- 响应:企业微信告警
- 数量:每张表不超过5条
P2级(记录级):
- 触发条件:数据优化项
- 示例:填充率略低、字段冗余
- 响应:周报汇总
- 数量:不限实战规则配置
# dws_order_trade_1d 质量规则配置
table:dws_order_trade_1d
owner:王五
rules:
# P0级规则
-name:GMV为0检测
level:P0
sql:|
SELECT COUNT(*) as issue_count
FROM dws_order_trade_1d
WHERE dt = '${date}' AND total_gmv = 0
threshold:0# 不允许为0
alert:
channels:[phone,sms,wechat]
message:"【P0】dws_order_trade_1d GMV为0,CEO看板受影响"
action:
block_downstream:true
auto_rollback:true
-name:数据量断崖检测
level:P0
sql:|
SELECT
today.order_count,
avg_7d.avg_count,
(today.order_count - avg_7d.avg_count) / avg_7d.avg_count as change_rate
FROM
(SELECT COUNT(*) as order_count FROM dws_order_trade_1d WHERE dt = '${date}') today,
(SELECT AVG(order_count) as avg_count FROM (
SELECT COUNT(*) as order_count FROM dws_order_trade_1d
WHERE dt BETWEEN DATE_SUB('${date}', 7) AND DATE_SUB('${date}', 1)
GROUP BY dt
)) avg_7d
threshold:-0.5# 降低超过50%
alert:
channels:[phone,wechat]
message:"【P0】dws_order_trade_1d 数据量骤降{change_rate}%"
action:
block_downstream:true
-name:SLA超时检测
level:P0
sql:|
SELECT MAX(update_time) as last_update
FROM dws_order_trade_1d
WHERE dt = '${date}'
threshold:"08:00"# 必须在8点前完成
alert:
channels:[wechat]
message:"【P0】dws_order_trade_1d 未按时完成,影响早会"
action:
block_downstream:false
auto_retry:true
# P1级规则
-name:关键维度缺失检测
level:P1
sql:|
SELECT
SUM(CASE WHEN province IS NULL THEN 1 ELSE 0 END) as null_count,
COUNT(*) as total_count
FROM dws_order_trade_1d
WHERE dt = '${date}'
threshold:0.01# 空值率不超过1%
alert:
channels:[wechat]
message:"【P1】dws_order_trade_1d 省份字段空值率超标"
action:
block_downstream:false4️⃣ 治理结果必须"立刻可感知"
查数更快
排障更清晰
沟通成本更低
只要工程师觉得省事了,治理就活了。
验收标准
场景 | 治理前 | 治理后 | 改善目标 |
|---|---|---|---|
找表 | 不知道用哪张表,要问人 | 数据平台推荐表,附带SQL模板 | 从10分钟到30秒 |
查责任人 | 翻文档/问群/找上级 | 一键查看联系方式 | 从30分钟到10秒 |
排查故障 | 手动查日志/猜测依赖 | 自动诊断根因+影响范围 | 从1小时到2分钟 |
理解口径 | 找文档/问业务/猜 | 表注释/字段说明/SQL模板 | 从20分钟到1分钟 |
实战案例:治理前后对比
场景:dws_order_trade_1d 数据异常
# 治理前的排查流程
1. 发现问题(业务反馈数据不对) -> 10分钟
2. 登录调度平台查看任务状态 -> 5分钟
3. 发现任务成功但数据异常 -> 5分钟
4. 查看代码找上游依赖关系 -> 15分钟
5. 逐个检查上游表数据质量 -> 30分钟
6. 发现 ods_order 有问题 -> 5分钟
7. 找 ods_order 负责人(问了3个人) -> 20分钟
8. 等待上游修复 -> 2小时
9. 重跑任务 -> 30分钟
总计:3小时40分钟
# 治理后的排查流程
1. 系统自动检测异常并告警 -> 实时
2. 告警直接显示根因:ods_order延迟 -> 0分钟
3. 告警附带责任人联系方式 -> 0分钟
4. 一键联系上游负责人 -> 1分钟
5. 等待上游修复 -> 2小时
6. 系统自动重跑 -> 0分钟
总计:2小时1分钟
时间节省:45%
人力节省:70%(大部分自动化)六、落地建议:从0到1的6周治理计划
Week 1-2:识别核心表
# 任务清单
tasks = [
"1. 统计过去3个月所有表的查询频次",
"2. 统计过去3个月的数据故障记录",
"3. 访谈5个核心业务方,了解关键表",
"4. 汇总得出TOP 15核心表清单",
"5. 和各表负责人确认治理优先级"
]
# 产出物
deliverables = {
"核心表清单": "Excel,包含表名/负责人/业务场景/优先级",
"访谈记录": "了解业务方最痛的数据问题",
"治理计划": "明确接下来4周要做什么"
}Week 3-4:补齐救命信息
# 任务清单
tasks = [
"1. 为TOP 15表补充元数据(责任人/联系方式/业务场景)",
"2. 梳理关键上下游依赖关系",
"3. 定义3-5条P0级质量规则",
"4. 搭建简易的元数据查询页面"
]
# 产出物
deliverables = {
"元数据表": "meta_critical_tables 完成填充",
"质量规则": "每张核心表配置好监控规则",
"查询页面": "工程师能快速查到责任人和联系方式"
}Week 5-6:验证效果
# 任务清单
tasks = [
"1. 灰度上线质量监控,观察告警准确率",
"2. 收集工程师反馈,调整元数据展示",
"3. 统计故障排查时间,对比治理前后",
"4. 总结成功案例,推广到更多表"
]
# 验收指标
metrics = {
"故障排查时间": "减少50%以上",
"找人时间": "从30分钟降到1分钟",
"工程师满意度": ">=80%",
"元数据使用率": "每天至少10次查询"
}最后一句实话
如果你们现在的治理:
文档很多
平台很重
却没人主动用
那你们做的可能不是数据治理,而是:
数据管理表演。
真正好的治理是润物细无声的, 它不会天天被提起,但所有人都离不开。
附录:可直接复用的代码模板
1. 核心表识别SQL
-- 识别核心表(综合查询频次、下游依赖、故障历史)
WITH query_stats AS (
SELECT
table_name,
COUNT(*) as query_count,
COUNT(DISTINCT user_id) as user_count
FROM query_log
WHERE dt >= DATE_SUB(CURRENT_DATE, 30)
GROUPBY table_name
),
lineage_stats AS (
SELECT
upstream_table as table_name,
COUNT(DISTINCT downstream_table) as downstream_count
FROM table_lineage
GROUPBY upstream_table
),
incident_stats AS (
SELECT
table_name,
COUNT(*) as incident_count,
SUM(CASEWHENlevel = 'P0'THEN1ELSE0END) as p0_count
FROM incident_log
WHERE dt >= DATE_SUB(CURRENT_DATE, 90)
GROUPBY table_name
)
SELECT
COALESCE(q.table_name, l.table_name, i.table_name) as table_name,
COALESCE(q.query_count, 0) as query_count,
COALESCE(l.downstream_count, 0) as downstream_count,
COALESCE(i.p0_count, 0) as p0_count,
-- 综合评分
COALESCE(q.query_count, 0) * 0.3 +
COALESCE(l.downstream_count, 0) * 10 * 0.4 +
COALESCE(i.p0_count, 0) * 100 * 0.3as priority_score
FROM query_stats q
FULLOUTERJOIN lineage_stats l ON q.table_name = l.table_name
FULLOUTERJOIN incident_stats i ON q.table_name = i.table_name
ORDERBY priority_score DESC
LIMIT20;2. 故障自动诊断脚本
#!/usr/bin/env python3
"""
数据异常自动诊断脚本
当数据质量监控发现异常时,自动分析根因
"""
def diagnose_table_issue(table_name, date):
"""
自动诊断表数据异常
"""
result = {
"table": table_name,
"date": date,
"status": "unknown",
"root_cause": None,
"responsible": None,
"impact": None,
"suggested_action": None
}
# 1. 检查任务执行状态
task_status = check_task_status(table_name, date)
if task_status != "SUCCESS":
result["status"] = "task_failed"
result["root_cause"] = f"任务执行失败: {task_status}"
result["responsible"] = get_table_owner(table_name)
result["suggested_action"] = "检查任务日志"
return result
# 2. 检查上游数据
upstream_tables = get_upstream_tables(table_name)
for upstream in upstream_tables:
upstream_status = check_data_quality(upstream, date)
ifnot upstream_status["healthy"]:
result["status"] = "upstream_issue"
result["root_cause"] = f"上游表 {upstream} 数据异常: {upstream_status['issue']}"
result["responsible"] = get_table_owner(upstream)
result["impact"] = get_downstream_impact(table_name)
result["suggested_action"] = f"联系 {result['responsible']['name']} 处理上游问题"
return result
# 3. 检查数据逻辑
logic_issue = check_business_logic(table_name, date)
if logic_issue:
result["status"] = "logic_error"
result["root_cause"] = f"数据逻辑异常: {logic_issue}"
result["responsible"] = get_table_owner(table_name)
result["suggested_action"] = "检查ETL代码逻辑"
return result
# 4. 无法诊断
result["status"] = "unknown"
result["suggested_action"] = "人工排查"
return result
def get_table_owner(table_name):
"""从元数据获取责任人信息"""
sql = f"""
SELECT owner, oncall_contact, business_scene
FROM meta_critical_tables
WHERE table_name = '{table_name}'
"""
row = execute_sql(sql)
return {
"name": row["owner"],
"contact": row["oncall_contact"],
"business": row["business_scene"]
}
def get_downstream_impact(table_name):
"""评估下游影响"""
sql = f"""
SELECT downstream_count, business_scene
FROM meta_critical_tables
WHERE table_name = '{table_name}'
"""
row = execute_sql(sql)
return {
"downstream_count": row["downstream_count"],
"business_impact": row["business_scene"]
}
# 使用示例
if __name__ == "__main__":
result = diagnose_table_issue("dws_order_trade_1d", "2024-12-16")
print(f"""
【自动诊断结果】
表名: {result['table']}
状态: {result['status']}
根因: {result['root_cause']}
责任人: {result['responsible']['name']} ({result['responsible']['contact']})
建议操作: {result['suggested_action']}
影响范围: {result['impact']}
""")3. 元数据快速查询页面(Flask)
#!/usr/bin/env python3
"""
轻量级元数据查询API
"""
from flask import Flask, request, jsonify
app = Flask(__name__)
@app.route('/api/table/<table_name>', methods=['GET'])
def get_table_info(table_name):
"""查询表元数据"""
sql = f"""
SELECT
table_name,
table_desc,
owner,
oncall_contact,
business_scene,
sla_time,
critical_upstream,
downstream_count
FROM meta_critical_tables
WHERE table_name = '{table_name}'
"""
result = execute_sql(sql)
ifnot result:
return jsonify({"error": "表不存在或不是核心表"}), 404
return jsonify(result)
@app.route('/api/search', methods=['GET'])
def search_tables():
"""搜索表"""
keyword = request.args.get('q', '')
sql = f"""
SELECT table_name, table_desc, owner, business_scene
FROM meta_critical_tables
WHERE table_name LIKE '%{keyword}%'
OR table_desc LIKE '%{keyword}%'
OR business_scene LIKE '%{keyword}%'
LIMIT 20
"""
results = execute_sql(sql)
return jsonify(results)
if __name__ == '__main__':
app.run(host='0.0.0.0', port=8080)
数据体系构建 👇
--END--
作者简介:云祁,某大厂资深数据工程师,经历过数据治理的坑坑洼洼,踩过无数次坑。公众号「云祁的数据江湖」主理人,专注分享接地气的数据工程实战。
如果这篇文章对你有启发,欢迎转发分享!

















 936
936

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









