




在神经网络中,上层的输出成为下层的输入之前,先经过一层激活函数,更符合自然界的神经网络特性,过小的刺激就不用在继续传播下去了;
而且,若不用激活函数,无论神经网络有多少层,输出都是输入的线性组合,引入非线性函数作为激活函数,可以使得学习能力更强
sigmoid
非常常用的激活函数
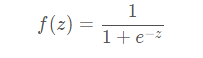
函数图形为S型
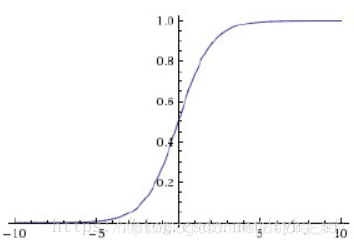
将输入压缩到0-1范围内
不过由于其导数的特性,容易导致梯度爆炸或消失,尤其是梯度消失
tanh
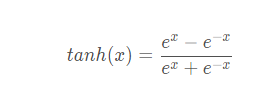
也是S型的
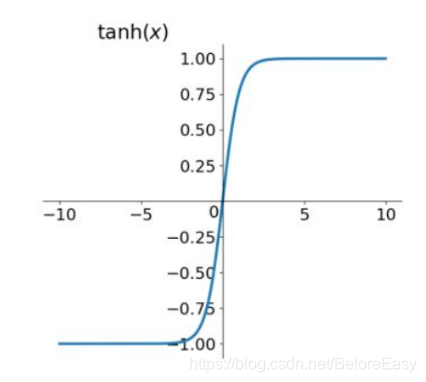
与sigmoid的区别是tanh将数据压缩到-1~1的范围内
还是会有梯度消失的问题
Relu
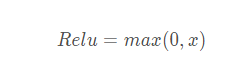
函数图形是这样的
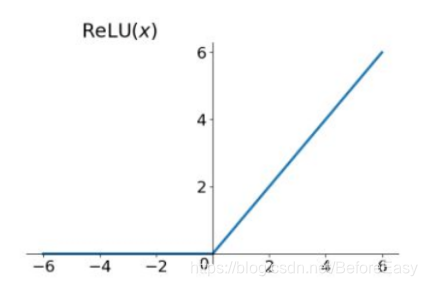
Relu有几个优点:
- 收敛速度快
- 解决了gradient vanishig的问题
- 计算速度快

















 1921
1921

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









