




基于MindStudio的Tensorflow 模型Profiling调优命令行实战图文案
--以Vision Transformer为例
对应的视频教程链接:基于MindStudio的Tensorflow模型Profiling调优命令行实战_哔哩哔哩_bilibili
目录
大家好,模型训练时的性能能够在一定程度上衡量芯片设备和底层框架运行状况好坏的标准。华为Ascend 910平台支持使用Tensorflow 和 Pytorch训练。但是这些框架源码都是基于NVidia芯片设计的,而华为Ascend910芯片有自己的一套底层架构方式。
为了更好的挖掘模型的耗时原因,我们需要获取每个算子的运行情况记录。这里的情况记录包含多个方面:1. 算子运行时间,2.算子等待时间。然而获取全图逐算子运算情况是非常复杂的过程.为此本文会向大家介绍MindStudio profiling工具,以及如何使用MindStudio实现结果的可视化呈现。本文主体由基础知识介绍,环境准备,具体实验和总结四部分组成。实验部分是以vision transformer做基础演示。最后本文是本文档的总结,以及根据笔者的开发经验,总结出一些tips,希望能帮助到各位开发者。
提醒:如果对基础知识以及有了较多的了解或者想尽快浏览实验部分的,可以直接跳过第一部分--前置知识和第二部分—环境准备,直接到第三部分的实验和第四部分的总结。
Ascend 910模型迁移训练
Tensorflow或者pytorch脚本无法直接在Ascend 910设备上加速运行,因为两者底层都依赖于cuda算子,需要针对Ascend 910做一定程度的修改,可以通过MindStudio的migration tools实现。910能够运行tensorflow或者pytorch脚本的原理是910对tensorflow和pytorch的底层做了修改,这些脚本所写的运算节点(或者称为网络层)最终会被Ascend 910的算子库对应替换。
Profiling 工具
Profiling实现了Host+Device侧丰富的性能数据采集能力和全景Timeline交互分析能力,展示Host+Device侧各项性能指标,帮助用户快速发现和定位AI应用的性能瓶颈。包括资源瓶颈导致的AI算法短板,指导算法性能提升和系统资源利用率的优化。Profiling支持Host+Device侧的资源利用可视化统计分析,具体包括Host侧CPU、Memory、Disk、Network利用率和Device侧APP工程的硬件和软件性能数据。Profiling提供针对硬件和软件性能数据采集、分析、汇总展示。总体流程如下:Profiling采集性能数据;MindStudio查询并解析数据;MindStudio展示性能数据。
MindStudio软件
MindStudio提供在AI开发所需的一站式开发环境,支持模型开发、算子开发以及应用开发三个主流程中的开发任务。依靠模型可视化、算力测试、IDE本地仿真调试等功能,MindStudio能够帮助您在一个工具上就能高效便捷地完成AI应用开发。MindStudio采用了插件化扩展机制,开发者可以通过开发插件来扩展已有功能。需要注意的是, MindStudio只有Linux和Windows两个版本,MAC电脑所使用的Unix OS不支持.
MindStudio 类似IDEA 软件,如下图所示,

要说明的是,通常在Windows服务器上安装MindStudio,昇腾AI设备需要安装对应的驱动、固件、Ascend-cann-toolkit和AI框架包。我们在本地写脚本,然后在云端(昇腾AI设备)执行,如下图所示:

如果您是直接在开发板上写脚本,会不同。本文针对的是以上开发场景。
MindStudio解决了两个问题:文件和云端同步以及脚本能够在云端执行。其中针对远程开发,MindStudio提供了Tools工具,该工具下面包含最常用的Deployment和SSH session工具。

其中Deployment 可以实现脚本的自动上传,SSH能够帮助我们随时链接远程服务器。
Ascend工具
MindStudio 还提供了 Ascend工具,其中包含很多我们开发Ascend应用时需要使用的工具, 如迁移工具(migration tools), 模型转换工具(model converter) , 模型可视化工具(model visualizer),模型精度分析工具(model accuracy analyzer),dump工具等.

Ascend 工具同时操纵远程的昇腾AI设备以及本地的开发环境.部分工具对本地环境有限制,如migration tools需要本地安装有pandas等库, profiler工具需要本地的python3环境能够使用sqlite.
本次的实验涉及本地开发环境(window10) 和 远程开发环境(Ascend 910服务器).
本地开发环境需要安装python3 和 MindStudio 软件.远程开发环境需要CANN中Ascend-cann-toolkit(开发套件包)。该开发套件是为开发者提供基于昇腾AI处理器的相关算法开发工具包,旨在帮助开发者进行快速、高效的模型、算子和应用的开发。开发套件包只能安装在Linux服务器上,开发者可以在安装开发套件包后,使用MindStudio开发工具进行快速开发.
目前远程开发环境(Ascend 910服务器)一般已经由华为官方配置好了,主要是驱动和CANN包的安装.
MindStudio安装与基本设置
MindStudio软件在本地安装时有环境要求, 为了避免后续出问题,建议遵循先检查环境是否完备,然后再安装软件.
参考链接:
首先检查本地环境
本地是否有python3.7及以上版本?
在cmd中输入python即可查验.

这里可能出现的问题是不少用户使用Conda或者miniconda实现python的环境管理,而跳过安装python的步骤,而使用anaconda或者miniconda所携带的默认python, 根据笔者的实验,发现: miniconda所自带的python版本通常为3.9, 且部分依赖缺失,如sqlite的dll文件.因此,建议安装独立安装python3.7.
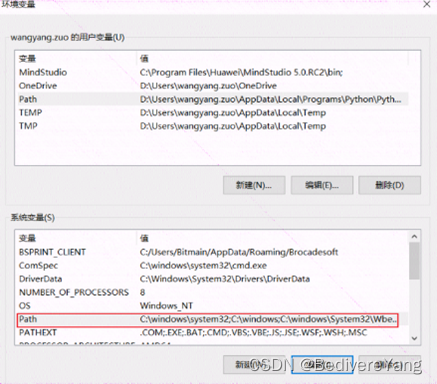
Python3.7 的版本可以通过 Welcome to Python.org 获得. 下载安装文件后,注意将python的路径添加到环境变量的path中. 在window10上可以通过win+s键,然后输入编辑环境快速进入环境变量设置界面.

 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 817
817

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









