



 本文介绍了一种多任务学习方法,用于量化CT图像中肺结节的9个语义特征,包括结节的坚固程度、形状的毛刺程度等。通过深度学习模型和手工特征,结合LIDC数据集,实验表明该方法的预测评分更接近放射科医生的评分。
本文介绍了一种多任务学习方法,用于量化CT图像中肺结节的9个语义特征,包括结节的坚固程度、形状的毛刺程度等。通过深度学习模型和手工特征,结合LIDC数据集,实验表明该方法的预测评分更接近放射科医生的评分。
摘要
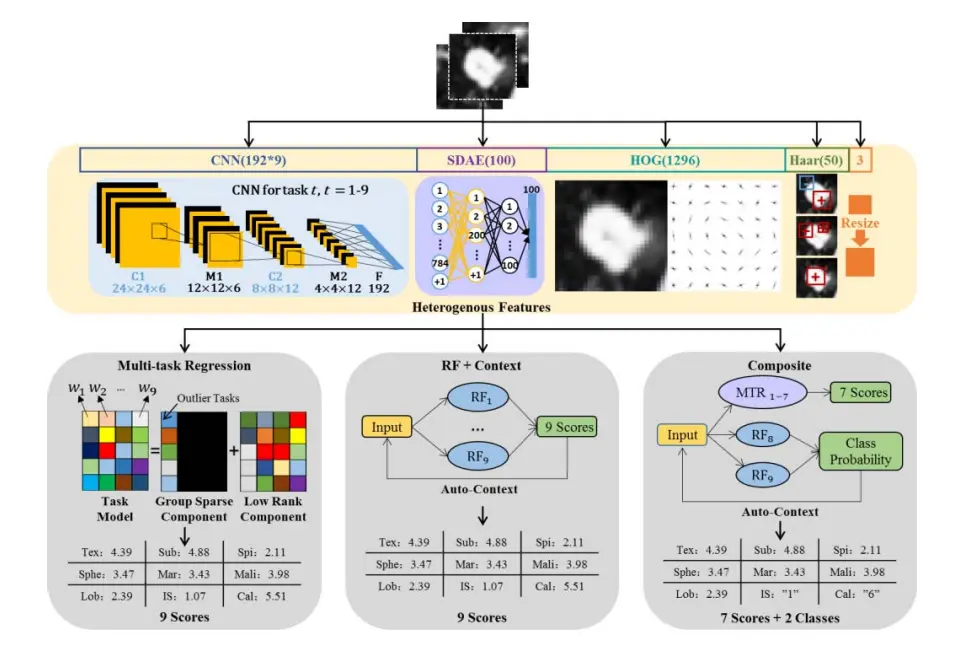
计算机和语义特征之间的间隙是制约临床应用计算机辅助诊断性能的主要因素之一。为了架起这座桥梁,我们开发了三个多任务学习方法(MLT):利用堆叠去噪自编码器和卷积神经网络的深度学习模型衍生的异构计算特征,手工生成的Haar-like和HOG特征,CT图像中肺结节的9个语义特征描述符。我们认为“细刺状”、“纹理”和“边缘”等语义特征之间可能存在一定的关系,可以使用MTL进行探索。LIDC数据集具有丰富的标注信息,很适合这项研究。实验结果表明,与单任务的LASSO和可伸缩网络的回归方法相比,三种MTL方案的预测语义评分更接近于放射科医生的评分。
9个语义特征
- 结节的坚固程度
- 人类检测结节的难易程度
- 结节形状的毛刺程度
- 结节形状的圆度
- 结节的钙化模式
- 结节边缘的定义程度
- 结节为恶性肿瘤的可能性
- 结节形状的分叶程度
- 结节构成类型
方法流程图
需要解决的新问题
新CAD问题面临很大的挑战,可以主要概括为三个方面:
- 我们目标是开发一个自动评分模型来量化大多数语义特征的程度,因此,为每个语义特征的评分设计有效的低级图像特征可能比结节的离散三分法的特征提取问题更复杂。
- 切片的注释评级者之间存在的差异。在某些情况下,评分过程是主观的,并且高度依赖于评分者的经验,所以评级的变化是显著的。
- LIDC数据集中胸部CT扫描切片厚度的变化。由于z方向和x/y方向各向一行分辨率的不同,对纯3D图像特征的计算提出了挑战。
为了解决三个问题,提出了利用多任务学习框架的方法:
尽可能多的计算异构特征。使用SDAE提取一般特征(不需要标签),使用CNN提取针对性强的特征,将这些特征和低级的Harr和HOG特征结合在一起。同时利用MTL进一步探索9个语义特征之间的关系。为避开切片厚度的变化,实现了基于切片的方案,也就是回归模型的训练是用二维切片ROIs 单元进行的,测试阶段通过平均来自组合式切片ROIs的分数来获得肺结节的最终评分。
贡献
该论文的贡献可以概括为三个方面:
- 首先,提出了一种新的CADa方案,对CT图像中描述肺结节的9个语义特征进行定量评估。
- 提出了一种MTL方案,以有效地弥合计算特征与多个临床语义特征之间的差距。
- 异构计算计算特征与MTL方案之间的有效协同的新颖性。
方法
使用神经元生成特征
- 堆叠去噪自编码器
堆叠自编码器(SAE)是一种深度学习模型,通过非监督和监督训练两个阶段来实现。在无监督训练阶段,SAE体系结构是堆叠一个由一个输入层和一个隐藏层组成的两层自编码器来构建的。自编码器由编码器和解码器两部分组成,可以通过寻找合适的编码器和解码器啦实现重构误差的最小化。在没有数据标签的情况下,进行无监督的SDAE训练,因此,其提取的特征对所有语义特征具有通用性。 - 卷积神经网络
CNN模型的训练通常是在监督下进行的。针对9个语义特征使用了9个CNN模型,获得了针对于特定任务的计算特征。对于每一个CNN,将每个语义描述作为一个单独的类,作为分类问题进行训练。
手动生成特征
- 手动Haar-like特征
通过简单的逐块计算来表征低级图像的外观和上下文信息。结节的外观和纹理线索可以通过单块和成对块的Haar-like特征量化。 - 手动HOG特征
HOG使用局部方向梯度直方图描述感兴趣对象形状的一种低级描述符。HOG特征可以用来帮助描述几个形状语义特征。
总结
为了得到计算机术语和医学语义特征的映射关系。使用CNN、SDEA、Haar-like和HOG产生一个异构特征集合,针对医生评分得到的9个语义特征,使用多任务线性回归和随机森林回归产生特征和特定语义之间的最佳映射关系。

















 2396
2396

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









