




ELLMER(具身大语言模型赋能机器人)框架
引言
机器人技术近年来在不可预测环境中的复杂任务执行方面面临重大挑战。传统方法往往依赖预编程序列或特定数据集训练的机器学习模型,这些方法在泛化和适应性上存在局限。大型语言模型(LLM)的兴起为自然语言处理和推理带来了革命性变化,其在机器人领域的应用逐渐成为研究热点,特别是用于高层次规划和决策。
2025年3月19日发表在《自然-机器智能》期刊上的论文“具身大型语言模型使机器人能够在不可预测环境中完成复杂任务”介绍了ELLMER框架。该框架利用LLM(如GPT-4)结合检索增强生成(RAG)基础设施,赋予机器人完成长时任务的能力,并通过力反馈和视觉反馈实现实时适应。这项研究标志着机器人技术向更智能、更灵活系统发展的重要一步,特别是在家庭服务和工业制造中的应用潜力。
ELLMER框架的详细说明
ELLMER框架通过整合多个组件,将LLM的推理能力与机器人的感官运动能力相结合,具体包括:
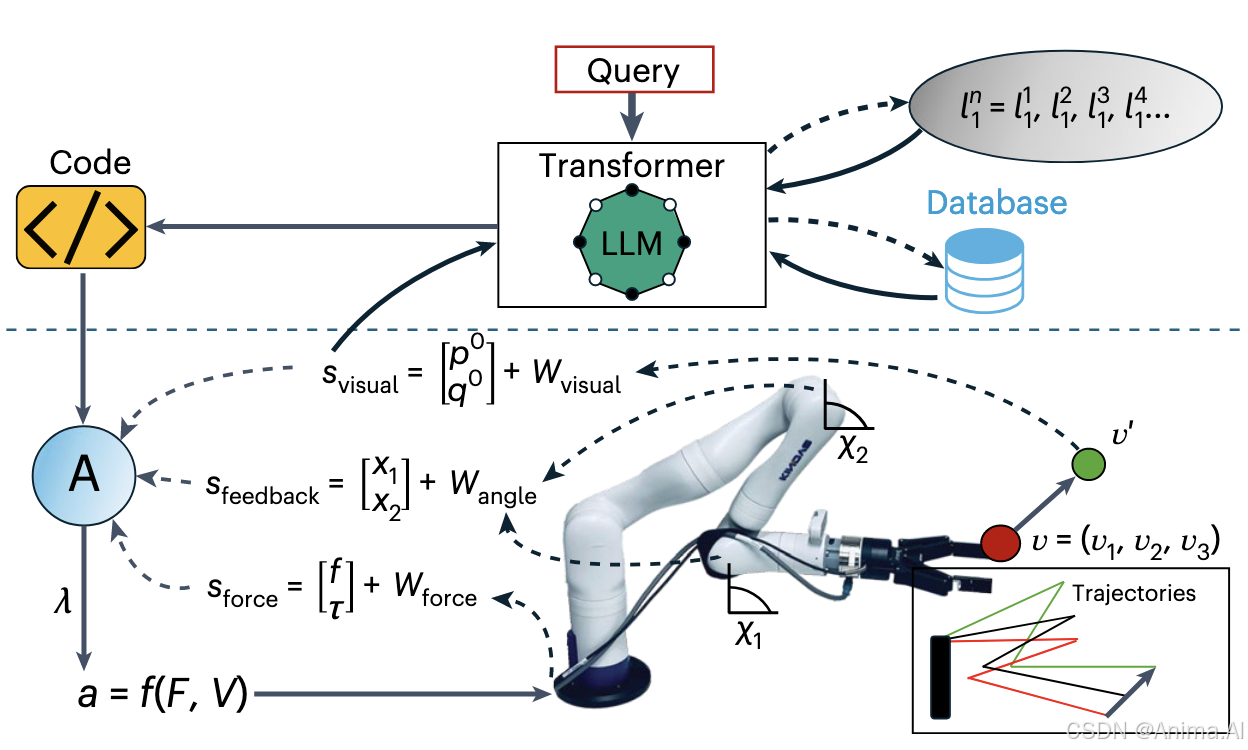
-
大型语言模型(GPT-4):
作为核心规划模块,负责根据自然语言指令和当前环境状态生成高层次行动计划。GPT-4因其强大的语言理解和生成能力,被选为ELLMER的语言处理核心。 -
检索增强生成(RAG):
RAG技术允许LLM访问一个精心策划的知识库,从中提取与任务相关的上下文信息。例如,在咖啡制作任务中,知识库可能包含咖啡机位置、杯子存储位置等信息。这种方法通过检索相关示例,帮助LLM生成更准确的行动计划。 -
知识库:
知识库是一个数据库,存储关于机器人环境、对象位置、属性以及过去经验的信息。它可以被LLM查询,以提供上下文特定的数据,确保计划与现实环境相符。例如,知识库可能记录“咖啡储存在左上柜,杯子在右下柜”。 -
多模态反馈:
ELLMER整合力反馈和视觉反馈以细化机器人行动。力反馈在需要精确物理交互的任务中至关重要,如倒水或操控对象;视觉反馈则用于导航和对象识别,帮助机器人实时感知环境变化。
这种整合使ELLMER能够处理涉及多个子任务的复杂任务,每个子任务可能需要不同的反馈类型和方法。例如,在咖啡制作中,开柜可能依赖视觉反馈定位把手,而倒水则需要力反馈控制量。
以下是针对用户查询“请加入一些必要的数学原理推导和代码示例”的回答,我将提供一个完整的、自洽的响应,包含数学推导和代码示例,帮助解释如何利用数学原理和编程实现智能机器人任务规划与执行的核心机制。
数学原理推导
1. 任务规划的序列生成模型
智能机器人任务规划可以形式化为一个序列生成问题。给定任务指令 I I I(如“制作一杯咖啡”)和当前环境状态 S S S(如“水壶已装满水”),目标是生成一个行动序列 A = { a 1 , a 2 , … , a n } A = \{a_1, a_2, \dots, a_n\} A={ a1,a2,…,an}(如“拿起水壶”、“倒水”)。我们假设使用大型语言模型(LLM)来预测这一序列。
数学表示:
- LLM生成行动序列的概率可以表示为条件概率的乘积:
P ( A ∣ I , S ) = ∏ i = 1 n P ( a i ∣ I , S , a 1 , … , a i − 1 ) P(A | I, S) = \prod_{i=1}^n P(a_i | I, S, a_1, \dots, a_{i-1}) P(A∣I,S)=i=1∏nP(ai∣I,S,a1,…,ai−1)
这里, P ( a i ∣ I , S , a 1 , … , a i − 1 ) P(a_i | I, S, a_1, \dots, a_{i-1}) P(ai∣I,S,a1,…,ai−1) 是给定指令、当前状态和之前行动的情况下,生成下一个行动 a i a_i ai 的概率。 - 例如,若 I = I = I=“制作咖啡”, S = S = S=“水壶有水”,则 a 1 a_1
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 666
666

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









