




RAG(检索增强生成)简介:
检索增强生成(RAG)是一种优化大型语言模型(LLM)输出的方法,使其能够在生成响应之前引用训练数据之外的权威知识库。LLM 使用海量数据进行训练,拥有数十亿个参数,能够执行诸如回答问题、翻译语言和完成句子等任务。RAG 在 LLM 强大功能的基础上,通过访问特定领域或组织的内部知识库,而无需重新训练模型,进一步提升了其输出的相关性、准确性和实用性。这是一种经济高效的改进方法,适用于各种情境。
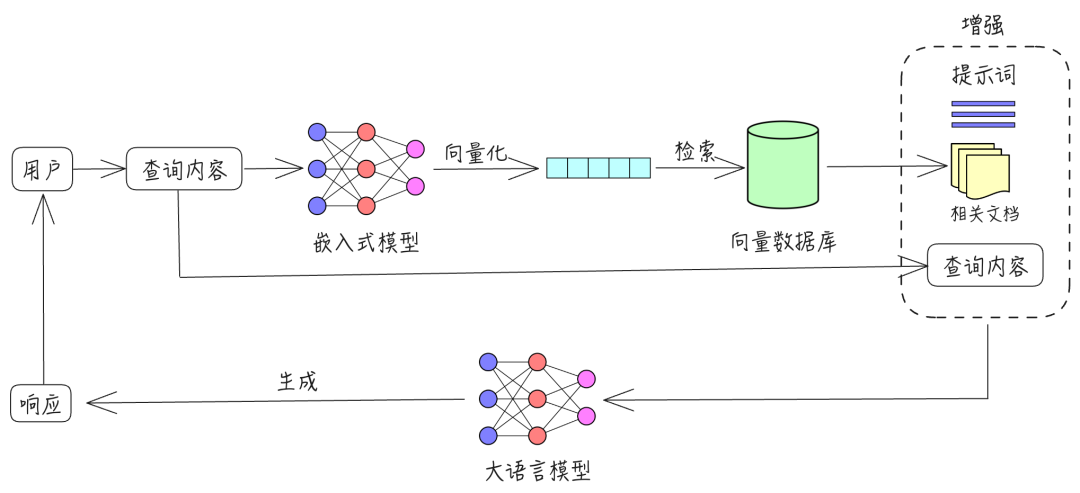
RAG 包含三个主要过程:检索、增强和生成。
- 检索:根据用户的查询内容,从外部知识库获取相关信息。具体而言,将用户的查询通过嵌入模型转换为向量,以便与向量数据库中存储的相关知识进行比对。通过相似性搜索,找出与查询最匹配的前 K 个数据。
- 增强:将用户的查询内容和检索到的相关知识一起嵌入到一个预设的提示词模板中。
- 生成:将经过检索增强的提示词内容输入到大型语言模型中,以生成所需的输出。
以下是流程图:
RAG解决的LLM应用痛点:
大型语言模型(LLM)在应用中面临一些已知挑战,包括:
- 在没有答案的情况下提供虚假信息。
- 当用户需要特定的当前响应时,提供过时或通用的信息。
- 从非权威来源创建响应。
- 由于术语混淆,不同的培训来源使用相同的术语来谈论不同的事情,从而产生不准确的响应。
RAG(检索增强生成)旨在缓解甚至解决以下大模型落地应用的痛点:
- 垂直领域知识的幻觉:通过检索外部权威知识库,RAG 可以提供更准确和可靠的领域特定知识,减少生成幻觉的可能性。
- 大模型知识持续更新的困难:无需重新训练模型,RAG 可以通过访问最新的外部知识库,保持输出的时效性和准确性。
- 无法整合长尾语义知识:RAG 能够从广泛的知识库中检索长尾语义知识,从而生成更丰富和全面的响应。
- 可能泄露的训练数据隐私问题:通过使用外部知识库而不是依赖内部训练数据,RAG 减少了隐私泄露的风险。
- 支持更长的上下文:RAG 可以通过检索相关信息,提供更长和更详细的上下文支持,从而提高响应的质量和连贯性。
RAG 工作类型:
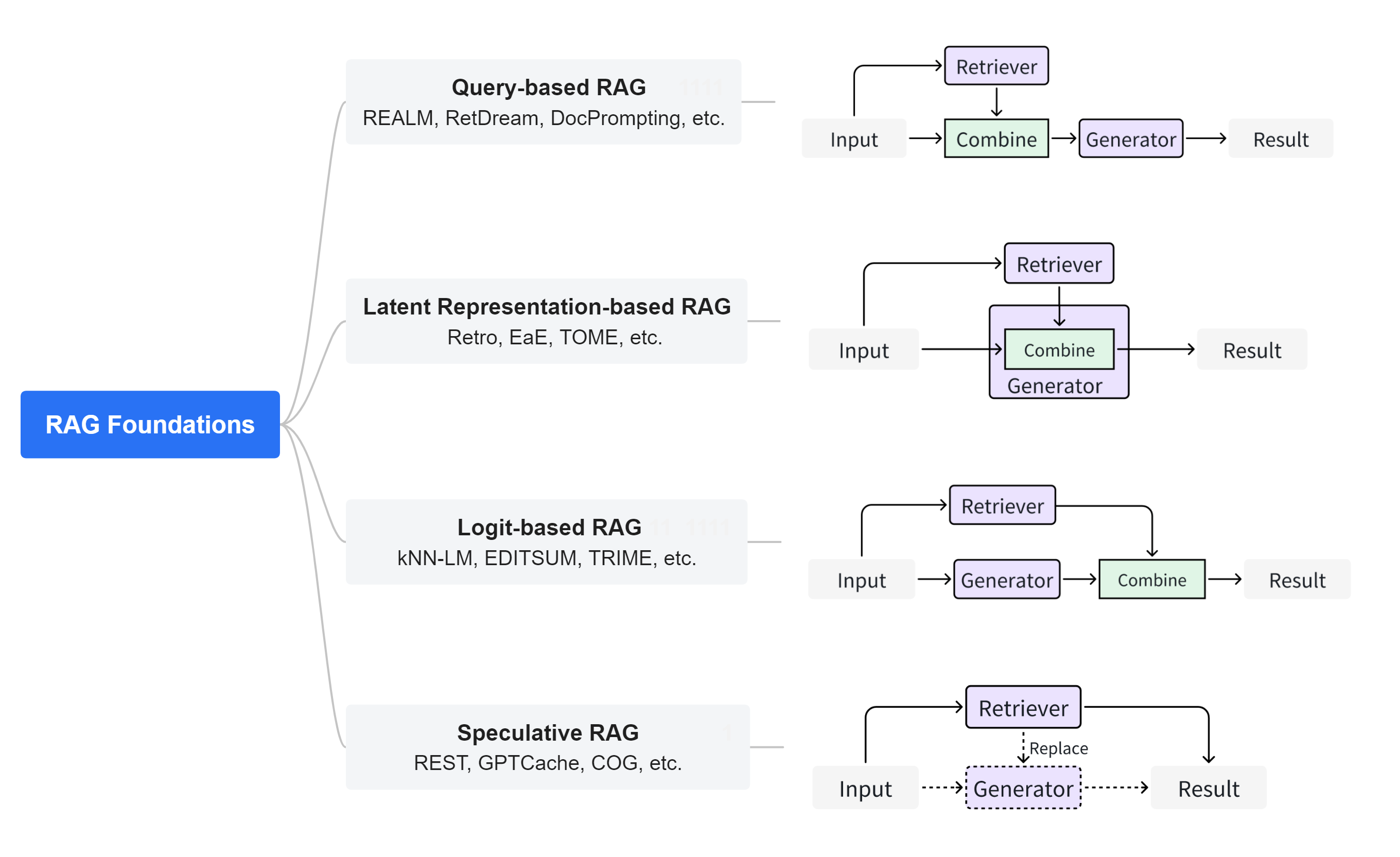
-
Query-based RAG:基于查询的RAG也称为提示增强。它将用户的查询与从文件中检索到的信息直接整合到语言模型输入的初始阶段。这种模式是RAG应用中广泛采用的方法。一旦检索到文档,它们的内容就会与用户的原始查询合并,创建一个组合输入序列。这个增强序列随后被输入到预先训练好的语言模型中,以生成回复。
- Latent Representation-based RAG:在基于隐式表示的RAG框架中,检索到的对象作为隐式表示融入生成模型,从而提高模型的理解能力和生成内容的质量。在这种框架中,生成模型与检索对象的潜在表征相互作用,提高了生成内容的准确性。这种方法在处理代码、结构化知识和多模态数据方面显示出巨大的潜力和适应性。特别是在代码相关的领域,如EDITSUM、BASHEXPLAINER和RetrieveNEdit等技术,采用FiD方法,通过编码器处理的融合来促进整合。Re2Com和RACE等方法也采用了为不同类型输入设计多个编码器的设计。
- Logit-based RAG:在基于对数似然的RAG中,生成模型在解码过程中通过对数融合检索信息。通常,对数通过模型求和或组合,以产生逐步生成的概率。在代码到文本转换任务中,Rencos并行生成检索代码的多个摘要候选,然后使用编辑距离进行规范化,计算最终概率以选择最匹配原始代码的摘要输出。在代
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 7039
7039

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











