



 本文介绍如何使用Scrapy_redis工具包配置分布式爬虫,包括下载工具包、配置调度器、修改爬虫文件及远程连接MYSQL和Redis的具体步骤。
本文介绍如何使用Scrapy_redis工具包配置分布式爬虫,包括下载工具包、配置调度器、修改爬虫文件及远程连接MYSQL和Redis的具体步骤。
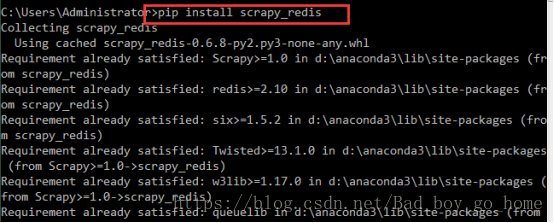
1.使用命令行工具下载工具包scrapy_redis
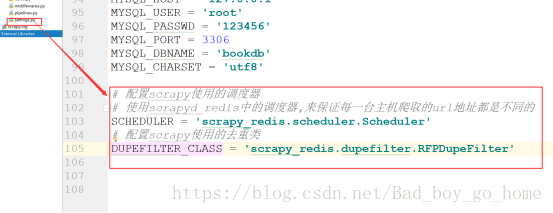
2.使用pycharm打开项目,找到settings文件,配置scrapy项目使用的调度器及过滤器

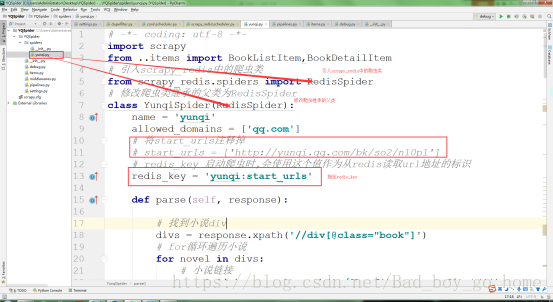
3.修改spider爬虫文件
4.如果连接的有远程服务,泪如MYSQL,Redis等,需要将远程服务连接开启,保证在其他主机上能够成功连接
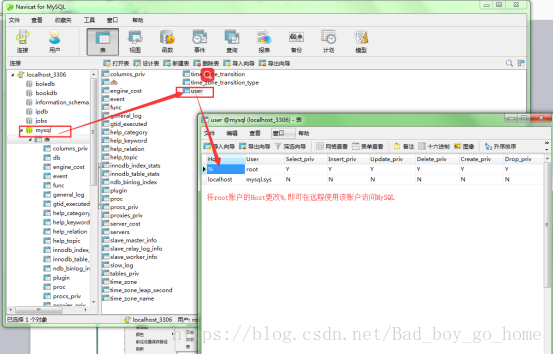
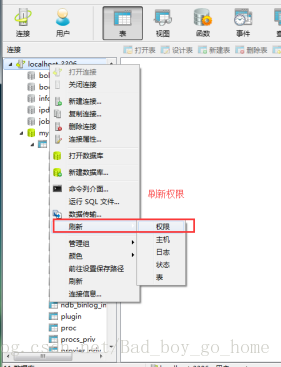
(注意:在更改完mysql后必须刷新权限)
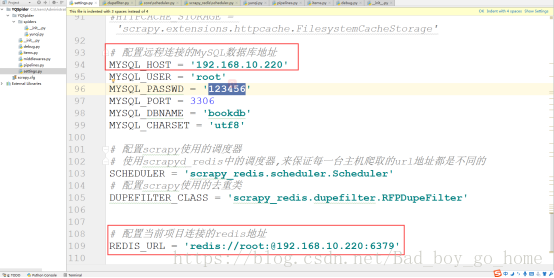
5.配置远程连接的MYSQL及redis地址
1.使用命令行工具下载工具包scrapy_redis
2.使用pycharm打开项目,找到settings文件,配置scrapy项目使用的调度器及过滤器
3.修改spider爬虫文件
4.如果连接的有远程服务,泪如MYSQL,Redis等,需要将远程服务连接开启,保证在其他主机上能够成功连接
(注意:在更改完mysql后必须刷新权限)
5.配置远程连接的MYSQL及redis地址
 2147
2147

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言


























