




讲解之前,我们先来看一下该方法的官方注释:

翻译过来的意思大概是:
“返回通过将字符串中最左边、不重叠的模式出现替换为替代字符串 repl 后获得的字符串。repl 可以是一个字符串或一个可调用对象;如果是一个字符串,其中的反斜杠转义会被处理。如果它是一个可调用对象,它会接收匹配对象(Match 对象)并必须返回一个用于替代的字符串。”
现在我们有了一个大概的认识了,下面我们就开始了解具体的使用方式。
re.sub() 方法是 Python 中正则表达式库 re 提供的用于替换字符串中匹配正则表达式的部分的函数。它的基本语法如下:
re.sub(pattern, repl, string, count=0, flags=0)
各参数的意思如下:
-
pattern:正则表达式模式,用于匹配输入字符串中的子字符串。可以使用正则表达式语法来定义模式,以便匹配你要替换的内容。 -
repl:替换字符串,用于替换匹配到的子字符串。你可以直接提供一个字符串,或者使用一个函数来生成替换文本。如果提供的是函数,则该函数应接受一个匹配对象(match object)作为参数,并返回替换的字符串。 -
string:输入字符串,包含要执行替换操作的文本。 -
count(可选):指定替换的最大次数。默认值为 0,表示替换所有匹配到的子字符串。如果提供正整数值,它将限制替换的次数。 -
flags(可选):用于指定正则表达式的标志,例如re.IGNORECASE用于忽略大小写。
下面是一些示例,演示如何使用 re.sub() 方法:
import re
# 简单替换:将所有的"apple"替换为"orange"
text = "I have an apple, and you have an apple."
new_text = re.sub(r"apple", "orange", text)
print(new_text)
# 使用函数生成替换文本:将匹配到的数字加一
text = "The prices are: $10, $20, $30."
def increment(match):
number = int(match.group(0))
incremented = str(number + 1)
return incremented
new_text = re.sub(r"\d+", increment, text)
print(new_text)
# 限制替换次数:只替换前两个"cat"
text = "I have a cat, a cat, and a cat."
new_text = re.sub(r"cat", "dog", text, count=2)
print(new_text)
在上述示例中,我们演示了不同情况下如何使用 re.sub() 方法进行替换。
输出结果如下:
I have an orange, and you have an orange.
The prices are: $11, $21, $31.
I have a dog, a dog, and a cat.
当使用 re.sub() 方法时,有一些注意事项和最佳实践:
-
正则表达式模式(
pattern)应该非常小心,以确保正确匹配所需的文本。不正确的模式可能会导致意外的替换或匹配失败。 -
当提供替换字符串(
repl)时,要小心替换文本的格式。确保它与输入字符串兼容,否则可能会出现格式错误。 -
如果你使用函数来生成替换文本,确保函数返回适当的字符串。函数的输入是匹配对象(match object),你可以使用
match.group(0)获取整个匹配的字符串,并使用它来生成替换文本。 -
调整替换次数(
count)时要小心。如果你想替换所有匹配项,将count参数留空或设置为 0。如果你想限制替换的次数,确保你明确了解替换的数量。 -
考虑正则表达式的性能。复杂的正则表达式可能导致性能问题,特别是在大文本上。尽量编写高效的正则表达式,以避免性能瓶颈。
-
使用适当的正则表达式标志(
flags)来匹配你的需求。例如,使用re.IGNORECASE标志来进行大小写不敏感的匹配。 -
对于大规模替换操作,要注意备份原始文本,以防万一需要还原。一种方式是在替换前创建输入字符串的副本。
这里再贴一下平时用到的在线正则验证工具:
有很多在线工具和网站可以用来验证和测试正则表达式。这些工具可以帮助你编写和调试正则表达式,以确保它们按预期工作。
-
RegExr:https://regexr.com/
- RegExr 是一个功能强大的在线正则表达式测试工具,提供实时匹配和替换功能。
- RegExr 是一个功能强大的在线正则表达式测试工具,提供实时匹配和替换功能。
-
Regex101:https://regex101.com/
- Regex101 具有强大的正则表达式测试功能,允许你输入正则表达式和文本来进行匹配和替换操作。
- Regex101 具有强大的正则表达式测试功能,允许你输入正则表达式和文本来进行匹配和替换操作。
-
Debuggex:https://www.debuggex.com/
- Debuggex 是一个交互式正则表达式测试工具,它以图形方式展示正则表达式的匹配过程,有助于理解匹配的工作原理。
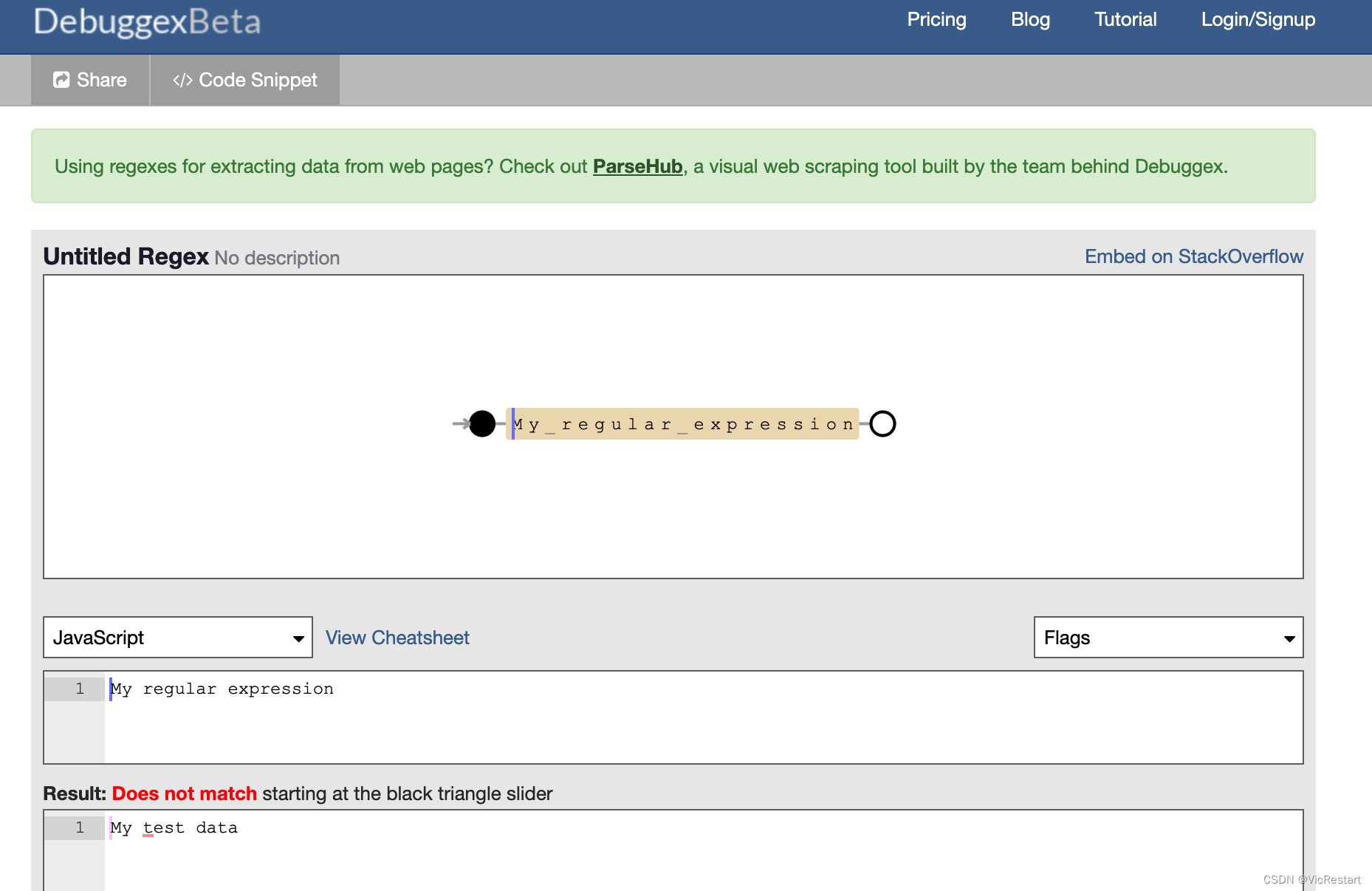
- Debuggex 是一个交互式正则表达式测试工具,它以图形方式展示正则表达式的匹配过程,有助于理解匹配的工作原理。
这些工具通常提供可视化界面,实时反馈和解释功能,帮助你更轻松地编写和调试正则表达式。你可以在这些工具中输入正则表达式模式和待匹配的文本,然后查看匹配结果,以确保你的正则表达式按照预期工作。



















 828
828

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











