




 文章深入探讨了ClickHouse中ReplicatedMergeTree与Distributed引擎如何在多副本间选择数据源,详细解析了从SQL查询到实际数据读取的全流程,重点关注了副本延迟、本地优先策略及远程副本回退机制。
文章深入探讨了ClickHouse中ReplicatedMergeTree与Distributed引擎如何在多副本间选择数据源,详细解析了从SQL查询到实际数据读取的全流程,重点关注了副本延迟、本地优先策略及远程副本回退机制。
在使用ReplicatedMergeTree引擎和Distributed引擎的时候,对于同一张表,服务器上存在多个副本,在查询数据的时候,是如何在这些副本之间进行选择的呢?结合源码来试着分析一下...
对于一条SELECT SQL,从以下方法开始:
pipeline.streams = storage->read(required_columns, query_info, context, processing_stage, max_block_size, max_streams);如图:
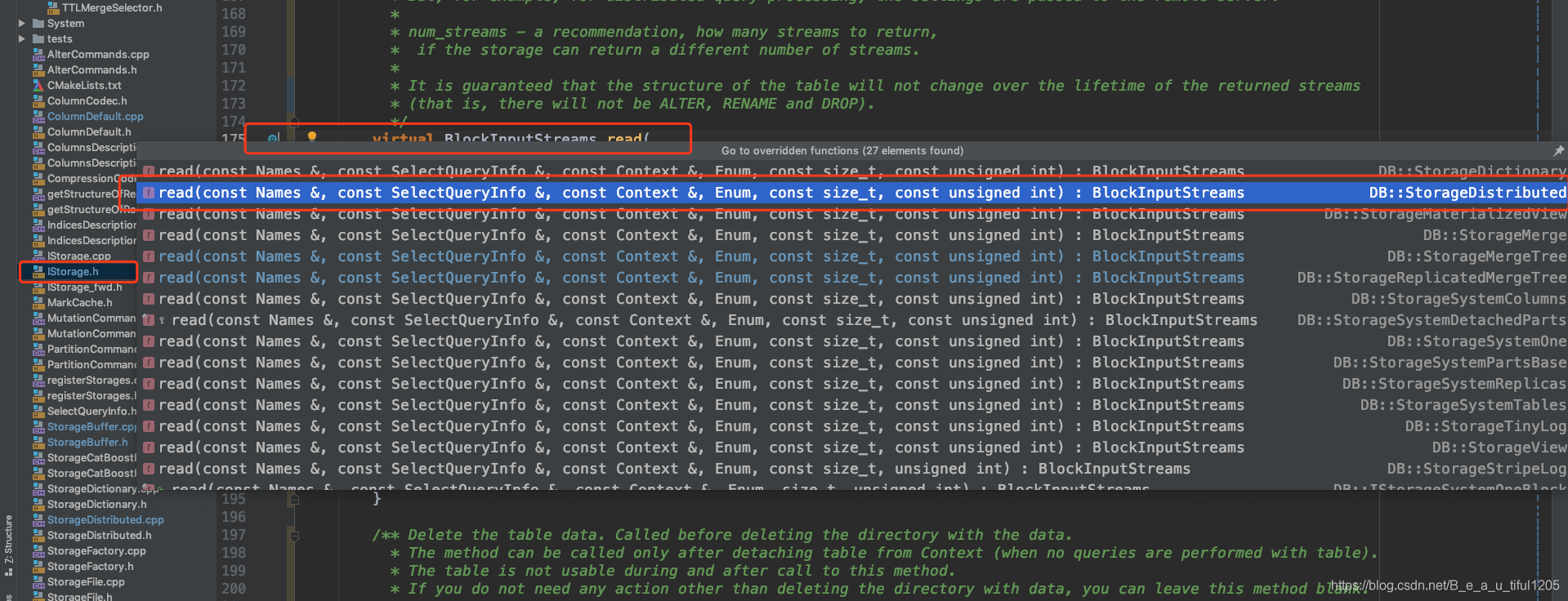
进入到这个方法中,主要步骤包括修改AST(修改表名)、物化header、构建select_stream_factory等,最后执行ClusterProxy::executeQuery()方法,简化代码如下:
BlockInputStreams StorageDistributed::read(
const Names & /*column_names*/,
const SelectQueryInfo &query_info,
const Context &context,
QueryProcessingStage::Enum processed_stage,
const size_t /*max_block_size*/,
const unsigned /*num_streams*/) {
auto cluster = getCluster();
const Settings &settings = context.getSettingsRef();
//修改AST, 修改表名
const auto &modified_query_ast = rewriteSelectQuery(......);
//header, 应该是列名那行, 即Structure of query result
Block header = materializeBlock(......);
ClusterProxy::SelectStreamFactory select_stream_factory = ......;
......
//重点方法
return ClusterProxy::executeQuery(
select_stream_factory, cluster, modified_query_ast, context, settings);
}进入ClusterProxy::executeQuery()方法, 会设置网络带宽限制,然后遍历数据的所有分片,对每个分片执行createForShard()方法,简化代码如下:
BlockInputStreams executeQuery(
IStreamFactory & stream_factory, const ClusterPtr & cluster,
const ASTPtr & query_ast, const Context & context, const Settings & settings)
{
BlockInputStreams res;
const std::string query = queryToString(query_ast);
......
/// Network bandwidth limit, if needed. 网络带宽限制
ThrottlerPtr throttler;
if (settings.max_network_bandwidth || settings.max_network_bytes){......}
//遍历数据的所有的分片,针对每个分片
for (const auto & shard_info : cluster->getShardsInfo())
stream_factory.createForShard(shard_info, query, query_ast, new_context, throttler, res);
return res;
}进入到createForShard()方法,代码逻辑还是比较清晰的,先定义了emplace_local_stream和emplace_remote_stream,然后根据prefer_localhost_replica和shard_info.isLocal()这两个条件判断使用local_stream还是remotr_stream,简化代码如下:
//遍历数据的所有的分片,针对每个分片
void SelectStreamFactory::createForShard(
const Cluster::ShardInfo &shard_info,
const String &query, const ASTPtr &query_ast,
const Context &context, const ThrottlerPtr &throttler,
BlockInputStreams &res) {
auto emplace_local_stream = [&]()//将 数据流 放在本地
{
res.emplace_back(createLocalStream(query_ast, context, processed_stage));
};
auto emplace_remote_stream = [&]()//将 数据流 发送给远程服务器
{
//构建RemoteBl 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 2068
2068

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









