






1、pandas常用数据结构
一维数据结构 Series
当然先要引入pandas
import pandas as pd
(1)字典 转 Series结构
例1:
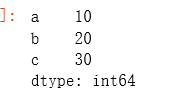
d = {'a': 10, 'b': 20, 'c': 30}
pd.Series(d)
结果:
例2:
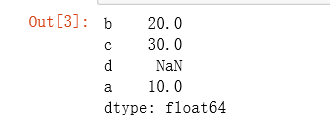
d = {'a': 10, 'b': 20, 'c': 30}
pd.Series(d, index=['b', 'c', 'd', 'a'])
(2)numpy -> Series
例1:
import numpy as np
data = np.random.randn(5)
data
结果:
array([-0.47027885, -0.45086885, -0.12758638, -0.52816193, 1.44307384])
例2:
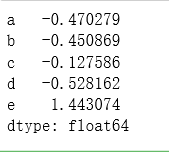
index = ['a', 'b', 'c', 'd', 'e']
s = pd.Series(data, index=index)
s
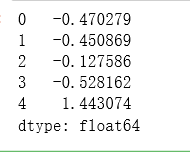
s = pd.Series(data)
s
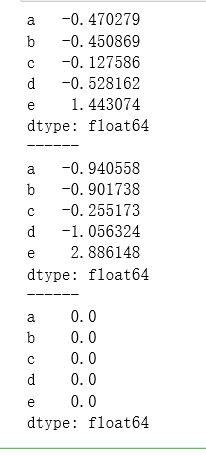
print(s)
print('--------------')
print(s['a'])

print(s)
print('------')
print(s*2)
print('------')
print(s-s)
二维数据 DataFrame
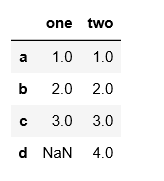
d = {'one': pd.Series([1., 2., 3.], index=['a', 'b', 'c']), 'two':pd.Series([1., 2., 3., 4.], index=['a','b','c','d'])}
df = pd.DataFrame(d)
df
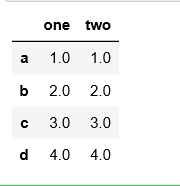
d = {'one': [1., 2., 3., 4.], 'two':[1., 2., 3., 4.]}
df = pd.DataFrame(d, index=['a', 'b', 'c', 'd'])
df
转为Dataframe的方法
•from_csv()
•from_dict()
•from_items()
•from_records()
d = [('A',[1,2,3]), ('B', [4,5,6])]
c = ['one', 'two', 'three']
df = pd.DataFrame.from_items(items=d, columns=c, orient='index')
df

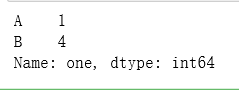
列选择
df['one']
删除列
df.pop('one')
df
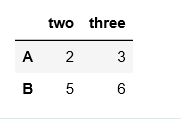
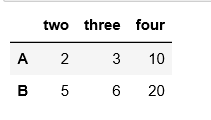
插入一个列
df.insert(2, 'four', [10, 20])
df
2、pandas的基础操作
(1)数据读取与存储
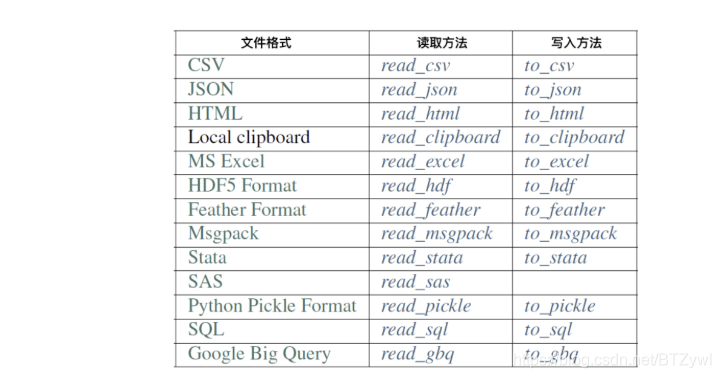
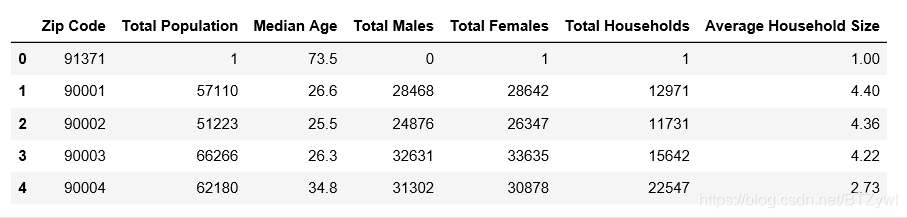
import pandas as pd
pd.read_csv('los_census.csv').head()
结果:
pd.read_table('los_census.txt').head()
结果:

pd.read_table('los_census.txt', sep=',').head()
结果:
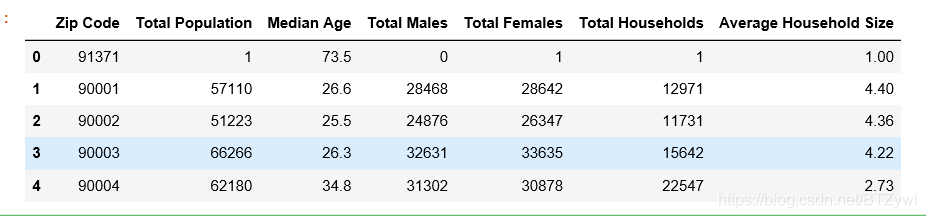
pd.read_table('los_census.csv', sep=',').head()
结果:
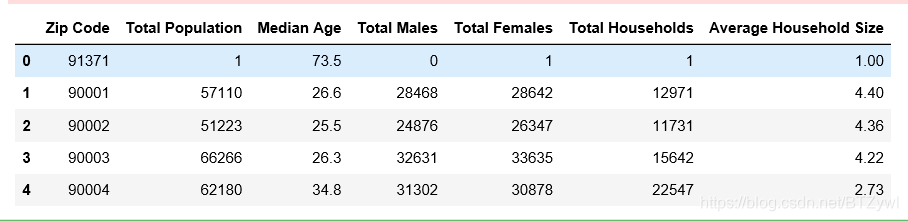
pd.read_csv('los_census.csv', header=1).head() # 把第二行作为列名
结果:
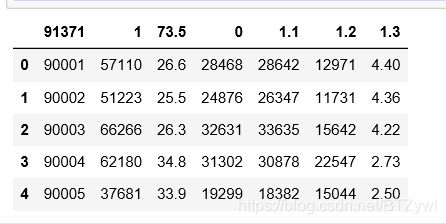
pd.read_csv('los_census.csv', names=['A', 'B', 'C', 'D', 'E', 'F', 'G']).head() # 自定义列名
结果:
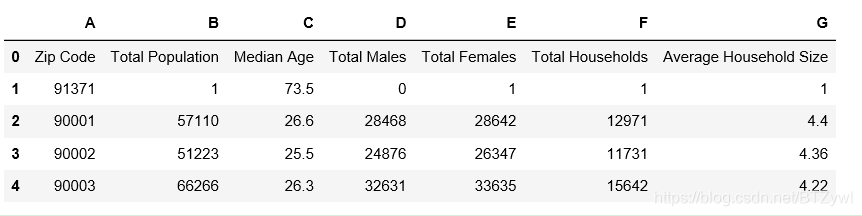
df_los_census = pd.read_csv('los_census.csv')
type(df_los_census)
结果:
pandas.core.frame.DataFrame
Head && Tail
df_los_census.head() # 默认前5行
结果: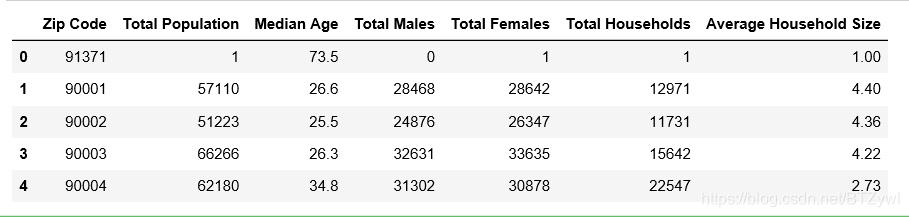
df_los_census.head(7) # 查看前7行
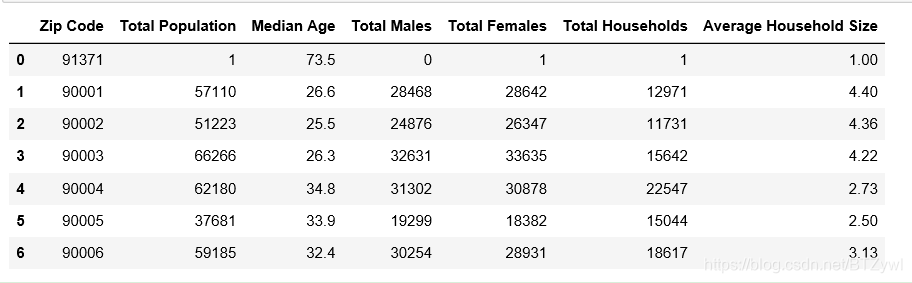
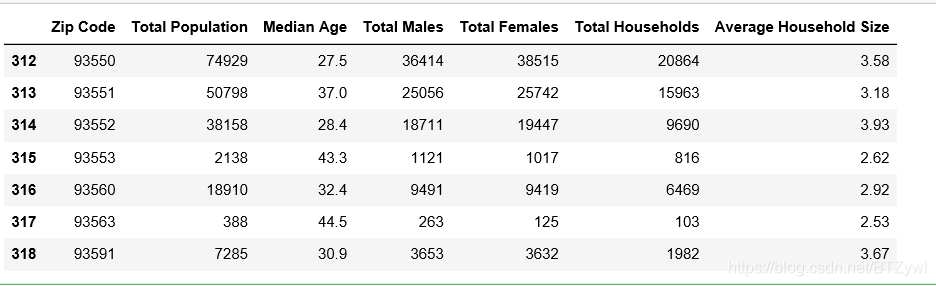
df_los_census.tail() # 默认显示 最后5行
结果:
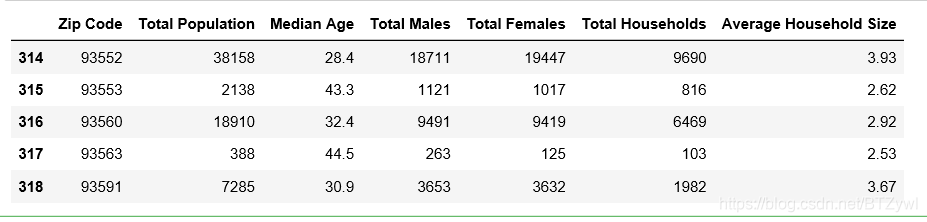
df_los_census.tail(7)
统计方法
df_los_census.describe() # 对数据集的 概览
结果:
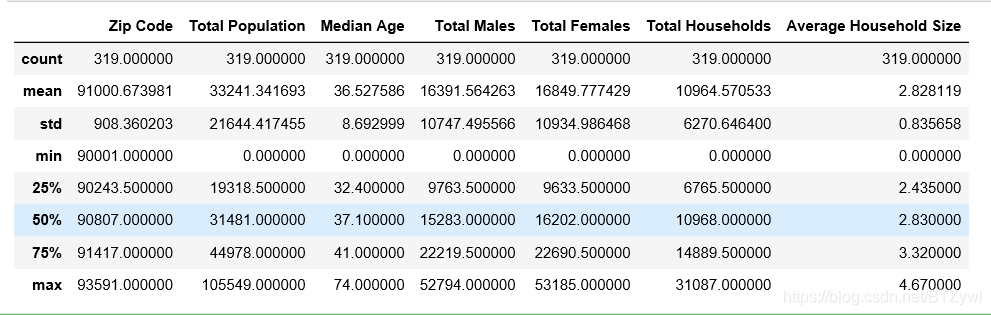
df_los_census.idxmin() # 每一列最小值 对应的索引号
结果:
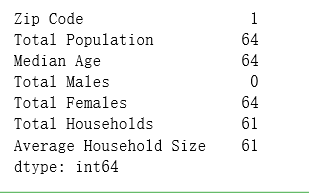
df_los_census.idxmax()# 每一列最大值 对应的索引号
结果:
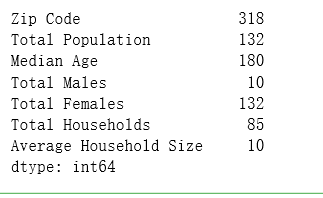
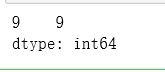
# 统计非空数据的数量 count()
df_los_census.count()
结果:
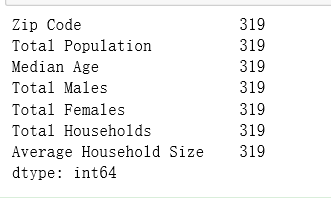
# value_counts
import numpy as np
s = pd.Series(np.random.randint(0,9, size=10))
print(s)
print('---------分割线----------')
print(s.value_counts())
结果:

计算
df_los_census.sum()
结果:

df_los_census.mean()
结果:

df_los_census.median()
结果:

标签对齐
# reindex
s = pd.Series(data=[1,2,3,4,5], index=['a', 'b', 'c', 'd','e'])
print(s)
print('-------分割线---------')
print(s.reindex(['e', 'b', 'f', 'd']))
结果:

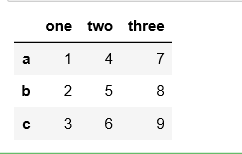
df = pd.DataFrame(data={'one':[1,2,3], 'two':[4,5,6], 'three':[7,8,9]}, index=['a', 'b', 'c'])
df
结果:
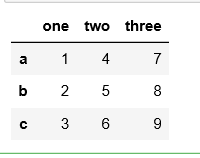
df.reindex(index=['b', 'c', 'a'], columns=['three', 'two', 'one'])
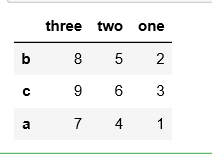
df
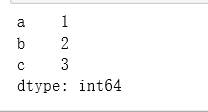
# Series按照 DataFrame的index进行重排
s.reindex(df.index)
结果:
排序
(1)按索引排序
df = pd.DataFrame(data={'one':[1,2,3], 'two':[4,5,6], 'three':[7,8,9], 'four':[10,11,12]}, index=['a', 'c', 'b'])
df
结果:
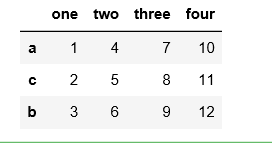
df.sort_index()
结果:
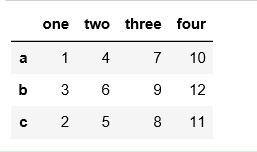
df.sort_index(ascending=False)
结果:
按值进行排序
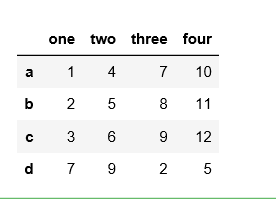
df= pd.DataFrame(data={'one':[1,2,3,7], 'two':[4,5,6,9], 'three':[7,8,9, 2], 'four':[10,11,12,5]}, index=['a', 'b', 'c','d'])
df
结果:
df.sort_values(by='three')
结果:
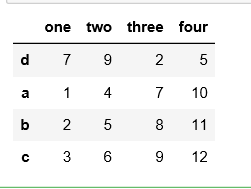
df[['one', 'two', 'three']].sort_values(by=['one', 'two'])
结果:

3、pandas的数据选择
1)数据选择
(1)iloc
import pandas as pd
df = pd.read_csv('los_census.csv')
df.head()
# 前三行
df.iloc[:3]

# 选择特定的一行
df.iloc[5]

# 取 索引为1 3 5
df.iloc[[1, 3, 5]]

# 取列
df.iloc[:, 1:4] # 1:4 前闭后开
(2)loc
import numpy as np
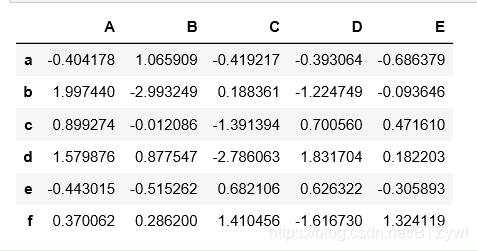
df = pd.DataFrame(np.random.randn(6,5), index=list('abcdef'), columns=list('ABCDE')) # ['a','b'....]
df
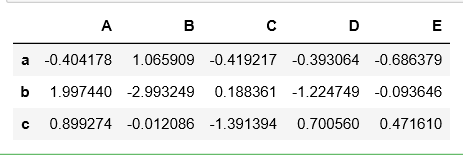
df.loc['a':'c'] # 传入 索引名
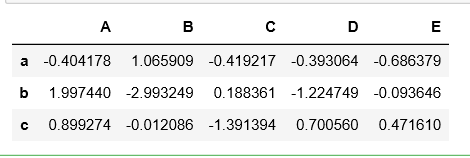
df.iloc[:3] # 传入整型
df.loc[['a', 'c', 'd']]
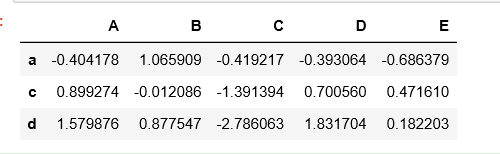
# 列的选择
df.loc[:, 'B':'D'] # 前闭后闭
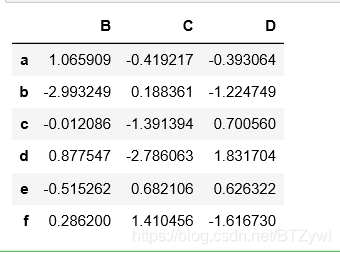
# 选择1,3行 和C后面所有的列
df.loc[['a','c'], 'C':]
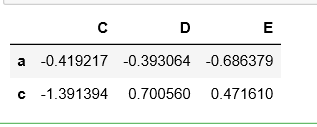
2)数据的随机取样
s = pd.Series([0,1,2,3,4,5,6,7,8,9])
s.sample()
结果:
s.sample(n=5) # 随机取5个

s.sample(frac=.6) # 采样60%

# DataFrame
df = pd.DataFrame(np.random.randn(6,5),index=list('abcdef'), columns=list('ABVDE'))
df
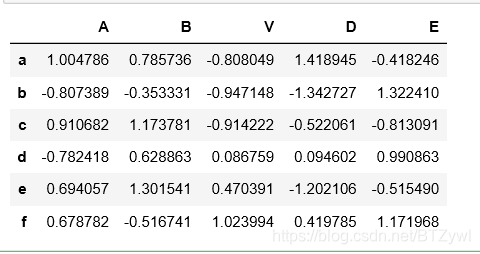
# 随机采用 3行
df.sample(n=3)
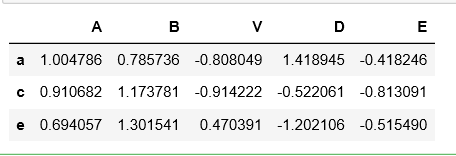
# 随机采样3列
df.sample(n=3, axis=1)
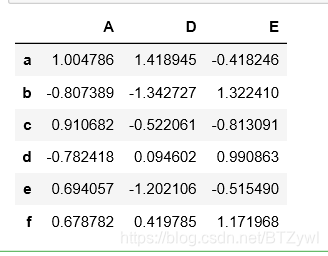
df.sample() # 随机取一行

3)条件语句的选择
s = pd.Series(range(-5, 5))
s

# 找出 <-2 或者 >1 的数
s[(s < -2) | (s > 1)] # 可以numpy的时候 fancy indexing类比

4)DataFrame
df = pd.DataFrame(np.random.randn(6,5),index=list('abcdef'), columns=list('ABVDE'))
df
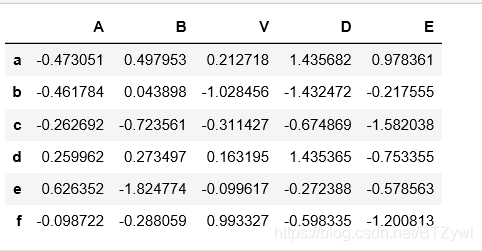
# 找出 B这个维度上的数字>0 或者 D这个维度上的数字<0 所有的行
df[(df['B'] > 0) | (df['D'] < 0)]
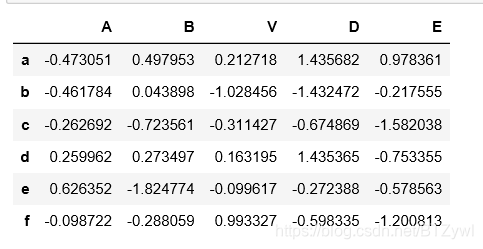
df['B']

5)where
df = pd.DataFrame(np.random.randn(6,5),index=list('abcdef'), columns=list('ABVDE'))
df
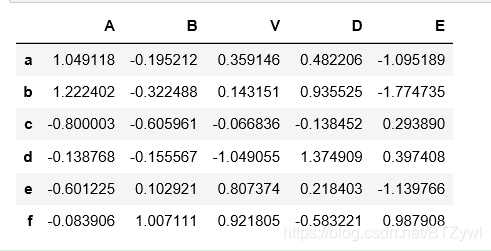
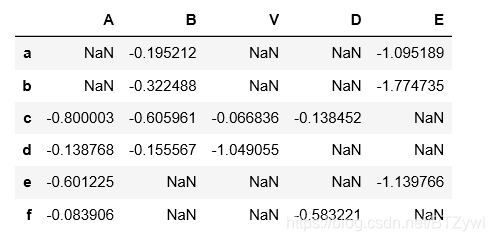
df.where(df < 0)
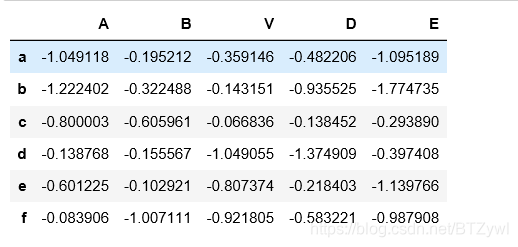
df.where(df < 0, -df) # where实际上 起到了 匹配和替换的效果
6)query
df = pd.DataFrame(np.random.rand(10,5), columns=list('abcde'))
df
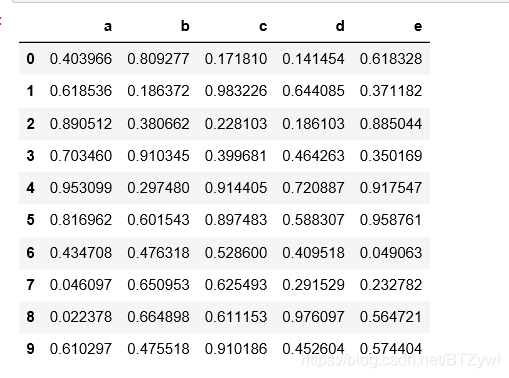
# (a < b) & (b<c) 所有的行
df.query('(a < b) & (b<c)')
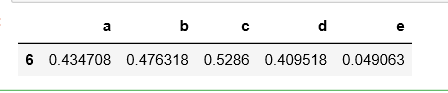
df[(df.a < df.b) & (df.b < df.c)]

df.query?
这个好像是出现所有query的函数的方法,如果错了,望指正
4、pandas-缺失值的处理
缺失值处理
import pandas as pd
import numpy as np
df = pd.DataFrame(np.random.rand(5,5), index=list('cafed'), columns=list('ABCDE'))
df
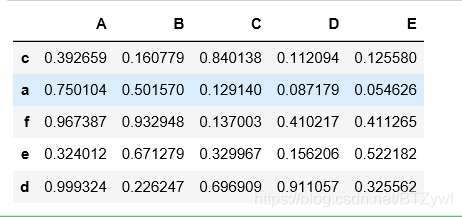
df.reindex(list('abcde'))
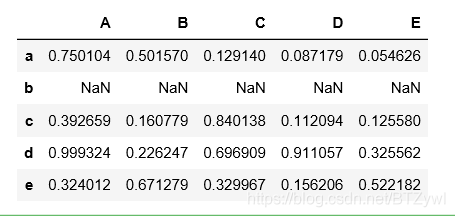
df2 = df.reindex(list('abcde'))
# 每个元素是否为 缺失值
df2.isnull()

df2.notnull() # 是否 非缺失值

# 时间序列缺失值的检测
df2.insert(value=pd.Timestamp('2019-9-10'), loc=0, column='T')
df2
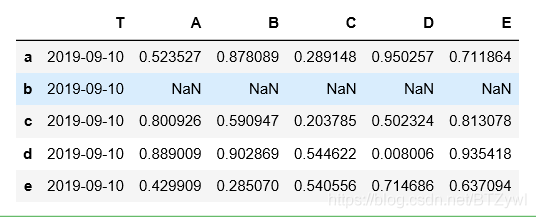
df2.loc[['a','c','e'], ['T']] = np.nan
df2
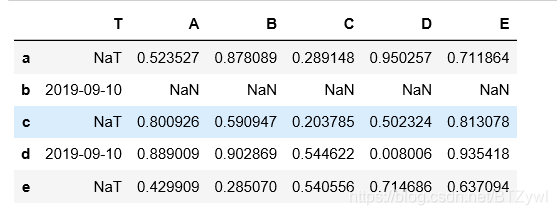
df2.isnull()

df2.notnull()

填充缺失值
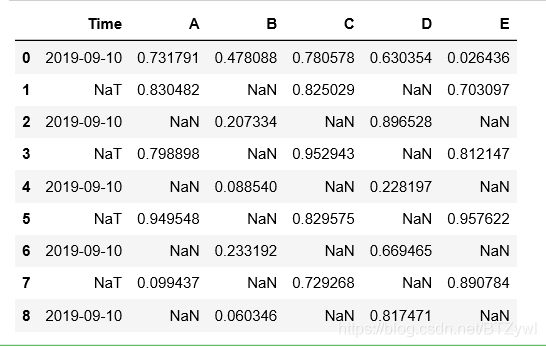
df = pd.DataFrame(np.random.rand(9,5), columns=list('ABCDE'))
df.insert(value=pd.Timestamp('2019-9-10'), loc=0, column='Time')
df.iloc[[1,3,5,7], [0,2,4]] = np.nan
df.iloc[[2,4,6,8], [1,3,5]] = np.nan
df
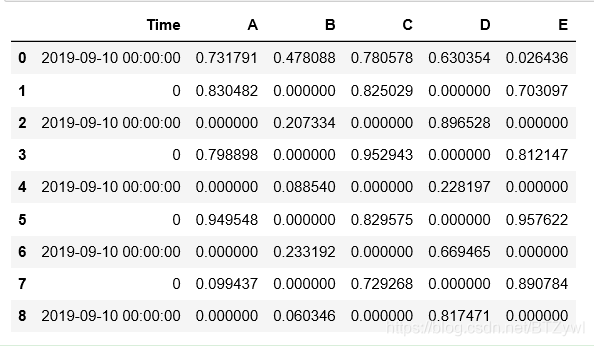
# 所有的NaN填充为0
df.fillna(0)
# 前面的数, 填充给缺失值
df.fillna(method='pad')
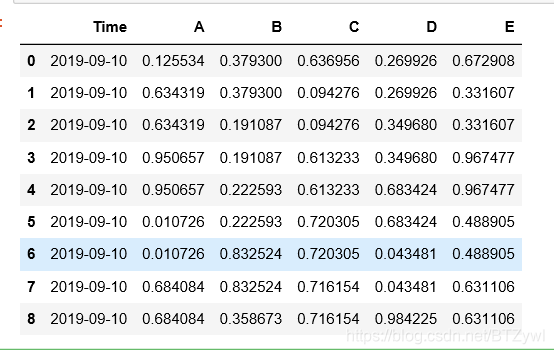
df.fillna(method='bfill') # 缺失值角度 拿后面的数填充

df.iloc[[3,5], [1,3,5]] = np.nan
df
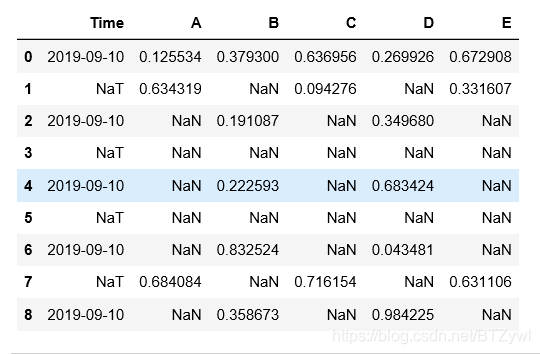
df.fillna(method='pad')
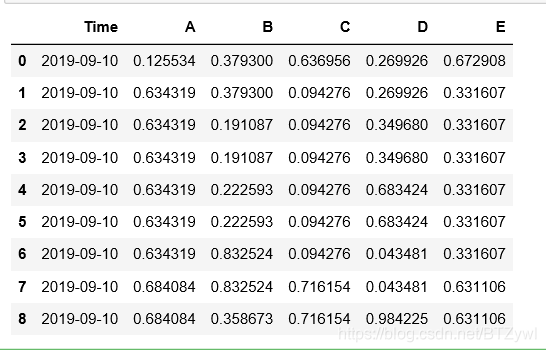
# 遇到连续缺失值的情况, 只想填充1次
df.fillna(method='pad', limit=1)
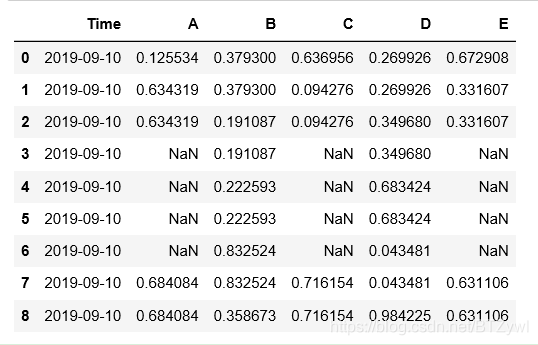
# 利用均值填充
df.fillna(df.mean()['C':'E'])
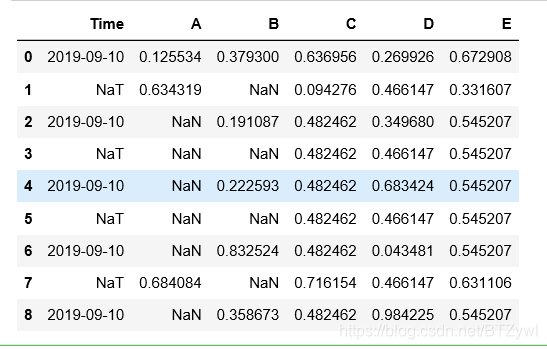
清除缺失值
df.dropna()
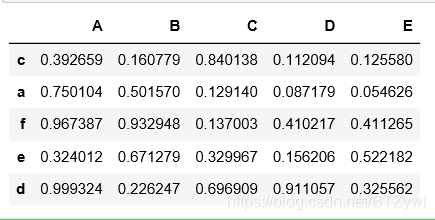
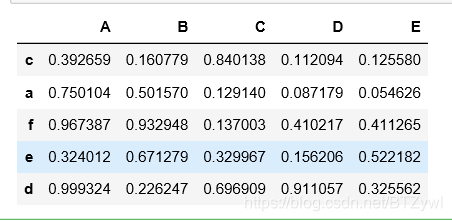
df.dropna(axis=1)
插值 interpolate()
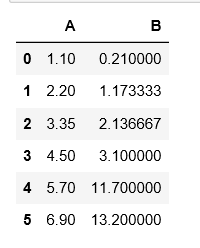
df = pd.DataFrame({'A': [1.1, 2.2, np.nan,4.5,5.7,6.9], 'B':[.21, np.nan, np.nan, 3.1, 11.7, 13.2]})
df
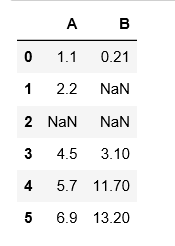
df_interpolate = df.interpolate()
df_interpolate
%matplotlib inline
from matplotlib import pyplot as plt
plt.style.use('ggplot')
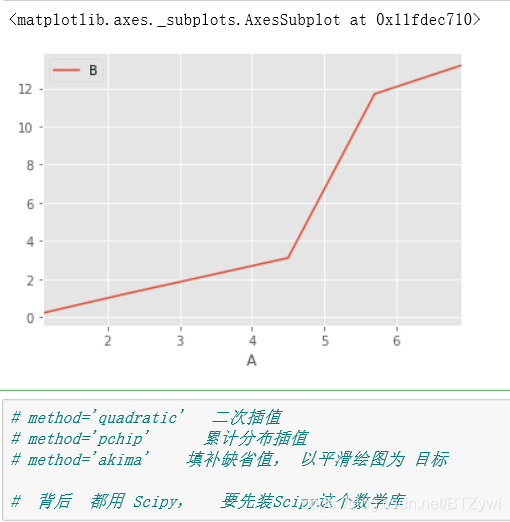
df_interpolate.plot(x='A', y='B')
5、时间序列
1、时间戳 Timestamp to_datatime
import pandas as pd
pd.Timestamp('2019-9-10')
结果:
Timestamp(‘2019-09-10 00:00:00’)
pd.Timestamp('2019-9-10 13:30:59')
结果:Timestamp(‘2019-09-10 13:30:59’)
pd.Timestamp('9/10/2019 13:30:59')
结果:Timestamp(‘2019-09-10 13:30:59’)
2、时间索引 DatetimeIndex
# date_range()
# pd.date_range(start=None, end=None, periods=None, freq='D', tz=None, normalize=False, name=None,\
# closed=None, **kwargs)
# 常用参数的定义
# start: 设置起始时间
# end: 设置截止时间
# periods = 设置时间区间, 若None 则需要设置 单独的起始时间和截止时间
# freq='D' 间隔设置, 默认是D表示天, 可以手动设置为 小时,分钟,秒作为间隔
# tz: 设置时区
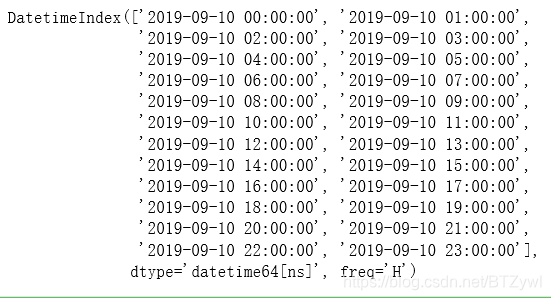
pd.date_range('9/10/2019', periods=24, freq='H')
结果:
# freq='s' 秒
# freq='min' 分钟
# freq='H' 小时
# freq='D' 天
# freq='w' 星期
# freq='m' 月
# 特别的
# freq='BM' 每个月的最后一天
# freq='W' 每周的星期日
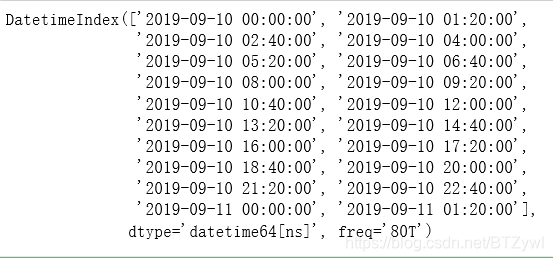
pd.date_range('9/10/2019', periods=20,freq='1H20min')
3、to_datatime时间转换
# 传入参数
# pd.to_datetime(arg, errors='raise', dayfirst=False, yearfirst=False, utc=None, box=True, \
# format=None, exact=True, unit=None, infer_datetime_format=False, orgin='unix')
# arg: 可以接受 整数、浮点数、字符串、时间、列表、元组、一维数组、Series等等
# errors 默认False, 遇到无法解析的数据会报错, coerce:无法解析的数据会设为 NaT, 或者ignore 忽略
# dayfirst 首先解析 日期: 举例 9/10/19 被解析为 2019-9-10
# yearfirst 首先解析 年: 举例 9/10/19 被解析为 2009-10-19
# box= True 表示返回时间索引 DatetimeIndex, False表示返回多维数组ndarray
# format 指定时间解析的格式, 举例: %d /%m /%Y
# 返回值
# 输入的是列表, 默认返回时间索引 DatetimeIndex
# 输入Series, 默认返回 datetime64 的Series
# 输入的是标量, 默认返回Timestamp
输入标量
pd.to_datetime('9/10/2019 11:20', dayfirst=True)
结果:
Timestamp(‘2019-10-09 11:20:00’)
输入列表
pd.to_datetime(['9/10/2019 10:00','9/10/2019 11:00','9/10/2019 12:00'])
结果:

输入Series
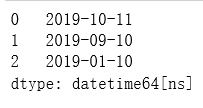
pd.to_datetime(pd.Series(['Oct 11, 2019', '2019-9-10', '10/1/2019']), dayfirst=True)
结果:
输入DateFrame
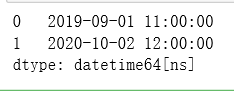
time = pd.to_datetime(pd.DataFrame({'year': [2019, 2020], 'month':[9,10], 'day':[1,2], 'hour':[11,12]}))
type(time)
time
errors
pd.to_datetime(['2019/9/10','abc'],errors='raise') # 抛出错误
pd.to_datetime(['2019/9/10','abc'],errors='ignore') # 忽略错误
pd.to_datetime(['2019/9/10','abc'],errors='coerce') # 错误转为NaT
时间序列的检索
import numpy as np
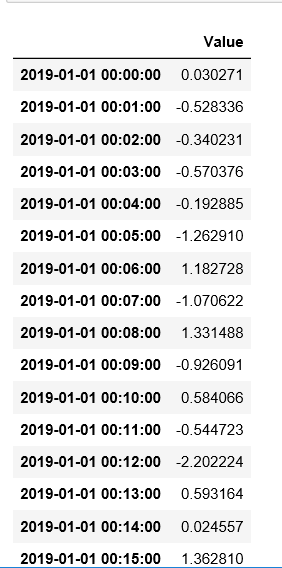
ts = pd.DataFrame(np.random.randn(100000, 1), columns=['Value'], index=pd.date_range('20190101', periods=100000, freq='min'))
ts
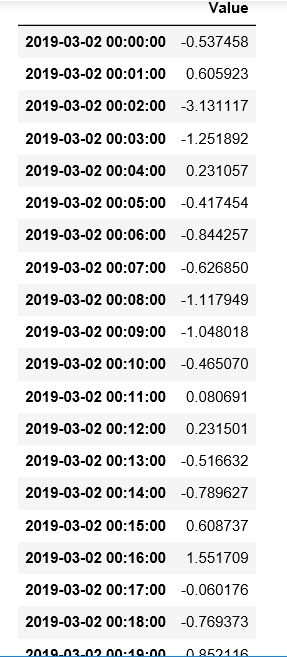
ts['2019-03-02']
ts['2019-3-2 14:00:00': '2019-3-2 18:00:00']
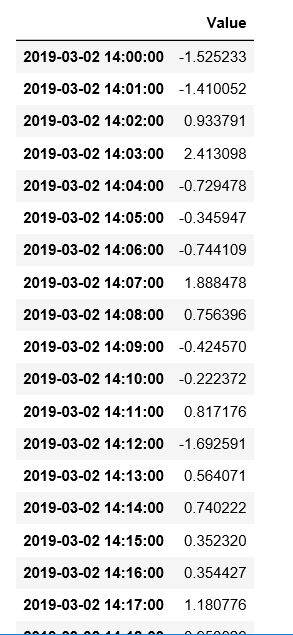
时间序列的计算
from pandas.tseries import offsets
dt = pd.Timestamp('2019-9-10 10:59:00')
dt + offsets.DateOffset(months=1, days=2, hours=1)
结果:Timestamp(‘2019-10-12 11:59:00’)
# 直接减3周
dt - offsets.Week(3)
结果:Timestamp(‘2019-08-20 10:59:00’)
shift 把数据沿着时间轴 往前 或者 往后移动
ts = pd.DataFrame(np.random.randn(7,2), columns=['Value1', 'Value2'], index=pd.date_range('20190910', periods=7, freq='min'))
ts
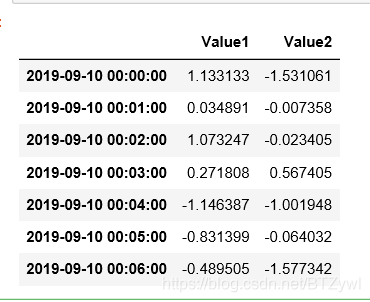
ts.shift(3) # 数据 沿着 时间轴 向后移动 3个位置
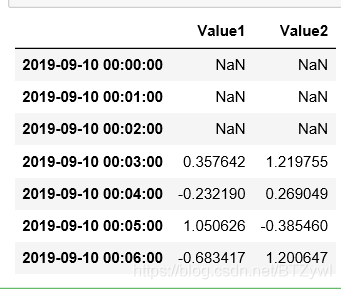
ts.shift(-3) # 数据 沿着 时间轴 向前移动 3个位置
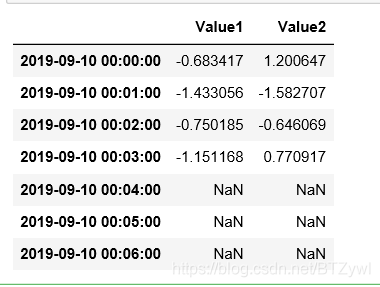
ts.tshift(3) # 时间移动 由于默认的间隔 是min 所以时间往后移动了3min
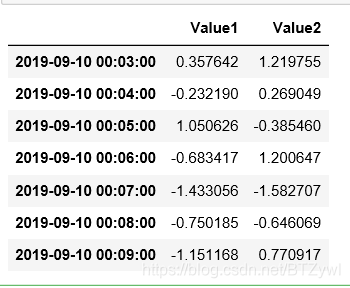
ts.shift(3, freq='D')
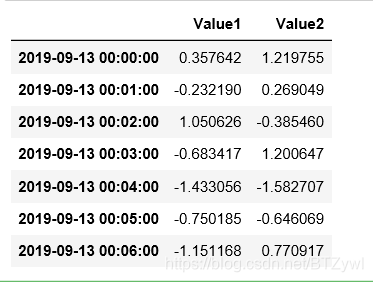
重采样
ts = pd.DataFrame(np.random.randn(50,1), columns=['Value'], index=pd.date_range('2019-09',periods=50,freq='D'))
ts
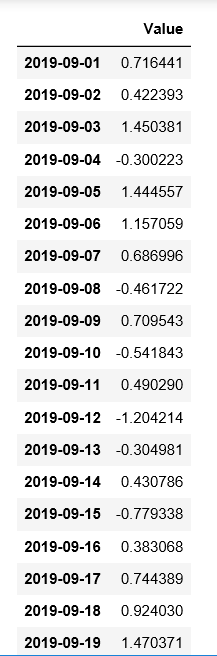
ts.resample('H').ffill()
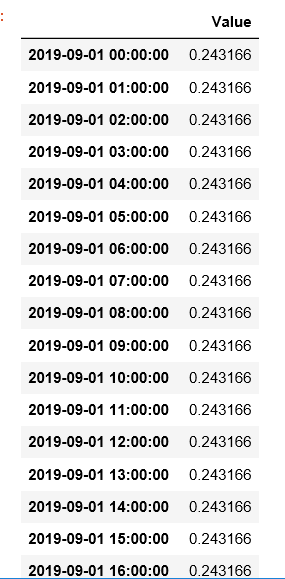
ts.resample('5D').sum() # 间隔从1天变为5天
今天终于把Pandas整理完了,虽然还有一些不理解的地方,但以后总有时间来看的,我觉得。

















 1303
1303

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









