



 本文介绍了如何使用DataX工具进行数据同步,特别是从Clickhouse到HBase(Phoenix)的数据导入。DataX支持多种异构数据源间的离线同步,包括MySQL、Oracle、HDFS等。在进行Clickhouse到HBase(Phoenix)的迁移时,需要注意DataX对Phoenix的版本要求为5.x及HBase 2.x,并且要求Phoenix QueryServer已启动。此外,文章提到了安装DataX的步骤、脚本编写格式以及在迁移过程中应注意的细节,如字段大小写的敏感性。
本文介绍了如何使用DataX工具进行数据同步,特别是从Clickhouse到HBase(Phoenix)的数据导入。DataX支持多种异构数据源间的离线同步,包括MySQL、Oracle、HDFS等。在进行Clickhouse到HBase(Phoenix)的迁移时,需要注意DataX对Phoenix的版本要求为5.x及HBase 2.x,并且要求Phoenix QueryServer已启动。此外,文章提到了安装DataX的步骤、脚本编写格式以及在迁移过程中应注意的细节,如字段大小写的敏感性。
DataX
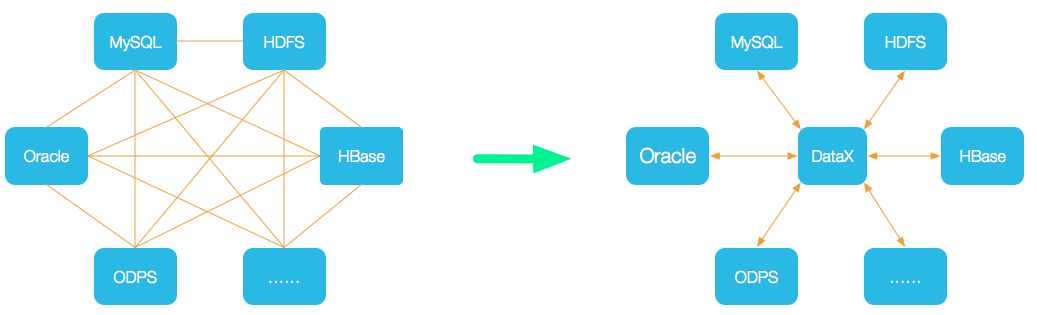
DataX 是一个异构数据源离线同步工具,致力于实现包括关系型数据库(MySQL、Oracle等)、HDFS、Hive、ODPS、HBase、FTP等各种异构数据源之间稳定高效的数据同步功能。
| 类型 | 数据源 | Reader(读) | Writer(写) | 文档 |
|---|---|---|---|---|
| RDBMS 关系型数据库 | MySQL | √ | √ | 读 、写 |
| Oracle | √ | √ | 读 、写 | |
| SQLServer | √ | √ | 读 、写 | |
| PostgreSQL | √ | √ | 读 、写 | |
| DRDS | √ | √ | 读 、写 | |
| 通用RDBMS(支持所有关系型数据库) | √ | √ | 读 、写 | |
| 阿里云数仓数据存储 | ODPS | √ | √ | 读 、写 |
| ADS | √ | 写 | ||
| OSS | √ | √ | 读 、写 | |
| OCS | √ | √ | 读 、写 | |
| NoSQL数据存储 | OTS | √ | √ | 读 、写 |
| Hbase0.94 | √ | √ | 读 、写 | |
| Hbase1.1 | √ | √ | 读 、写 | |
| Phoenix4.x | √ | √ | 读 、写 | |
| Phoenix5.x | √ | √ | 读 、写 | |
| MongoDB | √ | √ | 读 、写 | |
| Hive | √ | √ | 读 、写 | |
| Cassandra | √ | √ | 读 、写 | |
| 无结构化数据存储 | TxtFile | √ | √ | 读 、写 |
| FTP | √ | √ | 读 、写 | |
| HDFS | √ | √ | 读 、写 | |
| Elasticsearch | √ | 写 | ||
| 时间序列数据库 | OpenTSDB | √ | 读 | |
| TSDB | √ | √ | 读 、写 |
除了上述数据库还支持Clickhouse的读取和写出,主要看github支持什么类型
https://github.com/alibaba/DataX
我使用的
也可以看自己安装包下的jar包支持
支持HBase 原生Api的0.X,1.x
支持Phoneix5.0 集成HBase的2.X
1.1 支持的功能
-
支持带索引的表的数据导入,可以同步更新所有的索引表
1.2 限制
-
要求版本为Phoenix5.x及HBase2.x
-
仅支持通过Phoenix QeuryServer导入数据,因此您Phoenix必须启动QueryServer服务才能使用本插件
-
不支持清空已有表数据
-
仅支持通过phoenix创建的表,不支持原生HBase表
-
不支持带时间戳的数据导入
安装DataX
(开箱即用)
直接下载的是远古版本,需要下载源码重新编译
下面是我编译好的安装包
链接:https://pan.baidu.com/s/1IYU93oGOnvcx34HJaPDudQ
提取码:bool下载解压
tar -zxvf /opt/software/ datax2021-08-11.tar.gz -C /opt/module使用过程
我当前使用的是CDH6.3.2所带的之间HBase 版本2.1.0版本,我又额外安装了phoenix
5.0.0
需要开启phoenix的轻客户端
地址在下图
queryserver.py start
启动Phoenix客户端,事先创建好表
phoenix-sqlline hadoop102,hadoop103,hadoop104:2181查看脚本书写格式
python /opt/module/datax/bin/datax.py -r clickhousereader -w hbase20xsqlwriter { "job": { "content": [ { "reader": { "name": "clickhousereader", "parameter": { "column": [], "connection": [ { "jdbcUrl": [], "table": [] } ], "password": "", "username": "", "where": "" } }, "writer": { "name": "hbase20xsqlwriter", "parameter": { "batchSize": "100", "column": [], "nullMode": "skip", "queryServerAddress": "", "schema": "", "serialization": "PROTOBUF", "table": "" } } } ], "setting": { "speed": { "channel": "" } } } }
创建测试表并写脚本
create table t_order_rmt(
id UInt32,
sku_id String,
total_amount Decimal(16,2) ,
create_time Datetime
) engine =ReplacingMergeTree(create_time)
partition by toYYYYMMDD(create_time)
primary key (id)
order by (id, sku_id);
insert into t_order_rmt values
(101,'sku_001',1000.00,'2020-06-01 12:00:00') ,
(102,'sku_002',2000.00,'2020-06-01 11:00:00'),
(102,'sku_004',2500.00,'2020-06-01 12:00:00'),
(102,'sku_002',2000.00,'2020-06-01 13:00:00'),
(102,'sku_002',12000.00,'2020-06-01 13:00:00'),
(102,'sku_002',600.00,'2020-06-02 12:00:00');{
"job": {
"content": [
{
"reader": {
"name": "clickhousereader",
"parameter": {
"column": [
"id",
"sku_id",
"total_amount",
"create_time"
],
"connection": [
{
"jdbcUrl": ["jdbc:clickhouse://192.168.10.71:8123/default?socket_timeout=7200000"],
"table": ["t_order_rmt"]
}
],
"password": "123456",
"username": "default"
}
},
"writer": {
"name": "hbase20xsqlwriter",
"parameter": {
"batchSize": "100",
"column": [
"ID",
"SKU_ID",
"TOTAL_AMOUNT",
"CREATE_TIME"
],
"nullMode": "skip",
"queryServerAddress": "http://192.168.10.75:8765",
"serialization": "PROTOBUF",
"table": "DATAX"
}
}
}
],
"setting": {
"speed": {
"channel": 5 }
}
}
}
}
column
列名
必选
jdbcUrl
连接
必选
table
表名
必选
password:
密码
必选
username
用户名
必选
name
描述:插件名字,必须是hbase11xsqlwriter
必选:是
默认值:无
schema
描述:表所在的schema
必选:否
默认值:无
table
描述:要导入的表名,大小写敏感,通常phoenix表都是大写表名
必选:是
默认值:无
column
描述:列名,大小写敏感,通常phoenix的列名都是大写。
需要注意列的顺序,必须与reader输出的列的顺序一一对应。
不需要填写数据类型,会自动从phoenix获取列的元数据
必选:是
默认值:无
queryServerAddress
描述:Phoenix QueryServer地址,为必填项,格式:http://${hostName}:${ip},如http://172.16.34.58:8765。 增强版/Lindorm 用户若需透传user, password参数,可以在queryServerAddress后增加对应可选属性. 格式参考:http://127.0.0.1:8765;user=root;password=root
必选:是
默认值:无
serialization
描述:QueryServer使用的序列化协议
必选:否
默认值:PROTOBUF
batchSize
描述:批量写入的最大行数
必选:否
默认值:256
nullMode
描述:读取到的列值为null时,如何处理。目前有两种方式:
skip:跳过这一列,即不插入这一列(如果该行的这一列之前已经存在,则会被删除)
empty:插入空值,值类型的空值是0,varchar的空值是空字符串
必选:否
默认值:skip测试脚本
python /opt/module/datax/bin/datax.py /opt/module/datax/job/Hbase.json 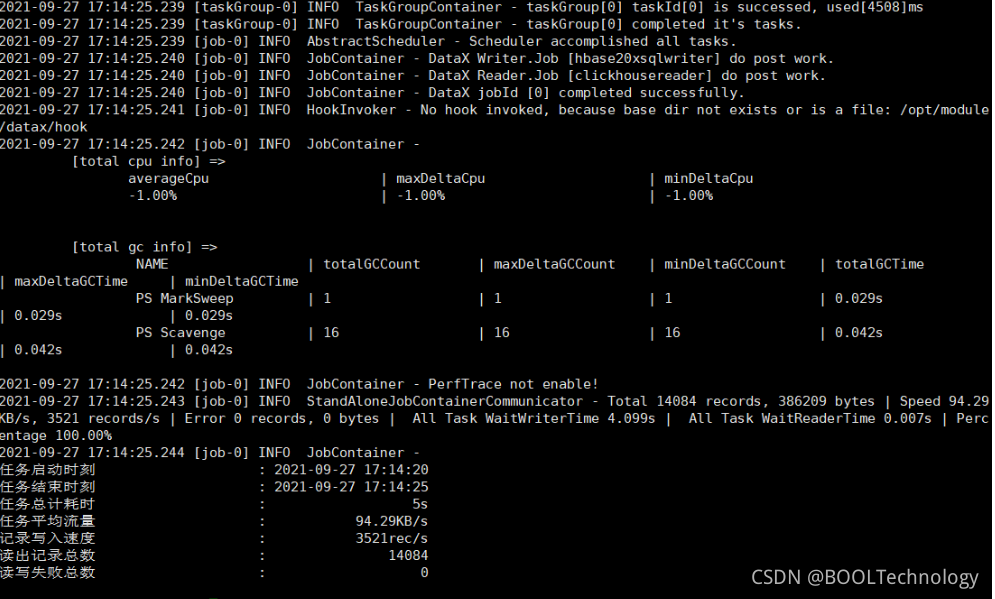

完成 数据没有丢失,完成传输
注意json格式文件的书写
注意clickhoues的用户名和密码需要自己设置
注意Phoenix默认大写 字段和表名都是大写 json文件中对大小写敏感

















 1328
1328

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









