




 本文介绍了数据挖掘的基础知识,包括数据分析和图像识别的实例。重点讲解了Python中pandas库在数据获取、处理和可视化的应用,如使用requests库进行数据爬取,pandas进行数据清洗和分析,并通过pandas实现股票数据的可视化和趋势预估。
本文介绍了数据挖掘的基础知识,包括数据分析和图像识别的实例。重点讲解了Python中pandas库在数据获取、处理和可视化的应用,如使用requests库进行数据爬取,pandas进行数据清洗和分析,并通过pandas实现股票数据的可视化和趋势预估。
一、数据挖掘概述
1.数据分析

二、数据挖掘方式
例:图像识别
1.数据挖掘场景:

2.数据挖掘常用库

三、案例操作
1.需求分析
版本:V1.0
需求:预测模型----预测股票的波动趋势
功能描述:
某网站股票数据爬取
数据指标分析
数据可视化显示
数据趋势预估
2.pandas库

1)数据获取
获取方案:
爬虫:一段自动抓取互联网信息的程序,从互联网上抓取对于我们有价值的信息
requests库是实现数据获取
2)数据处理
对于数据科学家,无论数据分析还是数据挖掘来说,Pandas是一个非常重要的Python包。
Pandas提供了很多方法,使得数据处理非常简单,同时在数据处理速度上也做了很多优化,使得和Python内置方法相比时有了很大的优势。
3)可视化

四、数据分析代码实现
"""
数据分析操作流程:
1- 获取数据
2- 存储数据
3- 洗数据--数据过滤
4- 算法介入
5- 结果展示
6- 分析汇总
"""
# 1- 获取数据:1.本地获取2.网上获取
import csv
import threading
import time
import pandas
import requests
# 创建数据存储文件csv
fo = open("股票数据.csv", mode='w', encoding='utf-8', newline='')
# 1- 写入csv列名
csv_write = csv.DictWriter(fo, fieldnames=["股票名称", "股票代码", "当前价格", "成交量"])
# 写入
csv_write.writeheader()
urlList = [
'https://xueqiu.com/service/v5/stock/screener/quote/list?page={}&size=30&order=desc&orderby=percent&order_by=percent&market=CN&type=sh_sz&_={}'.format(page, round(time.time() * 1000)) for page in range(1, 2)
]
def request_data(url):
# 一定要有请求头--网站有防扒操作
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/88.0.4324.190 Safari/537.36'
}
res = requests.get(url, headers=headers) # 发请求
# print(res.json())
dataList = res.json()['data']['list']
for one in dataList:
# 1- 股票名
# 2- 股票代码
# 3- 当前价位
# 4-成交量
dictTmp = {}
dictTmp['股票名称'] = one['name']
dictTmp['股票代码'] = one['symbol']
dictTmp['当前价格'] = one['current']
dictTmp['成交量'] = one['volume']
print(dictTmp)
# 写进去 数据库 csv Excel
csv_write.writerow(dictTmp)
def request_thread():
threads = []
for url in urlList:
threads.append(threading.Thread(target=request_data, args=(url, )))
# 启动线程
for one in threads:
one.start()
time.sleep(1)
# join
for one in threads:
one.join()
request_data(urlList[0])
start_time = time.time() # 计时开始
request_thread()
fo.close() # 关闭文件
end_time = time.time() # 结束计时
print("耗时>>>", end_time - start_time)
# 4- 数据处理,不同场景需要不同数据--再过滤数据
data_df = pandas.read_csv("股票数据.csv")
df = data_df.dropna() # 删除处理缺失的行
df1 = df[["股票名称", "当前价格"]]
df2 = df1.iloc[:10] # 取前面
# print(type(df1))
# print(df2)
# 5- 算法分析:引入算法--行业内部--经验的操作
# 6- 展示效果
import matplotlib.pyplot as plt
from pylab import mpl
mpl.rcParams['font.sans-serif'] = ['SimHei']
mpl.rcParams['axes.unicode_minus'] = False
# 准备数据
# 绘制图形
plt.bar(df2['股票名称'].values, height=df2['当前价格'].values, label='股票当前价')
for a, b in zip(df2['股票名称'].values, df2['当前价格'].values):
print(a, b)
plt.text(a, b+3, b, horizontalalignment='center', verticalalignment='bottom', fontsize=10, rotation=90)
# 1-
plt.legend() # 设置生效
plt.xticks(rotation=90) # 旋转90
plt.xlabel('股票名称') # 设置x标签值
plt.ylabel('当前价格') # 设置y标签值
plt.show() # 展示
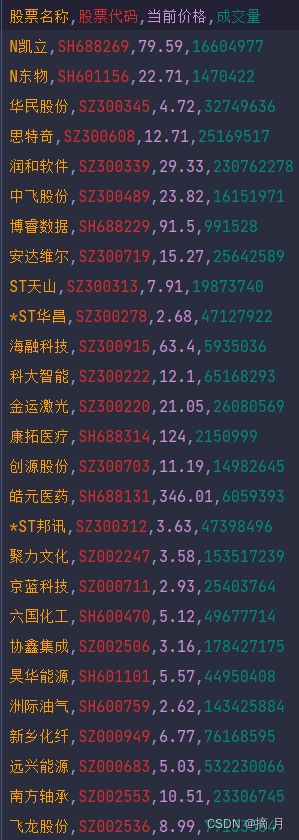
股票数据.csv



















 4631
4631

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











