



背景
前一段时间维护的老项目一直出现MQ消息堆积的问题
其实这个消息量本身我觉得不算是很大,但可能是之前的代码问题,导致消息一直堆积
这个老项目是用于管理设备状态的,一些设备上报的数据会通过中台服务推到MQ中,然后这个项目会监听这部分消息更新设备状态
之前这个项目一直跑的好好的,一共差不多就几百个设备,虽然存在少量的消息堆积,但是设备在每天的一个时间段是不会上报数据的,这个项目在设备不上报数据的这段时间里能把之前堆积的少量消息给处理完,所以等于是达到了一个平衡
后面由于项目需求又加了一批设备,然后MQ消息堆积的问题就被放大了
又因为之前的同事离职了,然后。。。dddd
最初的设计
在我研究了一段时间后(问问同事,看看代码)我发现他们之前用了最土豪的方式
那就是每收到一条数据就在数据库更新一次
这还不是最骚的
当时他们将设备的属性设计成了动态的,也就是说会有一张表来单独保存属性
| id | device | attr | value |
|---|---|---|---|
| 1 | 10001 | brightness | 100 |
| 2 | 10001 | power | 30 |
| 3 | 10002 | brightness | 80 |
| 4 | 10002 | power | 20 |
| ... | ... | ... | ... |
类似上面这样的方式来保存设备的属性
所以设备的一个属性就等于一条记录,而有些设备一次性会保存几十条属性
而且他们还在更新属性的方法上还加了@Transactional
可能当时认为这个项目的体量不会很大,就怎么简单怎么来?
我仿佛能看到这个老项目一边没日没夜的处理数据一边撕扯着嗓子:臣妾做不到啊!

问题分析 & 解决方案
其实这个问题就是服务处理数据的速度跟不上设备上报数据的速度
研究了解的需求和代码之后有了一些优化的思路
当时就罗列了下所有能想到的解决方案再进行对比评估
扩展服务/MQ/硬件资源(老项目能不动就不动)
根据我们之前的了解,其实代码端就有很大的优化空间,况且如果瓶颈是在数据库的话,单纯扩展服务或MQ估计没有什么效果,而且还需要额外的维护和费用
加大设备上报的时间间隔(老项目能不动就不动)
同样的,一个是代码端有很大的优化空间,而且这个方案治标不治本,如果后续设备数量又增加,不能保证不会再次出现这个问题
最重要的是,就几百个设备,我可没有这个脸提这个方案
优化底层更新逻辑(这下不得不修改代码)
如果要在代码层面进行优化,首先这些设备属性可以直接在Redis中更新,然后定时刷到数据库
同时如果属性的值没有变化的话甚至可以直接忽略,这样在更新数据库的时候进一步减少了数据量
但是,这种方式需要花费大量额外的时间来排查可能引发的连锁问题,特别是有很多基于设备属性更新而联动的其他模块的业务功能,而我并不想了解其他的业务模块(白眼)
使用背压策略(这下不得不修改代码)
如果大家接触过RxJava应该会了解对于生产者的生产速度大于消费者的消费速度时,我们可以用特定的背压策略来避免一些问题
由于这个项目接收的数据只是用于更新数据库,没有其他的处理,所以我们只需要关注最新的数据就行了,在这之前的数据直接丢弃也没有太大问题
这样的话只需要在接受数据和处理数据之间加一个背压策略
//只是思路,非真实代码
public class Receiver {
//背压策略
private Backpressure backpressure =
new Backpressure().onEach(this::handle);
//接收数据-背压
public void receiveNew(Object data) {
backpressure.put(data);
}
//接收数据-原有方式
public void receive(Object data) {
handle(data);
}
//处理数据
public void handle(Object data) {
//省略
}
}
复制代码
就像上面的代码,收到数据后放入Backpressure中,Backpressure会将大部分中间状态的数据丢弃,将最新的状态回调到onEach中
如果真的能实现这样的背压策略,就可以少处理很多数据,同时改动很小
(这里其实也可以直接把接收到的数据放到Redis,然后用定时任务拉Redis中的数据更新数据库,相当于是把上一个方案的逻辑移到最外层,但是我在最开始竟然没想到!)
只处理每个设备最新数据的背压策略
为了实现上述背压的功能,我们需要有一个数据筛选模型,也就是我们怎么判断哪些数据要处理哪些数据要丢弃
设计一个缓存队列,当接收到新的数据而队列已经满了的时候,就丢掉最早的数据?
这样确实能达到类似的效果,但是有可能只能处理到一部分设备数据,而另一部分设备数据永远都被丢弃
那么怎么保证每个设备都能处理到呢?
如果能有这样一个队列,当接收到一个新的设备数据时,如果当前队列中已经存在对应设备的数据就更新这个设备数据,否则在最后添加这条设备数据
简单模拟一下流程,如下:
- 设备A上报数据A1,当前队列:A1
- 设备B上报数据B1,当前队列:A1,B1
- 设备A上报数据A2,当前队列:A2,B1
- 进行一次消费,最前面的A2被消费,当前队列:B1
- 设备B上报数据B2,当前队列:B2
- 设备A上报数据A3,当前队列:B2,A3
- 设备B上报数据B3,当前队列:B3,A3
- 进行一次消费,最前面的B3被消费,当前队列:A3
在队列的基础上,存在的就更新,没有的就添加,这不就是Map的特性么?而且LinkedHashMap就支持放入的顺序
如果能让Queue和Map结合在一起,说不定就能实现这样的功能!
而且我们可以利用BlockingQueue的特性,使用对应的阻塞方法,用put入队,用take出队
改造 LinkedBlockingQueue(JDK8)
我们可以组合LinkedBlockingQueue和LinkedHashMap来实现我们需要的功能
改造LinkedBlockingQueue将内部的链表改为LinkedHashMap,这样相同的设备数据会覆盖,同时会按照上报的顺序进行消费,保证每个设备某一时刻的最新数据都会被消费
为什么是改造LinkedBlockingQueue而不是ArrayBlockingQueue,因为LinkedBlockingQueue用的是两把锁,入队和出队各一把锁,性能应该更好一点
将Node链表改为Map
我们先添加我们的Map属性用于替换链表的操作
先来看看LinkedBlockingQueue原本的链表属性
public class LinkedBlockingQueue<E> extends AbstractQueue<E>
implements BlockingQueue<E>, java.io.Serializable {
/**
* Linked list node class
*/
static class Node<E> {
E item;
/**
* One of:
* - the real successor Node
* - this Node, meaning the successor is head.next
* - null, meaning there is no successor (this is the last node)
*/
Node<E> next;
Node(E x) { item = x; }
}
/**
* Head of linked list.
* Invariant: head.item == null
*/
transient Node<E> head;
/**
* Tail of linked list.
* Invariant: last.next == null
*/
private transient Node<E> last;
}
复制代码
现在我们去掉链表的这些内容,同时添加我们的Map属性
改完之后我们的属性大概是这样的,其他的属性都保留
//暂时就叫 LinkedBlockingMapQueue 吧
public class LinkedBlockingMapQueue<K, V> {
/**
* The capacity bound, or Integer.MAX_VALUE if none
*/
private final int capacity;
/**
* Current number of elements
*/
private final AtomicInteger count = new AtomicInteger();
/**
* Lock held by take, poll, etc
*/
private final ReentrantLock takeLock = new ReentrantLock();
/**
* Wait queue for waiting takes
*/
private final Condition notEmpty = takeLock.newCondition();
/**
* Lock held by put, offer, etc
*/
private final ReentrantLock putLock = new ReentrantLock();
/**
* Wait queue for waiting puts
*/
private final Condition notFull = putLock.newCondition();
//我们添加的 Map
private final Map<K, V> map = new LinkedHashMap<>();
}
复制代码
简单的介绍一下
capacity是队列的容量
count是当前元素的数量
takeLock是出队锁
notEmpty用来控制是否可以出队
putLock是入队锁
notFull用来控制是否可以入队
改造 put 方法
我们先来看下原本的put方法
/**
* Inserts the specified element at the tail of this queue, waiting if
* necessary for space to become available.
*
* @throws InterruptedException {@inheritDoc}
* @throws NullPointerException {@inheritDoc}
*/
public void put(E e) throws InterruptedException {
if (e == null) throw new NullPointerException();
// Note: convention in all put/take/etc is to preset local var
// holding count negative to indicate failure unless set.
int c = -1;
Node<E> node = new Node<E>(e);
final ReentrantLock putLock = this.putLock;
final AtomicInteger count = this.count;
putLock.lockInterruptibly();
try {
/*
* Note that count is used in wait guard even though it is
* not protected by lock. This works because count can
* only decrease at this point (all other puts are shut
* out by lock), and we (or some other waiting put) are
* signalled if it ever changes from capacity. Similarly
* for all other uses of count in other wait guards.
*/
while (count.get() == capacity) {
notFull.await();
}
enqueue(node);
c = count.getAndIncrement();
if (c + 1 < capacity)
notFull.signal();
} finally {
putLock.unlock();
}
if (c == 0)
signalNotEmpty();
}
/**
* Links node at end of queue.
*
* @param node the node
*/
private void enqueue(Node<E> node) {
// assert putLock.isHeldByCurrentThread();
// assert last.next == null;
last = last.next = node;
}
复制代码
加上入队锁之后,当前队列不满的状态下,将新的节点放到链表最后,同时count+1,如有必要再唤醒一下其他线程
我们只要把enqueue方法改成往Map中添加即可
public V put(K k, V v) throws InterruptedException {
int c;
V x;
final ReentrantLock putLock = this.putLock;
final AtomicInteger count = this.count;
putLock.lockInterruptibly();
try {
//从这里开始修改
if (map.containsKey(k)) {
x = map.put(k, v);
//如果已经存在则数量不增加
c = count.get();
} else {
//如果已经存在,只需要修改不会增加数量
//只有需要增加count才要等待
while (count.get() == capacity) {
notFull.await();
}
x = map.put(k, v);
//如果不存在则数量+1
c = count.getAndIncrement();
}
//到这里修改结束
if (c + 1 < capacity)
notFull.signal();
} finally {
putLock.unlock();
}
if (c == 0)
signalNotEmpty();
return x;
}
复制代码
这里需要注意的一点是,如果Map中已经存在Key那么count就不用加了
改造 take 方法
take方法也如法炮制
我们先看下原本的take方法
public E take() throws InterruptedException {
E x;
int c = -1;
final AtomicInteger count = this.count;
final ReentrantLock takeLock = this.takeLock;
takeLock.lockInterruptibly();
try {
while (count.get() == 0) {
notEmpty.await();
}
x = dequeue();
c = count.getAndDecrement();
if (c > 1)
notEmpty.signal();
} finally {
takeLock.unlock();
}
if (c == capacity)
signalNotFull();
return x;
}
/**
* Removes a node from head of queue.
*
* @return the node
*/
private E dequeue() {
// assert takeLock.isHeldByCurrentThread();
// assert head.item == null;
Node<E> h = head;
Node<E> first = h.next;
h.next = h; // help GC
head = first;
E x = first.item;
first.item = null;
return x;
}
复制代码
加上出队锁之后,当前队列不空的状态下,将最前面的节点拿出来,同时count-1,如有必要再唤醒一下其他线程
我们只要把dequeue方法改成从Map中移除即可
public Map.Entry<K, V> take() throws InterruptedException {
Map.Entry<K, V> x;
int c;
final AtomicInteger count = this.count;
final ReentrantLock takeLock = this.takeLock;
takeLock.lockInterruptibly();
try {
while (count.get() == 0) {
notEmpty.await();
}
//从这里开始修改
Iterator<Map.Entry<K, V>> iterator = map.entrySet().iterator();
x = iterator.next();
iterator.remove();
//到这里修改结束
c = count.getAndDecrement();
if (c > 1)
notEmpty.signal();
} finally {
takeLock.unlock();
}
if (c == capacity)
signalNotFull();
return x;
}
复制代码
嘿嘿,大功告成!
该吃饭吃饭,该下班下班,该睡觉睡觉,该干嘛干嘛
事情顺利的好像有点不太对劲
在回家了路上我一直在想LinkedBlockingQueue和ArrayBlockingQueue的锁的数量问题
ArrayBlockingQueue用一把锁是不是因为操作的是同一个数组,容易出现冲突或是处理冲突的判定非常复杂
而LinkedBlockingQueue用的是链表,每个节点相对独立,头部节点出队和在尾部添加节点不会相互影响
那么我现在把链表改为Map会有问题么?虽然我们已经控制了不能同时入队或同时出队,但是在入队的同时出队是没有限制的
入队问题
我们再来回顾一下我们的put方法的其中一段
//加锁
if (map.containsKey(k)) {
//如果已经存在对应的 key
x = map.put(k, v);
//如果已经存在则数量不增加
c = count.get();
} else {
//省略
}
//解锁
复制代码
假设我们现在的队列里面有{"A": "A1"}这一个元素
现在我们调用方法put方法添加元素{"A": "A2"}
由于已经存在A对应的元素,所以会进入上面的这个if分支
这个时候,另一个线程调用take方法把{"A": "A1"}取出,count变为0
接着执行map.put(k, v)后,map中的元素数量为1而count还是0
这不就。。。出大问题了吗
我们直接调试一下是不是真的会出现这样的情况
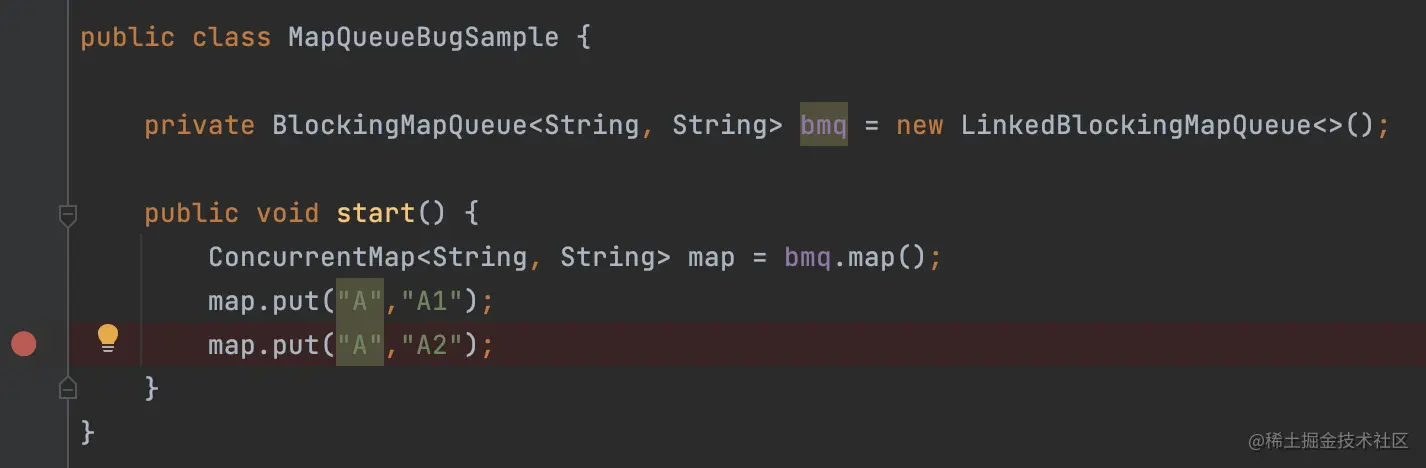
我写了一段测试的代码,先添加一个{"A": "A1"},然后在添加{"A": "A2"}之前打上断点,运行
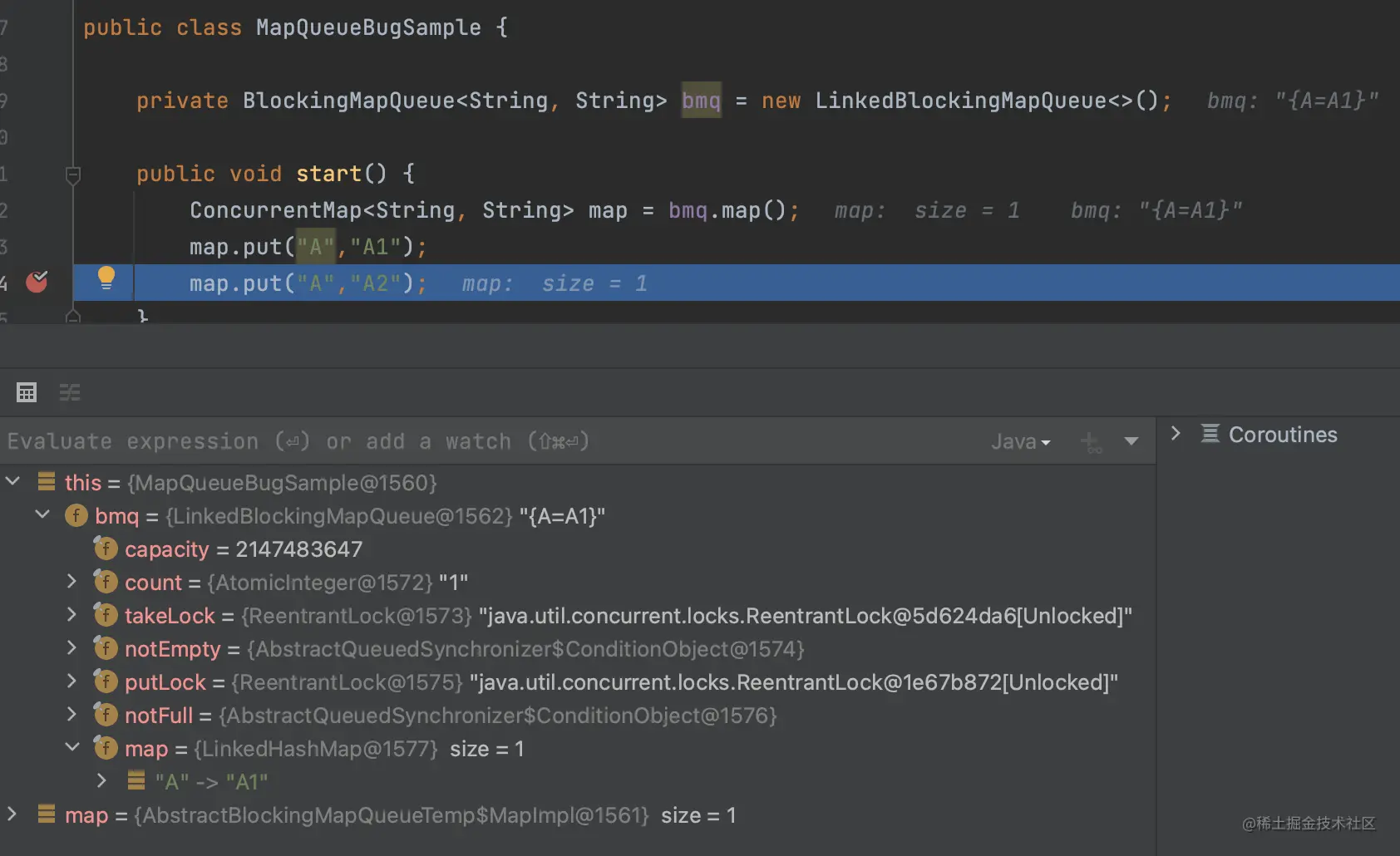
可以看到现在count = 1然后map里面有一个元素{"A": "A1"}
然后一步一步跟进去
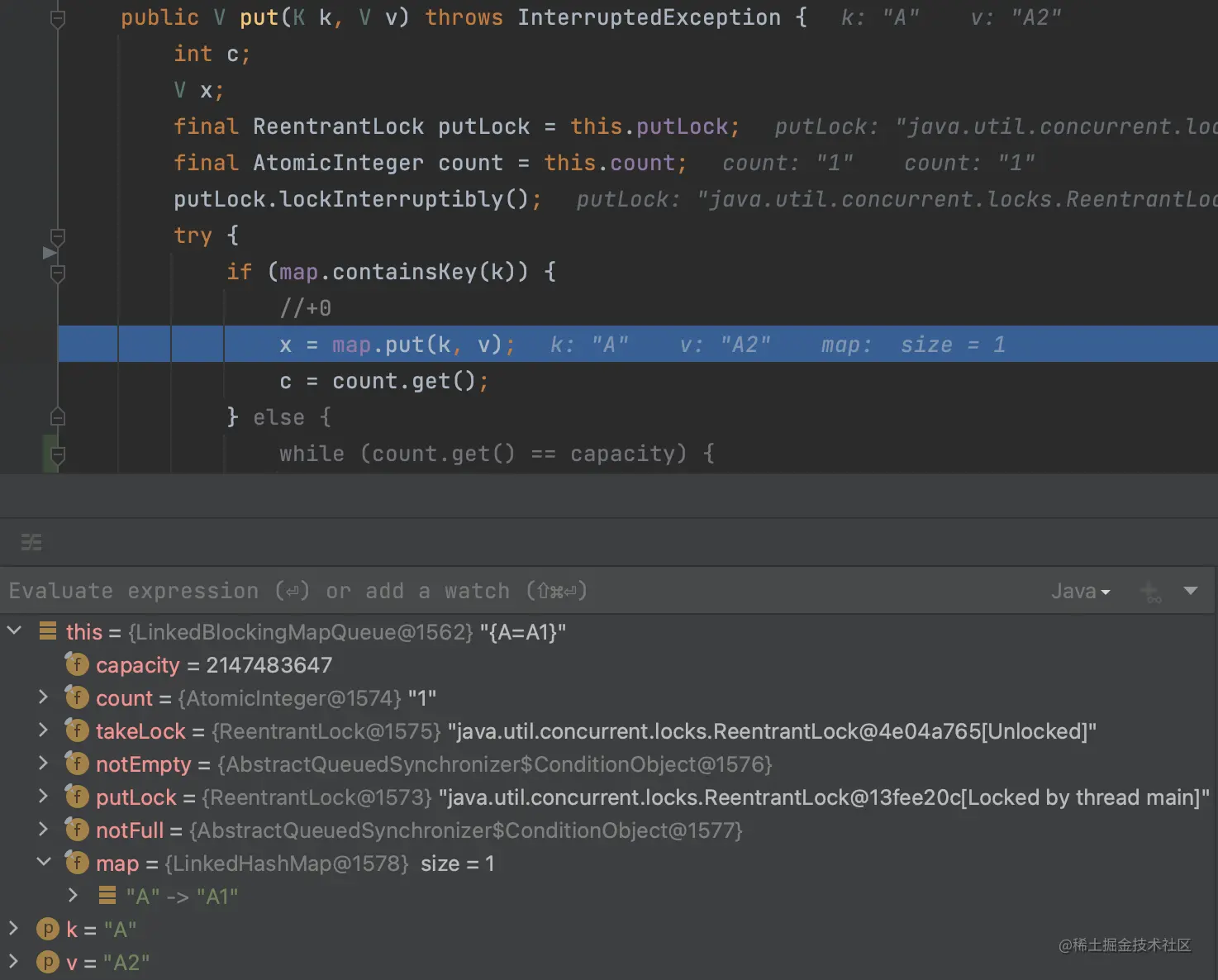
果然进到了if分支里面,这个时候我们调用一下take方法
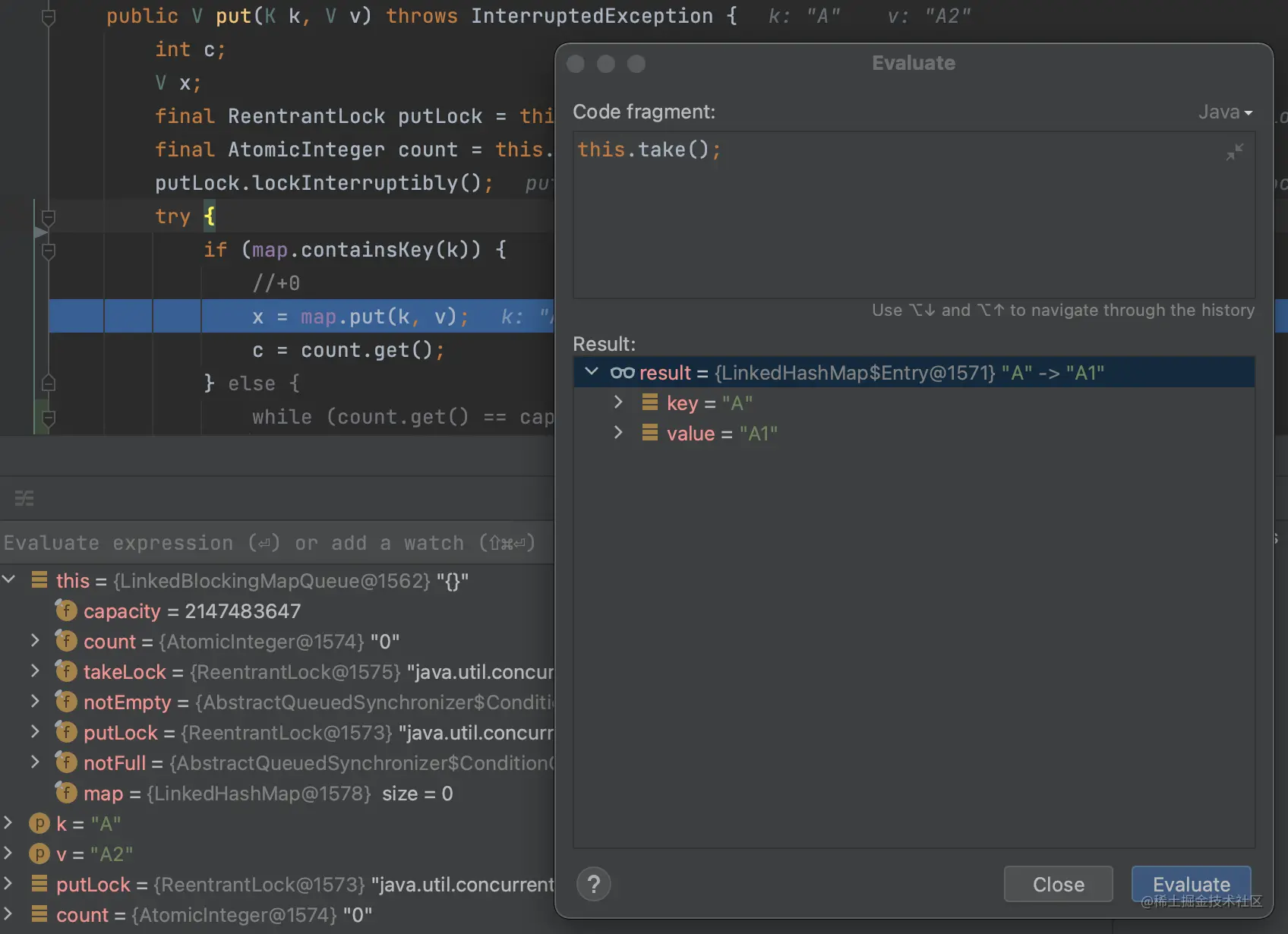
可以看到count = 0同时map为空了
然后接着执行map.put(k, v)方法
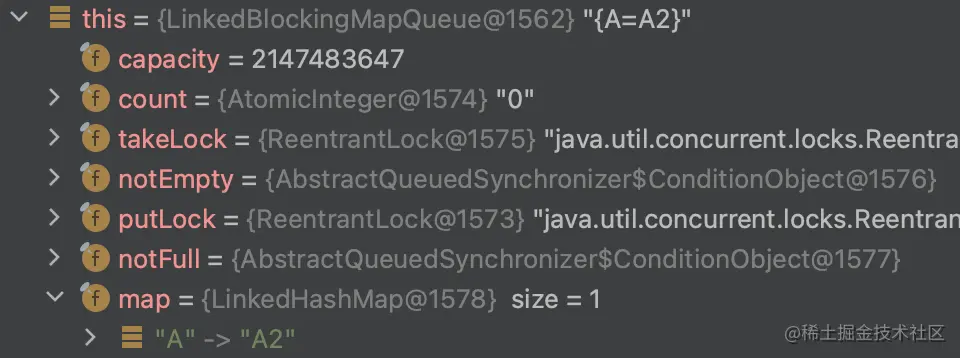
好家伙,map的size = 1而count = 0
由于我们之前判断了A存在,所以不会进行count + 1的操作

解决方案
一种方案是去掉count的维护逻辑,数量直接通过map.size()获取
但是这样就需要Map在一定程度上线程安全,而LinkedHashMap是线程不安全的
难道我们还要改造一下LinkedHashMap,让它在同时读写的时候能够不出问题?

还有另一种方案
那就是把锁改成一把,出队的时候就不能入队,入队的时候就不能出队
果断选择了这种方案
改成一把锁之后,整个逻辑也变得更简单了
public V put(K key, V value) throws InterruptedException {
V x;
lock.lockInterruptibly();
try {
if (map.containsKey(k)) {
//已经存在
//更新节点
//count不变
x = map.put(k, v);
} else {
//不存在
while (count == capacity) {
//满了,等未满的信号
notFull.await();
}
//添加节点
//count+1
x = map.put(k, v);
count++;
}
//发送未空信号
notEmpty.signal();
} finally {
lock.unlock();
}
return x;
}
public Map.Entry<K, V> take() throws InterruptedException {
lock.lockInterruptibly();
try {
while (count == 0) {
notEmpty.await();
}
Iterator<Map.Entry<K, V>> iterator = map.entrySet().iterator();
Map.Entry<K, V> entry = iterator.next();
iterator.remove();
count--;
notFull.signal();
return entry;
} finally {
lock.unlock();
}
}
复制代码
来看看效果,先写一个Demo
@Slf4j
public class MapQueueSample {
private final Map<String, String> map;
private final BlockingQueue<String> queue;
public MapQueueSample() {
BlockingMapQueue<String, String> bmq = new LinkedBlockingMapQueue<>();
bmq.addSynchronizer(new MapQueue.Synchronizer<String, String>() {
@Override
public void afterEnqueue(String key, String value, Map<String, String> readOnly) {
log.info("Put: " + value + ", Current: " + readOnly.toString());
}
@Override
public void afterDequeue(String key, String value, Map<String, String> readOnly) {
log.info("Take: " + value + ", Current: " + readOnly.toString());
}
});
this.map = bmq.map();
this.queue = bmq.queue();
}
public void start() {
startPut("A");
startPut("B");
startPut("C");
startPut("D");
startTake();
}
public void startPut(String s) {
Thread thread = new Thread() {
int i;
@SneakyThrows
@Override
public void run() {
while (true) {
String v = s + i++;
map.put(s, v);
Thread.sleep(500);
}
}
};
thread.setName("Put" + s);
thread.start();
}
@SneakyThrows
public void startTake() {
while (true) {
String s = queue.take();
Thread.sleep(1200);
}
}
}
复制代码
开4个线程放ABCD,然后主线程不断读取
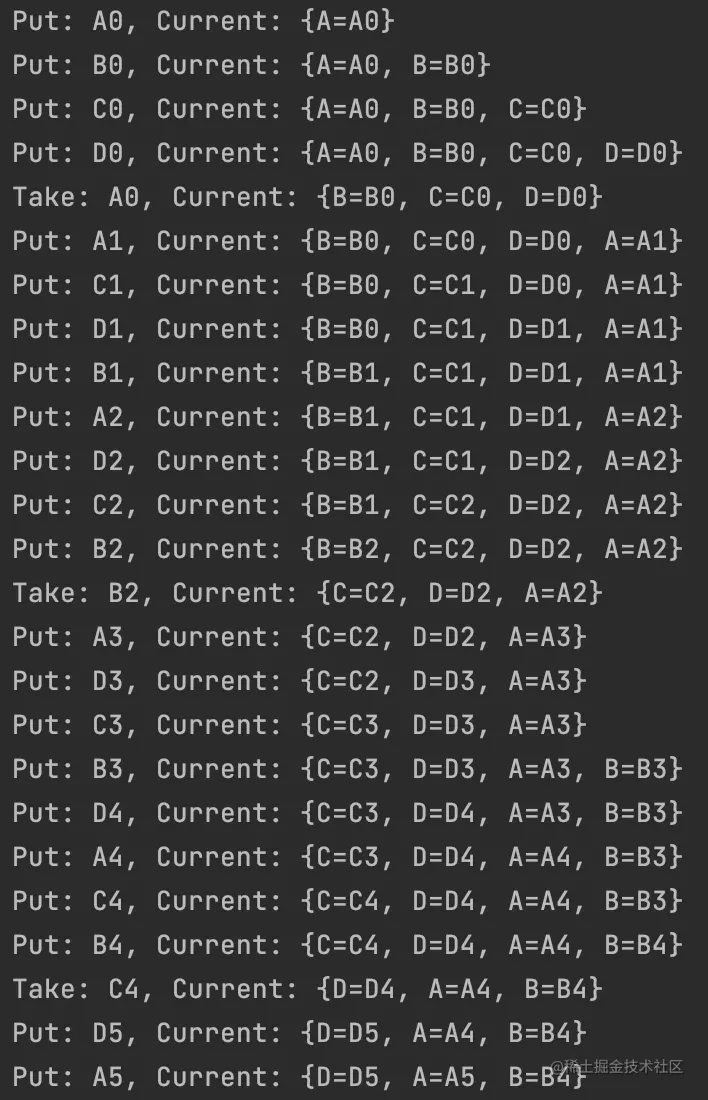
就是我们要的效果!

结束
我觉得我现在已经可以单独写一篇LinkedHashMap的源码分析了
然后我将LinkedBlockingMapQueue发布到了Maven中央仓库上
简单介绍一下集成和使用
implementation 'com.github.linyuzai:concept-mapqueue-core:1.1.0'
复制代码
或
<dependency>
<groupId>com.github.linyuzai</groupId>
<artifactId>concept-mapqueue-core</artifactId>
<version>1.1.0</version>
</dependency>
复制代码
使用方式如下
BlockingMapQueue<String, String> bmq = new LinkedBlockingMapQueue<>();
//通过 Map 操作
Map<String, String> map = bmq.map();
//通过 Queue 操作
BlockingQueue<String> queue = bmq.queue();
复制代码
通过map()和queue()可以获得对应的实例调用对应的方法

















 2285
2285

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









