




有向图
在实际生活中,很多应用相关的图都是有方向性的,最直观的就是网络,可以从A页面通过链接跳转到B页面,那么a和b连接的方向是a -> b,但不能说是b -> a,此时我们就需要使用有向图来解决这一类问题,它和我们之前学习的无向图,最大的区别就在于连接是具有方向的,在代码的处理上也会有很大的不同。
有向图的定义及相关术语
定义:有向图是一幅具有方向性的图,是由一组顶点和一组有方向的边组成的,每条方向的边都连着一对有序的顶点。
出度:由某个顶点指出的边的个数称为该顶点的出度。
入度:指向某个顶点的边的个数称为该顶点的入度。
有向路径:由一系列顶点组成,对于其中的每个顶点都存在一条有向边,从它指向序列中的下一个顶点。
有向环:一条至少含有一条边,且起点和终点相同的有向路径。
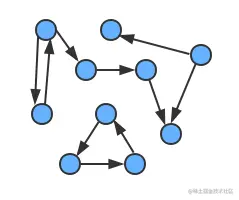
一幅有向图中两个顶点v和w可能存在以下四种关系:
- 没有边相连;
- 存在从v到w的边
v -> w; - 存在从w到v的边
w -> v; - 既存在w到v的边,也存在v到w的边,即双向连接;
理解有向图是一件比较简单的,但如果要通过眼睛看出复杂有向图中的路径就不是那么容易了。
有向图API设计
| 类名 | Digraph |
|---|---|
| 构造方法 | Digraph(int v):创建一个包含V个顶点但不包含边的有向图 |
| 成员方法 | public int v():获取图中顶点的数量public int e():获取图中边的数量public void addEdge(int v, int w):向有向图中添加一条边v->wpublic Queue<Integer> adj(int v):获取由v指出的边所连接的所有顶点private Digraph reverse():该图的反向图 |
| 成员变量 | private final int v: 记录顶点数量private int e:记录边数量private Queue[] adj:邻接表 |
在API中设计了一个反向图,其因为有向图的实现中,用
adj方法获取出来的是由当前顶点v指向的其他顶点,如果能得到其反向图,就可以很容易得到指向v的其他顶点。
代码实现
public class Digraph {
/**
* 记录顶点数量
*/
private final int v;
/**
* 记录边数量
*/
private int e;
/**
* 邻接表
*/
private Queue<Integer>[] adj;
/**
* 创建一个包含V个顶点但不包含边的有向图
*/
public Digraph(int v) {
// 初始化顶点数量
this.v = v;
// 初始化边的数量
this.e = 0;
this.adj = new Queue[v];
// 初始化邻接表中的空队列
for (int i = 0; i < adj.length; i++) {
adj[i] = new Queue<>();
}
}
/**
* 获取图中顶点的数量
*/
public int v() {
return v;
}
/**
* 获取图中边的数量
*/
public int e() {
return e;
}
/**
* 向有向图中添加一条边 v->w
*/
public void addEdge(int v, int w) {
// 由于有向图中边是有向的,v->w 边,只需要让w出现在v的邻接表中,而不需要让v出现在w的邻接表中
adj[v].push(w);
e++;
}
/**
* 获取由v指出的边所连接的所有顶点
*/
public Queue<Integer> adj(int v) {
return adj[v];
}
/**
* 该图的反向图
*/
private Digraph reverse() {
// 创建新的有向图对象
var reverse = new Digraph(v);
// 遍历0~V-1所有顶点,拿到每一个顶点v
for (int i = 0; i < v; i++) {
// 得到原图中的v顶点对应的邻接表,原图中的边为 v->w,则反向图中边为w->v;
for (var w : adj[v]) {
// 重新添加边,方向为原图的反方向
reverse.addEdge(w, v);
}
}
return reverse;
}
}
复制代码拓扑排序
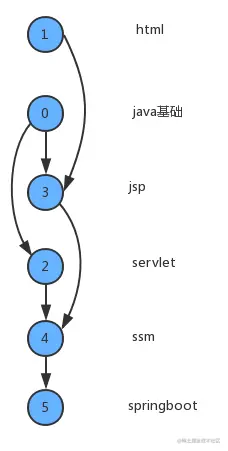
在现实生活中,我们经常会同一时间接到很多任务去完成,但是这些任务的完成是有先后次序的。以我们学习Java学科为例,我们需要学习很多知识,但是这些知识在学习的过程中是需要按照先后次序来完成的。从Java基础,到JSP/Servlet,到SSM,到SpringBoot等是个循序渐进且有依赖的过程。在学习JSP前要首先掌握Java基础和HTML基础,学习SSM框架前要掌握JSP/Servlet之类才行。
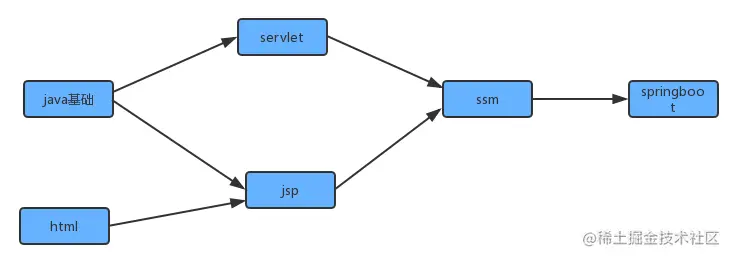
为了简化问题,我们使用整数为顶点编号的标准模型来表示这个案例:
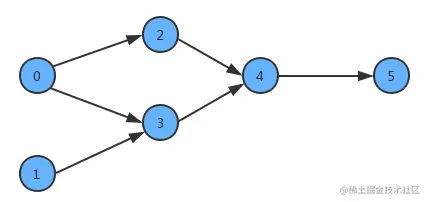
此时如果某个同学要学习这些课程,就需要指定出一个学习的方案,我们只需要对图中的顶点进行排序,让它转换为一个线性序列,就可以解决问题,这时就需要用到一种叫拓扑排序的算法。
拓扑排序:给定一幅有向图,将所有的顶点排序,使得所有的有向边均从排在前面的元素指向排在后面的元素,此时就可以明确的表示出每个顶点的优先级。
下列是一幅拓扑排序后的示意图:
检测有向图中的环
如果学习x课程前必须先学习y课程,学习y课程前必须先学习z课程,学习z课程前必须先学习x课程,那么一定是有问题了,我们就没有办法学习了,因为这三个条件没有办法同时满足。其实这三门课程x、y、z的条件组成了一个环:
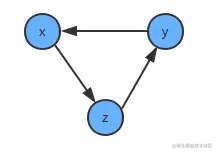
因此,如果我们要使用拓扑排序解决优先级问题,首先得保证图中没有环的存在,如果有环,那就无法进行拓扑排序。
检测有向环的API设计
| 类名 | DirectedCycle |
|---|---|
| 构造方法 | DirectedCycle(Digraph g):创建一个检测环对象,检测图G中是否有环 |
| 成员方法 | private void dfs(Digraph g, int v):基于深度优先搜索,检测图G中是否有环public boolean hasCycle():判断图中是否有环 |
| 成员变量 | private boolean[] marked:索引代表顶点,值表示当前顶点是否已经被搜索private boolean hasCycle:记录图中是否有环private boolean[] onStack:索引代表顶点,使用栈的思想,记录当前顶点有没有已经处于正在搜索的有向路径上 |
检测有向环的代码实现
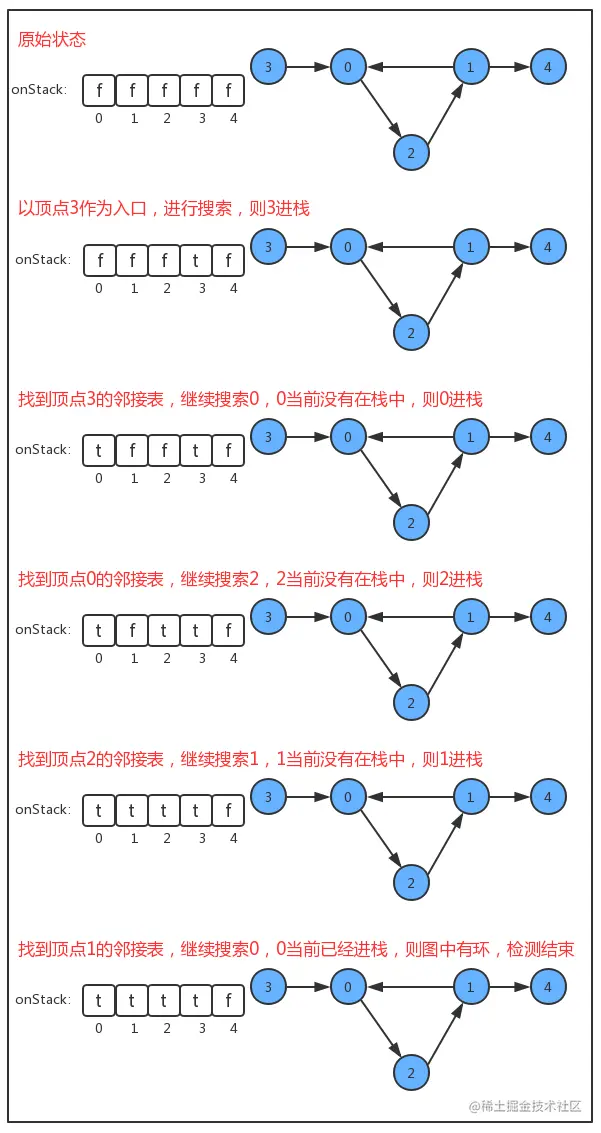
在API中添加了onStack[]布尔数组,索引为图的顶点,当我们深度搜索时:
- 在如果当前顶点正在搜索,则把对应的
onStack数组中的值改为true,标识进栈; - 如果当前顶点搜索完毕,则把对应的
onStack数组中的值改为false,标识出栈; - 如果即将要搜索某个顶点,但该顶点已经在栈中,则图中有环;
public class DirectedCycle {
/**
* 索引代表顶点,值表示当前顶点是否已经被搜索
*/
private boolean[] marked;
/**
* 记录图中是否有环
*/
private boolean hasCycle;
/**
* 索引代表顶点,使用栈的思想,记录当前顶点有没有已经处于正在搜索的有向路径上
*/
private boolean[] onStack;
/**
* 创建一个检测环对象,检测图G中是否有环
*/
public DirectedCycle(Digraph g) {
// 初始化marked数组
this.marked = new boolean[g.v()];
// 初始化hasCycle
this.hasCycle = false;
// 初始化onStack
this.onStack = new boolean[g.v()];
// 找到图中每一个顶点,让每一个顶点作为入口,调用一次dfs进行搜索
for (var v = 0; v < g.v(); v++) {
// 如果当前顶点还没有被搜索过,那么调用dfs搜索
if (!marked[v]) {
dfs(g, v);
}
}
}
/**
* 基于深度优先搜索,检测图G中是否有环
*/
private void dfs(Digraph g, int v) {
// 标识当前顶点已被搜索
marked[v] = true;
// 把当前顶点进栈
onStack[v] = true;
// 进行深度搜索
for (var w : g.adj(v)) {
// 如果当前顶点w没有被搜索过,递归调用dfs搜索
if (!marked[w]) {
dfs(g, w);
}
// 如果当前顶点已经在栈中,表示有环
if (onStack[w]) {
hasCycle = true;
return;
}
}
// 把当前顶点出栈
onStack[v] = false;
}
/**
* 判断图中是否有环
*/
public boolean hasCycle() {
return hasCycle;
}
}
复制代码基于深度优先的顶点排序
如果要把图中的顶点生成线性序列其实是一件非常简单的事,之前我们学习并使用了多次深度优先搜索,我们会发现其实深度优先搜索有一个特点,那就是在一个连通子图上,每个顶点只会被搜索一次,如果我们能在深度优先搜索的基础上,添加一行代码,只需要将搜索的顶点放入到线性序列的数据结构中,我们就能完成这件事。
顶点排序API设计
| 类名 | DepthFirstOrder |
|---|---|
| 构造方法 | DepthFirstOrder(Digraph g):创建一个顶点排序对象,生成顶点线性序列 |
| 成员方法 | private void dfs(Digraph g, int v):基于深度优先搜索,生成顶点线性序列public Stack<Integer> reversePost():获取顶点线性序列 |
| 成员变量 | private boolean[] marked:索引代表顶点,值表示当前顶点是否已经被搜索private Stack<Integer> reversePost:使用栈,存储顶点序列 |
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 977
977

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









