






个人感觉
感觉这是一个对我较大的启发吧。这次mentor就丢了一个任务给我,发现skywalking上数据出现重复,然后丢了一个project给我,叫我去排查。刚开始以为是一个小项目,结果发现这个project巨大,根本找不到,没头没尾的。然后让mentor带我走了一遍,有一说一真的学到了非常非常多。
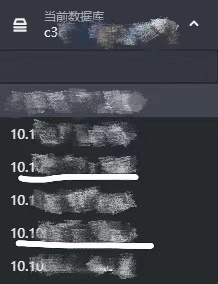
打开网页进入skywalking页面,在database模块查看信息。显示的数据库如下。首先这些数据库以及对应数据取自es database。es节点只有3个,但是显示出来es数据库总共有5个,重复了2个,画白线的是其中重复的一对。
那么现在需要解决的问题是排查出出错原因,并且修改bug。要怎么做呢?
mentor真的给我很大的教导的一句话叫,现在我可以带你做,但是你要学的不单单是这个问题怎么做,而更应该学的是思考我应该怎么去做排查。因为以后你上职场,没人教你这个怎么做,只会有人告诉你哪里出了问题,叫你去做处理。所以这个是你能够成长的必备技能。
回归正题
你是一个后端,在发现这个问题应该怎么做?
这里先把可能性总结一下,虽然我一开始根本想不到,但是有经验了自然而然应该想到
问题1. 前端显示错误
问题2. 取数据代码有问题
问题3. 数据库存储出错
问题4. 写入代码有问题
首先第一点,排查这个问题到底来自前端还是后端。先在网页右键进入到检查。在network下查看问题是否来自服务端。可以clear一下,然后刷新看看数据。
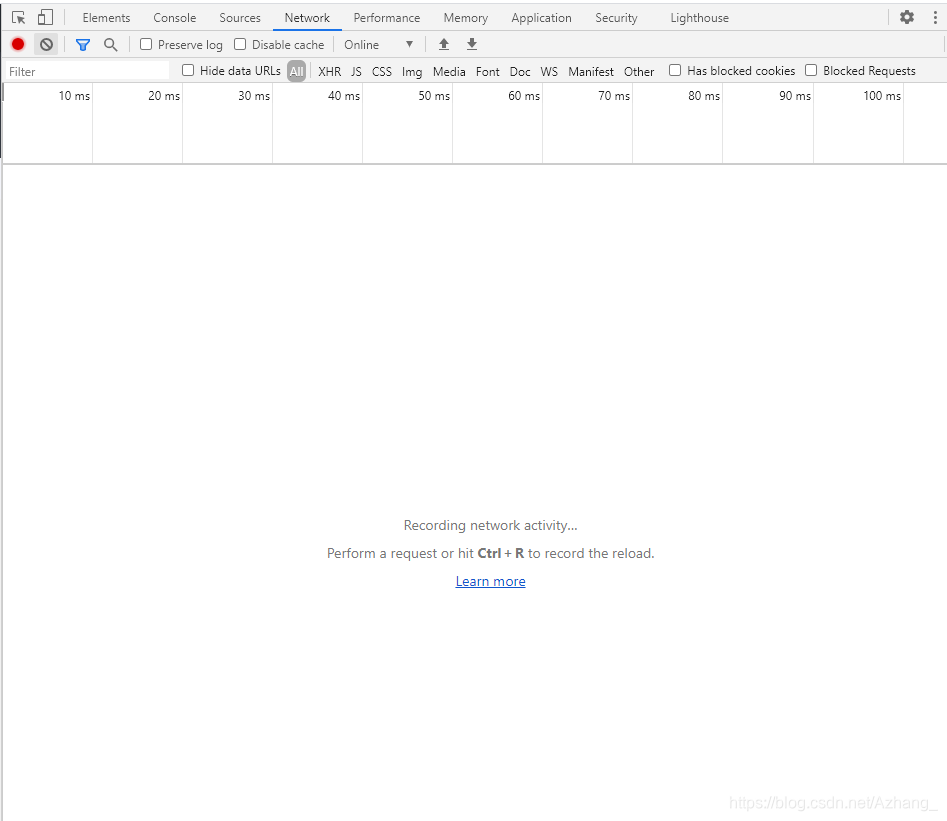
OK,出现了很多数据。一般第一个是最先刷新的,也就是数据库,其他是数据库里面的数据。当然也不肯定,但是不多,自己找找就好。翻开列表,查看services,初见端倪。果然前端接收到的后端数据就是重复的,因此不可能是显示问题,而是后端这边出现了问题。那么接下来就去后端找问题。
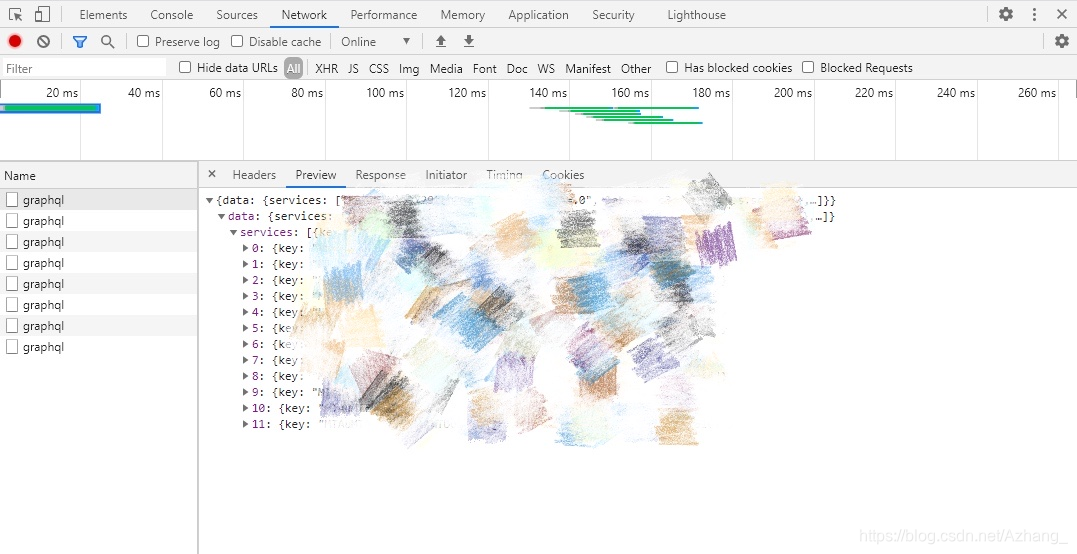
打开项目,对着http接口模块右键Find in File,搜索“graphql”,可以找到对应的方法xxx。然后去该方法的模块(假设为A),右键Find in File,搜索“graphql”,找到对应方法(这是用vue写的)
private fetchData() {
return Axios.post('/graphql', {
query: `
query queryServices($duration: Duration!) {
services: getAllServices(duration: $duration) {
key: id
label: name
}
}`,
variables: {
duration: this.durationTime,
},
}).then((res: AxiosResponse) => {
this.servicesMap = res.data.data.services ? res.data.data.services : [];
});
}
但是顾名思义,虽然看不懂vue,但是大致意思还是可以理解的,而且一看这个方法就知道这是要fetchData。那么在return这行发现做了一个query,调用了queryService,还有getAllServices。对比前端接收到的数据,有key有label,那么我们主要找的方法应该就是getAllServices,因为这里的数据是最后出现在前端的。但是这里也不排除在queryService循环里多了services导致最后出现数据库冗余。好!接下来就去看看这两个方法!这里可以开始全局查看了,因为我们这边的目的是先看看到底是哪里调用了这些方法。
发现queryService好像没啥用,所以接着去看getAllServices里面有一些东西。先找到接口然后去看实现。因为我们这边的实现是跟es有关所以从choose implementation of this method找到它的es模块的接口实现,看到里面的代码
浏览代码。(这里面的思维是先找到esDAO然后再去找细分的方法,跟经验有关,因为设计一般都这么设计)
public List<Service> getAllServices(long startTimestamp, long endTimestamp) throws IOException {
SearchSourceBuilder sourceBuilder = SearchSourceBuilder.searchSource();
BoolQueryBuilder boolQueryBuilder = QueryBuilders.boolQuery();
boolQueryBuilder.must().add(QueryBuilders.termQuery(ServiceTraffic.NODE_TYPE, NodeType.Normal.value()));
sourceBuilder.query(boolQueryBuilder);
sourceBuilder.size(queryMaxSize);
SearchResponse response = getClient().search(ServiceTraffic.INDEX_NAME, sourceBuilder);
return buildServices(response);
}
private List<Service> buildServices(SearchResponse response) {
List<Service> services = new ArrayList<>();
for (SearchHit searchHit : response.getHits()) {
Map<String, Object> sourceAsMap = searchHit.getSourceAsMap();
final ServiceTraffic.Builder builder = new ServiceTraffic.Builder();
final ServiceTraffic serviceTraffic = builder.map2Data(sourceAsMap);
Service service = new Service();
service.setId(serviceTraffic.id());
service.setName(serviceTraffic.getName());
services.add(service);
}
return services;
}
es数据库使用index_name进行搜索,下面这行代码就是搜索获取结果
SearchResponse response = getClient().search(ServiceTraffic.INDEX_NAME, sourceBuilder);
这里调用的INDEX_NAME = “service_traffic”,所以在es的StackManagement搜索的关键词也是这个。
所以下面就是进行循环,添加数据库数据,然后返回,很正常且简单并且看起来没有错误的代码。那么这时候怎么办呢?
这时候就进入到下一个环节了,直接去es数据库看,看是不是重复,如果是重复那么就可以排除es数据库有问题(当然这个大概率不会是数据库有问题,因为有问题就是大问题了,且说明这个数据库不行)。那么在es执行search代码,发现果然重复了,那么就剩下写入代码出问题。我们去写入的代码进行修改即可。
这里加一个更新
==========================================================
我才知道原来skywalking的代码是git开源项目。而我这次找到的错误其实并没有我所想的这么简单
先说一下上面确实没问题,但是写入这边其实挺复杂的。首先在oap-server包下的storage里面找到es7相关代码。(这里提一嘴 ,在浏览代码的过程中进一步了解了skywalking的模型。也就是之前文章提到的L1,L2。然后我需要找的数据属于Metrics,在L1的时候会传给L2,中间会经过消息队列,也就是生产者消费者的模式进行缓存。L1对数据不做处理,所以如果是原始数据会直接存入ES。L2会做聚合,但是对于这里我需要的东西没做什么太多的处理,就简单处理一下做发送。还有skywalking的provider模式等等)
在代码中我发现了一个地方
private void flushDataToStorage(List<Metrics> metricsList, List<PrepareRequest> prepareRequests) {
try {
loadFromStorage(metricsList);
for (Metrics metrics : metricsList) {
Metrics cachedMetrics = context.get(metrics);
if (cachedMetrics != null) {
/*
* If the metrics is not supportUpdate, defined through MetricsExtension#supportUpdate,
* then no merge and further process happens.
*/
if (!supportUpdate) {
continue;
}
/*
* Merge metrics into cachedMetrics, change only happens inside cachedMetrics.
*/
cachedMetrics.combine(metrics);
cachedMetrics.calculate();
prepareRequests.add(metricsDAO.prepareBatchUpdate(model, cachedMetrics));
nextWorker(cachedMetrics);
/*
* The `data` should be not changed in any case. Exporter is an async process.
*/
nextExportWorker.ifPresent(exportEvenWorker -> exportEvenWorker.in(
new ExportEvent(metrics, ExportEvent.EventType.INCREMENT)));
} else {
metrics.calculate();
prepareRequests.add(metricsDAO.prepareBatchInsert(model, metrics));
nextWorker(metrics);
}
}
} catch (Throwable t) {
log.error(t.getMessage(), t);
} finally {
metricsList.clear();
}
}
/**
* Load data from the storage, if {@link #enableDatabaseSession} == true, only load data when the id doesn't exist.
*/
private void loadFromStorage(List<Metrics> metrics) throws IOException {
if (!enableDatabaseSession) {
context.clear();
}
List<String> notInCacheIds = new ArrayList<>();
for (Metrics metric : metrics) {
if (!context.containsKey(metric)) {
notInCacheIds.add(metric.id());
}
}
if (notInCacheIds.size() > 0) {
List<Metrics> metricsList = metricsDAO.multiGet(model, notInCacheIds);
for (Metrics metric : metricsList) {
context.put(metric, metric);
}
}
}
这段代码的意思先会从ES load数据,查看是否已经缓存了数据,如果没有缓存就会加到List里面。然后在flushDataToStorage方法里对于没有缓存的进行添加,然后保存进数据库。
代码各方面看起来没有问题,于是我去Git上开源里搜索相关issue的问题。
我现在使用的是skywalking v8.2.0,得知如果出现查询timeout,那么skywalking的原理是就会对这个节点进行写入,为了保证运行正常。(原话Because timeout still could happen, then duplicate records generated.)在mentor的帮助下我还登上机器看了看error,虽然存在error也无法避免,但是对于运行其实并没有很大的影响。在目前架构的角度无法进行版本更新fix bugs的话,那么就在服务端做一个去重可以起到一定作用,因此我在这个任务中学习到的主要是错误trace和排查还有添加去重功能
在做完去重后上线这边又发现了其他相关的问题
现在出现的问题是:整个架构包括两个项目,一个是skywalking-bin,一个是skywalking源码。skywalking-bin代码主要是部署的脚本代码,对外部不可见,因为包含一些密钥。而skywalking是开源代码,小米自己做的一些修改也是开源的,对外部可见。我做的修改存在于skywalking,但是最后在docker上部署的是skywalking-bin。而在部署中出现了一些问题,就是说发布在docker上已经审批的代码是不允许同版本重写的。而gitlab ci/cd的代码里(.gitlab-ci.yml),他的版本号都是IMAGE=$ CI_REGISTRY_IMAGE_BASE:$ SKYWALKING_VERSION。(这里插一嘴我修改了skywalking,并且把mvn clean package的包放在FDS(对象存储)的地方,然后ci/cd脚本会去FDS取相应gz文件去运行。)但是skywalking-bin的版本号其实没有变更,因为我只修改了skywalking的部分,并且把新生成的gz包放在FDS上,但是对于bin其实完全没有变化,所以无法进行重写,导致无法发布。
有几种方法,1.直接删除docker上的镜像,重新发布。2.修改版本号,提升至8.1.1。3.但是我mentor希望我能找找看有没有方法可以拿到FDS接口,获取特别的印记,比如时间戳/所以如果不手动修改skywalking-bin的配置,就无法进行发布。那么现在我需要发布,因此我要做的新任务就是他希望我最好能想出一个方法,从FDS找到接口获取新文件的时间戳或者SHA/MD5值,修改ci/cd文件,同时也包括DockerFile(因为里面的from对应着ci/cd的版本号),达到可以自动化的效果
刚好对此我打算了解一下docker,打算单开一篇记录了解学习docker概念的文章
好了,果然又遇到问题了,现在的问题就是根据官方文档我想要拿到object的metadata的话我需要构建一个签名,这个签名超级复杂,并且要根据精确到秒的时间构建,不太能在shell中直接完成。但是我可以找到python的sdk,并且可以相对轻松的写出代码。因此我另外假设了几种方法。
1.在镜像的基础上再次构建镜像,使其拥有python env。(当然原来的镜像是没有的)
2.在cicd的过程中安装python env,从而运行这个py脚本
3.在docker container内部再构建一个container跑py脚本(Docker in Docker)
4.想办法构建签名
然而这个cicd中标注的镜像比较复杂,经过几天的尝试和操作发现1,2方法都不太可行,因为这个操作系统比较特殊,很多安装指令都无法调用,且不能直接docker run,需要有额外指定参数,我无法确定(同时吐槽一下docker desktop真的难用),同时对于3来说也无法做到。
于是又回到了方法4. 这里在mentor的提示下(文档存在滞后,可以再次仔细阅读源码并且思考)我再次仔细阅读了网页,我发现在文档中直接get object不需要构建签名,但是get object metadata需要构建签名。这是什么情况,为什么object都不要了,他的metadata就要?
于是重新看代码,发现在请求metadata的过程虽然构建了签名,但是其实没有用到签名,于是我把这一点告诉了导师,果然,他说因为有的时候文档存在滞后性,其实已经可以不需要签名了,直接访问就能取到数据了,终于把困住几天的难题解决了一下
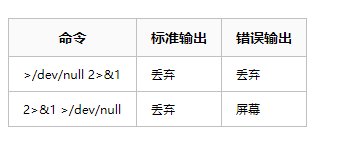
这里我使用了curl -v url请求,但是发现没办法加载,于是搜索了一下发现主要问题是我请求的东西是head request,而这个是在stderr,所以需要重定向它到stdout才能有东西。因此我要使用curl -v url 2>&1
这里稍微解释一下,这里的2代表的是stderr,这里的&代表的是文件描述符。所以这里的意思是 2>&1将标准错误重定向到当前标准输出指向的位置,而2> 1将标准错误重定向到名为1的文件中。
此外再说一下经常见到的>/dev/null。linux在执行shell命令之前,就会确定好所有的输入输出位置,并且从左到右依次执行重定向的命令。那么我们同样从左到右地来分析2>&1 >/dev/null:
2>&1,将错误输出绑定到标准输出上。由于此时的标准输出是默认值,也就是输出到屏幕,所以错误输出会输出到屏幕。但是加了这个>/dev/null,将标准输出1输出位置从屏幕重定向到/dev/null中。/dev/null代表linux的空设备文件,所有往这个文件里面写入的内容都会丢失,俗称“黑洞”。那么执行了>/dev/null之后,标准输出就会不再存在,没有任何地方能够找到输出的内容。 所以最后输出是空。而第二个2>&1 >/dev/null则是2>&1,将错误输出绑定到标准输出上,绑定到屏幕,有点像指针概念,指向堆的object,而不是单单让他等于栈内保存的符号。由于此时的标准输出是默认值,也就是输出到屏幕,所以错误输出会输出到屏幕。```>/dev/null`,将标准输出1指向的位置重定向到/dev/null中。
区别一下这个命令
 https://www.cnblogs.com/ultranms/p/9353157.html
https://www.cnblogs.com/ultranms/p/9353157.html

















 4000
4000

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









