




本期概要
欢迎来到 2024 年的第一期双周精选,感谢每一位社区贡献者在过去一年中的陪伴,今年我们将继续携手探索云原生消息队列的更多可能性!
在过去的两周内,AutoMQ Kafka 最新更新包括 S3Object 新功能、StreamObject compaction 支持、数据压缩存储等,大幅提升了集群性能和存储效率。此外,引入了 7 * 24h Chaos 质量验证框架,确保 Kafka 集群在各种故障情况下的稳定性和自愈能力。
AutoMQ for Kafka 主干动态
集群支持 10w 分区 & 1 PB 存储规模
S3Object 新增DataBlockGroup 支持,DataBlockGroup 在 compact 的过程中可以通过 CopyPart 直接合并成更大的 DataBlockGroup。索引仅随 S3Object 的大小线性增长,1MB 索引块可以支持 28GB S3Object;
StreamObject compaction 支持根据 stream 的 start offset 删除过期数据。StreamObject compaction 合并上限提高到 10GB,无额外的存储放大开销。集群 1 PB 存储的 StreamObject 元数据规模预计不超过 70MB;
S3StreamSetObjectRecord 数据压缩存储,KRaft checkpoint 大小优化减少 50%;
https://github.com/AutoMQ/automq-for-kafka/issues/600
2C16G 支持 5K 分区 & 50MB 写入 & 150MB 消费 & 4.5K QPS
通过为读取链路增加追尾读预检查、last segment 读取快速路径、避免 Lambda 小对象创建、Metrics 内存优化。5K 分区 & 64MB 写入 & 192MB 消费场景下,CPU 从 92% 优化到 82%。
https://github.com/AutoMQ/automq-for-kafka/issues/621
Metrics指标JMX转OpenTelemetry
将 Kafka JMX 指标转换成 OpenTelemetry 上报,统一 Kafka 和 S3Stream 的 Metrics 采集方式,为后续在 Grafana 配置监控和报警提供数据源支持。
https://github.com/AutoMQ/automq-for-kafka/issues/666
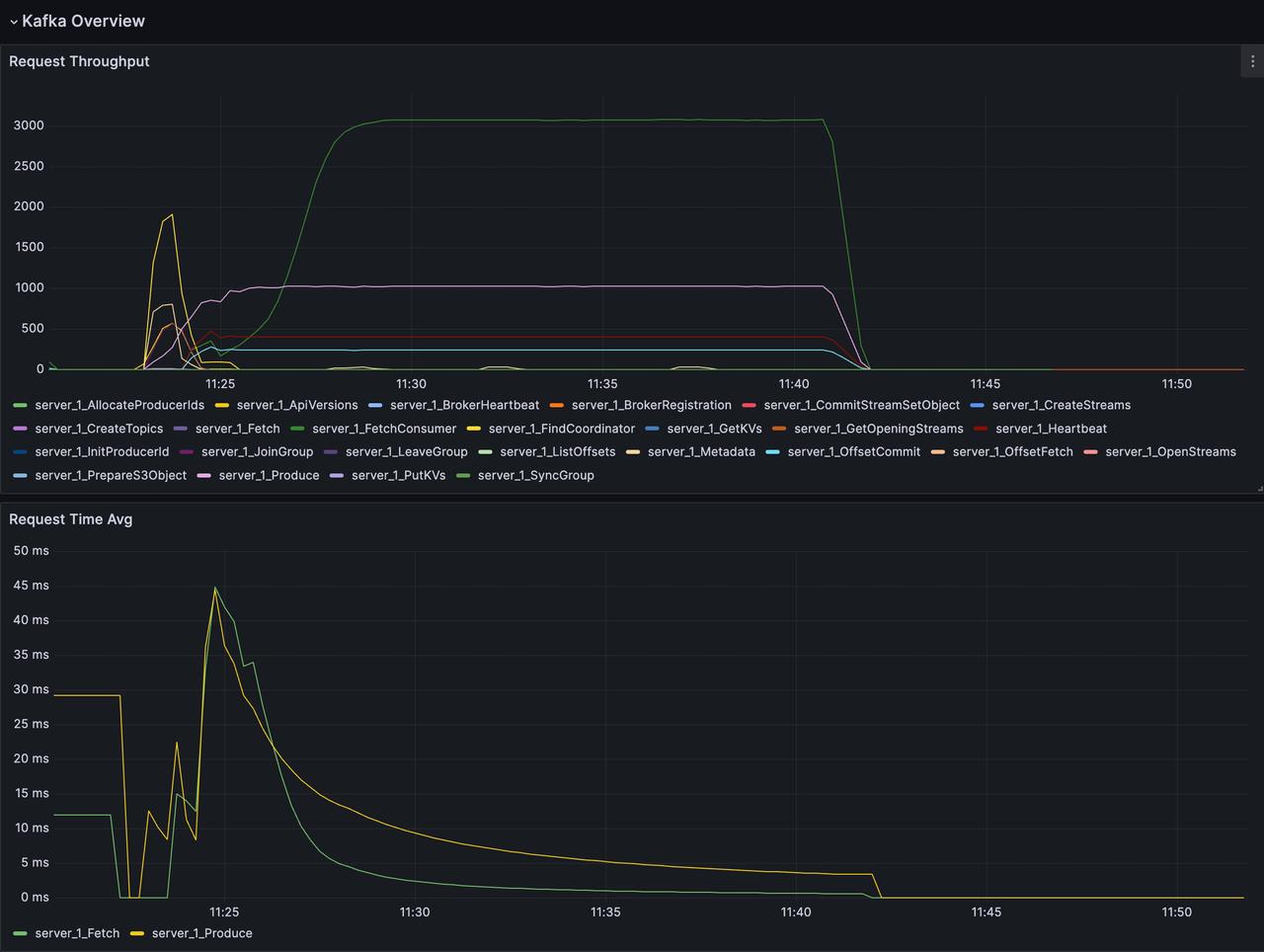
More Things
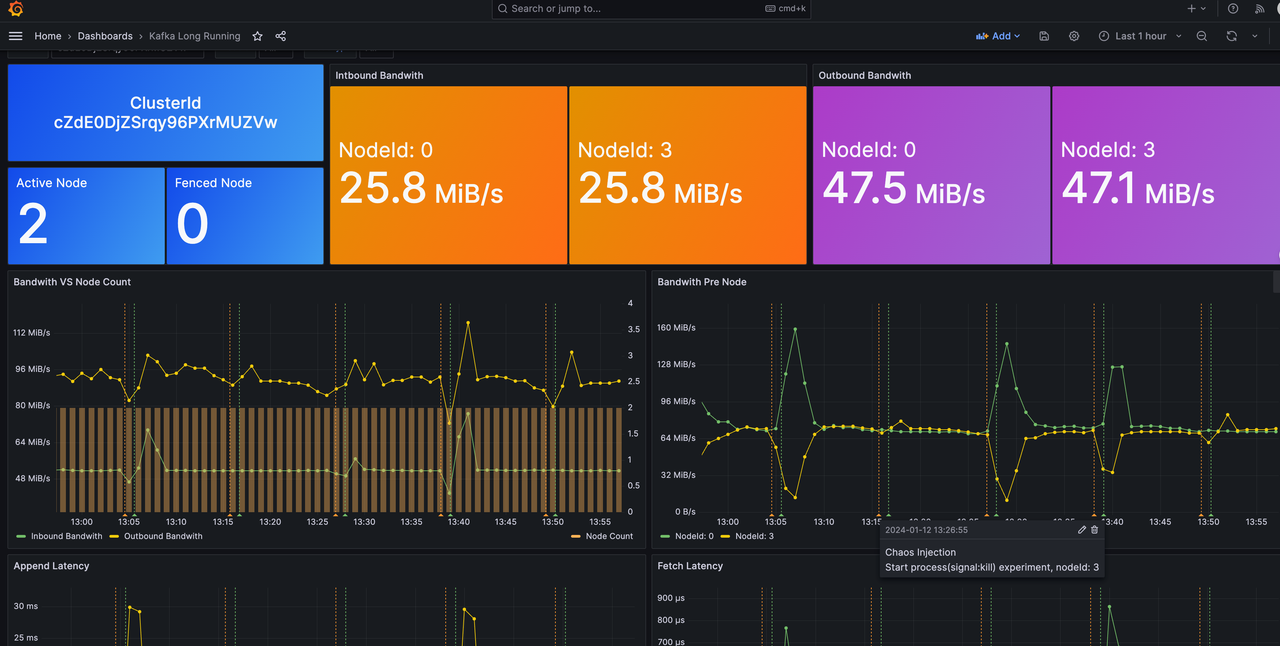
Chaos 质量验证框架
AutoMQ Kafka 新增 7 * 24h Chaos 质量验证框架。Kafka 集群 7 * 24h 全天候运行,框架定期注入网络 10s 延迟、进程 kill -9、进程 pause 等故障,并且校验注入故障后的数据完整性、发送 & 消费 SLA 和故障自愈时间。
以上是第五期《双周精选》的内容,欢迎关注我们的公众号,我们会定期更新 AutoMQ 社区的进展。同时,也诚邀各位开源爱好者持续关注我们社区,跟我们一起构建云原生消息中间件!
END
关于我们
AutoMQ 是一家专业的消息队列和流存储软件服务供应商。AutoMQ 开源的 AutoMQ Kafka 和 AutoMQ RocketMQ 基于云对 Apache Kafka、Apache RocketMQ 消息引擎进行重新设计与实现,在充分利用云上的竞价实例、对象存储等服务的基础上,兑现了云设施的规模化红利,带来了下一代更稳定、高效的消息引擎。此外,AutoMQ 推出的 RocketMQ Copilot 专家系统也重新定义了 RocketMQ 消息运维的新范式,赋能消息运维人员更好的管理消息集群。
🌟 GitHub 地址:https://github.com/AutoMQ/automq-for-kafka
👀 B站:AutoMQ官方账号
🔍 视频号:AutoMQ
👉 扫二维码加入我们的社区群

关注我们,一起学习更多云原生干货

















 807
807

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









