




Kafdrop [1] 是一个为 Kafka 设计的简洁、直观且功能强大的Web UI 工具。它允许开发者和管理员轻松地查看和管理 Kafka 集群的关键元数据,包括主题、分区、消费者组以及他们的偏移量等。通过提供一个用户友好的界面,Kafdrop 大大简化了 Kafka 集群的监控和管理过程,使得用户无需依赖复杂的命令行工具就能快速获取集群的状态信息。得益于 AutoMQ 对 Kafka 的完全兼容,因此可以无缝与 Kafdrop 进行集成。通过利用Kafdrop,AutoMQ 用户也可以享受到直观的用户界面,实时监控Kafka集群状态,包括主题、分区、消费者组及其偏移量等关键元数据。这种监控能力不仅提高了问题诊断的效率,还有助于优化集群性能和资源利用率。这篇教程会教你如何启动 Kafdrop 服务,并将其与 AutoMQ 集群搭配起来使用,实现集群状态的监控和管理。
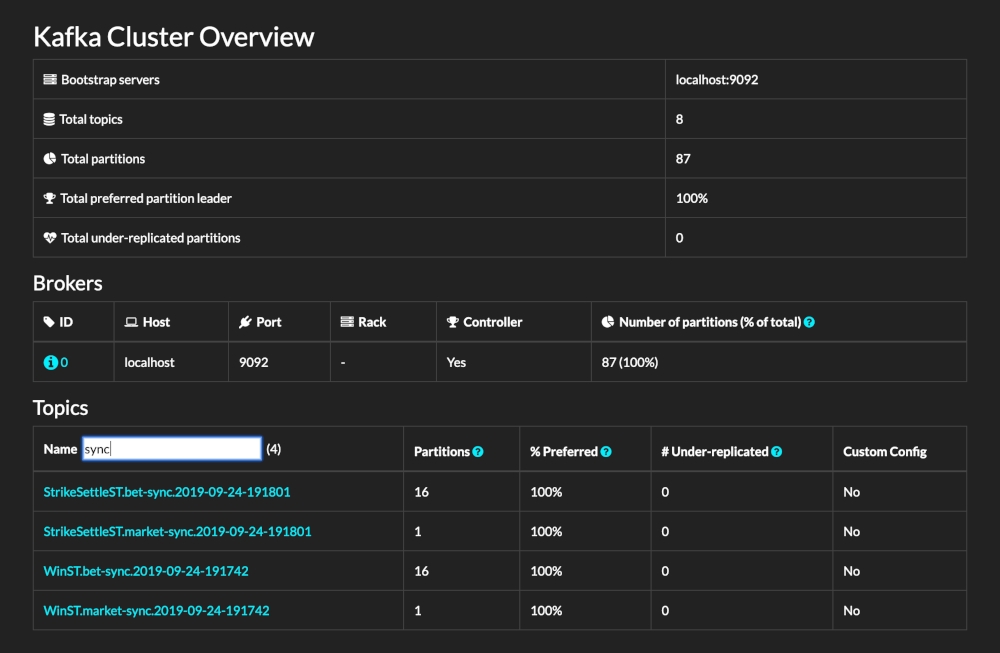
Kafdrop界面
01
前置条件
Kafdrop 的环境:AutoMQ 集群以及 JDK17,Maven 3.6.3 以上。
Kafdrop 可以通过 JAR 包运行,Docker 部署 以及 protobuf 方式部署。可参考 官方文档 [3] 。
准备 5 台主机用于部署 AutoMQ 集群。建议选择 2 核 16GB 内存的 Linux amd64 主机,并准备两个虚拟存储卷。示例如下:
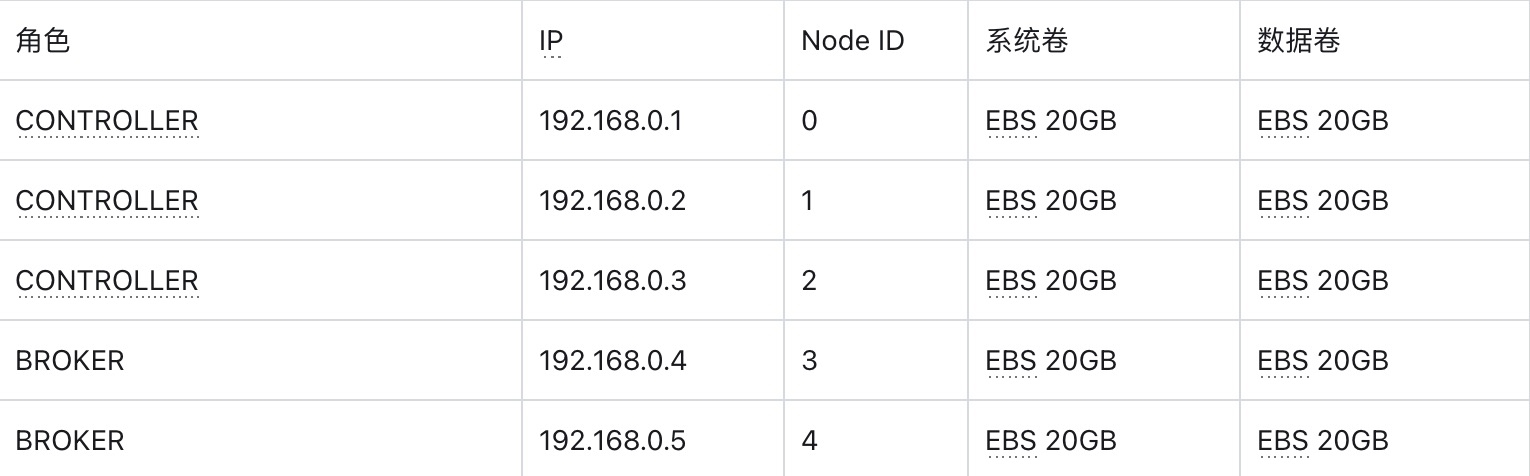
Tips:
请确保这些机器处于相同的网段,可以互相通信
非生产环境也可以只部署 1 台 Controller,默认情况下该 Controller 也同时作为 broker 角色
- 从 AutoMQ Github Releases 下载最新的正式二进制安装包,用于安装 AutoMQ。
下面我将先搭建 AutoMQ 集群,再启动 Kafdrop。
02
安装并启动 AutoMQ 集群
配置S3 URL
第一步:生成 S3 URL
AutoMQ 提供了 automq-kafka-admin.sh 工具,用于快速启动 AutoMQ。只需提供包含所需 S3 接入点和身份认证信息的 S3 URL,即可一键启动 AutoMQ,无需手动生成集群 ID 或进行存储格式化等操作。
### 命令行使用示例
bin/automq-kafka-admin.sh generate-s3-url \
--s3-access-key=xxx \
--s3-secret-key=yyy \
--s3-region=cn-northwest-1 \
--s3-endpoint=s3.cn-northwest-1.amazonaws.com.cn \
--s3-data-bucket=automq-data \
--s3-ops-bucket=automq-ops注意:需要提前配置好 aws 的 s3 bucket ,如果遇到报错,请注意验证参数正确性以及格式。
输出结果
执行该命令后,将自动按以下阶段进行:
根据提供的 accessKey 和 secret Key 对 S3 基本功能进行探测,以验证 AutoMQ 和 S3 的兼容性。
根据身份信息,接入点信息生成 s3url。
根据 s3url 获取启动 AutoMQ 的命令示例。在命令中,将 --controller-list 和 --broker-list 替换为实际需要部署的 CONTROLLER 和 BROKER。
执行结果示例如下:
############ Ping s3 ########################
[ OK ] Write s3 object
[ OK ] Read s3 object
[ OK ] Delete s3 object
[ OK ] Write s3 object
[ OK ] Upload s3 multipar 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









