






DNN原理
本质是回归预测,通过学习大量的样本,即输入和输出之间的特征关系,拟合输入和输出之间的方程,学习结束后,只给输入特征,它便可以给出输出特征。
划分数据集
数据集的每个样本中都要包含输入和输出,将其按一定比例划分为训练集和测试集。
训练网络
通过前向传播和反向传播的不断轮回,不断调整内部参数(权重和偏置
),从而拟合复杂函数。训练网络前要设定好超参数(外部参数):网络层数,每个隐藏层的节点数,激活函数类型,学习率,迭代次数等。
测试网络
为了防止训练的过拟合,需要拿出少量的样本进行测试。过拟合:网络优化好的参数只对训练样本有效,换成其他的就gg。当网络训练好后,拿出测试集的输入进行预测,并将结果和真实值对比,查看准确率。
使用网络
预测输出(1次前向传播不需要反向传播)
DNN demo(使用Tensorflow的Keras进行图像分类)
使用 Fashion MNIST 数据集训练分类
# This code is used to study the deep neural network using TensorFlow.
import tensorflow as tf
import matplotlib.pyplot as plt
import pandas as pd
import numpy as np
from tensorflow import keras
# 加载数据集fasion_mnist
fashion_mnist = keras.datasets.fashion_mnist
# 划分训练集和测试集
(x_train, y_train), (x_test, y_test) = fashion_mnist.load_data()
# 打印训练集的形状和数据类型
print("x_train shape:", x_train.shape, "y_train shape:", y_train.dtype)
# x_train shape: (60000, 28, 28) y_train shape: uint8
# 创建验证集并标准化数据(将像素度从0-255转换为0-1)
x_val = x_train[:5000] / 255.0
y_val = y_train[:5000]
x_train = x_train[5000:] / 255.0
y_train = y_train[5000:]
# 将图像的类别列出
class_names = ["T-shirt/top", "Trouser", "Pullover", "Dress", "Coat",
"Sandal", "Shirt", "Sneaker", "Bag", "Ankle boot"]
# 训练集中第一张图片代表的类别
print("y_train[0]:", y_train[0], "class_names[y_train[0]]:", class_names[y_train[0]])
# y_train[0]: 4 class_names[y_train[0]]: Coat
# 构建模型(使用顺序API)
model = keras.models.Sequential()
model.add(keras.layers.Flatten(input_shape=(28, 28))) # 将每个图像转换成一个 1D 数组并设置实例的形状
model.add(keras.layers.Dense(300, activation="relu")) # 添加一个全连接层,输出维度为 300,激活函数为 relu
model.add(keras.layers.Dense(100, activation="relu")) # 添加一个全连接层,输出维度为 100,激活函数为 relu
model.add(keras.layers.Dense(10, activation="softmax")) # 添加一个全连接层为输出层,输出维度为 10,激活函数为 softmax,代表每个类别的概率
# 另一种构建模型方式
'''model = keras.Sequential([
keras.layers.Flatten(input_shape=(28, 28)),
keras.layers.Dense(300, activation="relu"),
keras.layers.Dense(100, activation="relu"),
keras.layers.Dense(10, activation="softmax")
])'''
# 显示所有模型层
model.summary()
'''Model: "sequential"
┌─────────────────────────────────┬────────────────────────┬───────────────┐
│ Layer (type) │ Output Shape │ Param # │
├─────────────────────────────────┼────────────────────────┼───────────────┤
│ flatten (Flatten) │ (None, 784) │ 0 │
├─────────────────────────────────┼────────────────────────┼───────────────┤
│ dense (Dense) │ (None, 300) │ 235,500 │
├─────────────────────────────────┼────────────────────────┼───────────────┤
│ dense_1 (Dense) │ (None, 100) │ 30,100 │
├─────────────────────────────────┼────────────────────────┼───────────────┤
│ dense_2 (Dense) │ (None, 10) │ 1,010 │
└─────────────────────────────────┴────────────────────────┴───────────────┘
Total params: 266,610 (1.02 MB)
Trainable params: 266,610 (1.02 MB)
Non-trainable params: 0 (0.00 B)'''
# 获取模型层列表
model.layers
model.layers[1].name
model.get_layer("dense_1").name
# 显示权重和偏置
weights, biases = model.layers[1].get_weights()
print("weights:", weights, "biases:", biases)
'''weights: [[ 0.06876886 -0.0420241 0.0591705 ... -0.0641143 -0.02235207
0.01202451]
[-0.03905698 0.07116422 0.03832097 ... -0.03119954 -0.0219731
-0.06934246]
[ 0.04216435 -0.06895475 0.06414525 ... 0.06540705 -0.05913302
0.06304884]
...
[ 0.04061784 0.00025344 0.0344504 ... -0.06683451 -0.0074664
-0.00974406]
[ 0.04985763 0.0334013 0.00678349 ... 0.02374641 -0.06026943
-0.05258489]
[ 0.05035675 -0.00691888 -0.07288457 ... 0.02569064 0.01420186
-0.00680738]] biases: [0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.
0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.
0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.
0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.
0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.
0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.
0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.
0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.
0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.
0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.
0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.
0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.
0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.]'''
print("weights.shape:", weights.shape, "biases.shape:", biases.shape)
# weights.shape: (784, 300) biases.shape: (300,)
# 编译模型
model.compile(optimizer="sgd", loss="sparse_categorical_crossentropy", metrics=["accuracy"])
# 训练模型
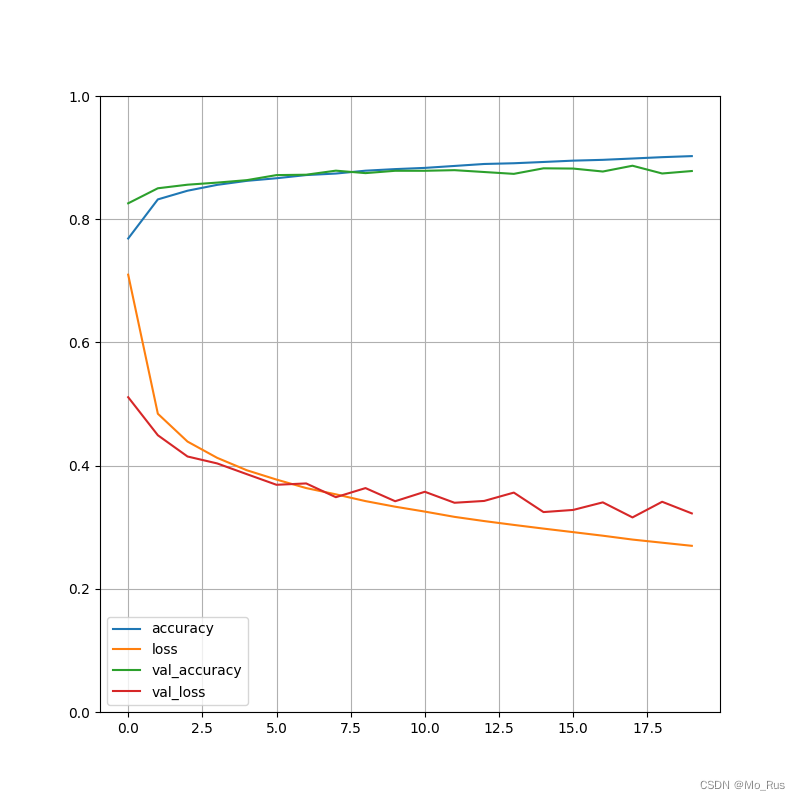
history = model.fit(x_train, y_train, epochs=20, validation_data=(x_val, y_val))
# 评估模型
model.evaluate(x_test, y_test)
# 绘制训练过程
pd.DataFrame(history.history).plot(figsize=(8, 8))
plt.grid(True)
plt.gca().set_ylim(0, 1)
plt.show()
# 预测模型
X_new = x_test[:3]
y_proba = model.predict(X_new)
y_pred = model.predict_classes(X_new)
print("y_pred:", y_pred)
print("y_proba:", y_proba)
# y_pred: [9 1 0]
''' y_proba: [[9.999994e-01 1.110223e-16 1.110223e-16 1.110223e-16 1.110223e-16
1.110223e-16 1.110223e-16 1.110223e-16 1.110223e-16 1.110223e-16]
[9.999994e-01 1.110223e-16 1.110223e-16 1.110223e-16 1.110223e-16
1.110223e-16 1.110223e-16 1.110223e-16 1.110223e-16 1.110223e-16]
[9.999994e-01 1.110223e-16 1.110223e-16 1.110223e-16 1.110223e-16
1.110223e-16 1.110223e-16 1.110223e-16 1.110223e-16 1.110223e-16]]'''
np.array(class_names)[y_pred]
# ['Ankle boot' 'Pullover' 'T-shirt/top']
Learning Curves


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









