




1.样本距离判断
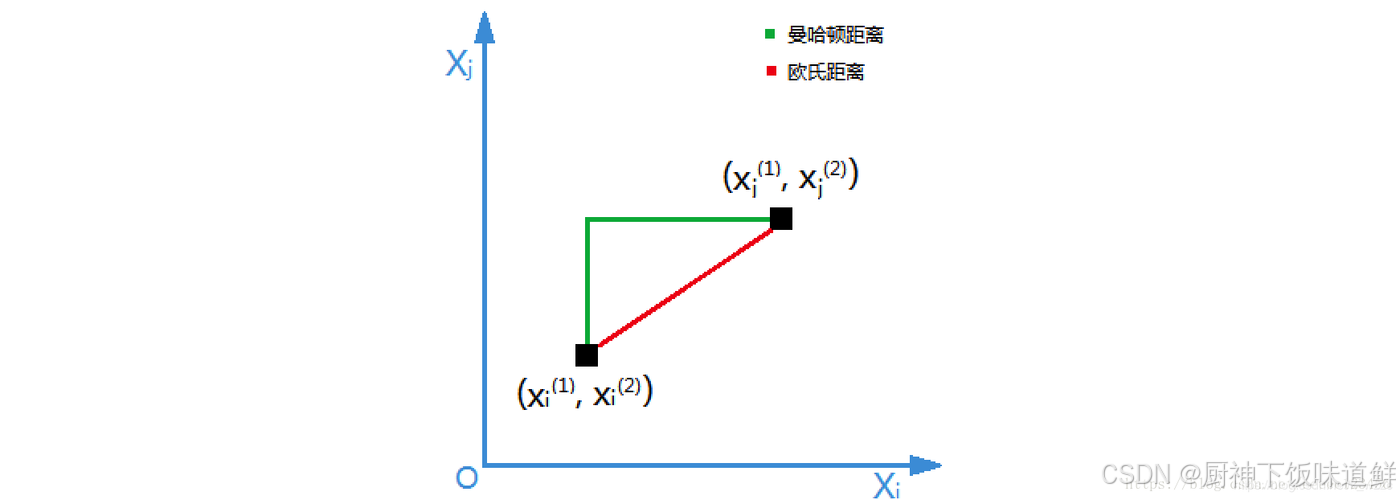
2.KNN 算法原理
K-近邻算法(K-Nearest Neighbors,简称KNN),根据K个邻居样本的类别来判断当前样本的类别。
如果一个样本在特征空间中的k个最相似(最邻近)样本中的大多数属于某个类别,则该类本也属于这个类别。
3.KNN缺点
- 对于大规模数据集,计算量大,因为需要计算测试样本与所有训练样本的距离。
- 对于高维数据,距离度量可能变得不那么有意义,这就是所谓的“维度灾难”
- 需要选择合适的k值和距离度量,这可能需要一些实验和调整
4.API
class sklearn.neighbors.KNeighborsClassifier(n_neighbors=5, algorithm='auto')参数:
| 参数 | 功能 | 值 |
|---|---|---|
| n_neighbors | 默认情况下用于kneighbors查询的近邻数,就是K | int, default=5 |
| algorithm | 找到近邻的方式,注意不是计算距离的方式 | {‘auto’, ‘ball_tree’, ‘kd_tree’, ‘brute’}, default=’auto’ |
方法:
| 参数 | 功能 |
|---|---|
| fit(x,y) | 使用x作为训练数据和y作为目标数据 |
| predict(x) | 预测提供的数据x,得到预测数据 |
5.sklearn 实现KNN示例
用KNN算法对鸢尾花进行分类
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.neighbors import KNeighborsClassifier
#载入数据
iris = load_iris()
#划分数据集
x_train,x_test,y_train,y_test = train_test_split(iris.data,iris.target, random_state=0)
#标准化
transfer = StandardScaler()
x_train = transfer.fit_transform(x_train)
x_test = transfer.transform(x_test)
# KNN算法预估器
estimator = KNeighborsClassifier(n_neighbors=7)
estimator.fit(x_train,y_train)
#模型评估
score = estimator.score(x_test,y_test)
print(f"{round(score*100,2)}%")6.模型保存与加载
import joblib
# 保存模型
joblib.dump(estimator, "knn.pkl")
# 加载模型
estimator = joblib.load("knn.pkl")
#使用模型预测
y_test=estimator.predict([[0.4,0.2,0.4,0.7]])
print(y_test)
















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









