




前言
经常使用MySQL数据库的小伙伴都知道,当单表数据量达到一定的规模以后,查询性能就会显著降低。因此,当单表数据量过大时,我们往往要考虑进行分库分表。那么如何计算单表存储多大的数据量合适?当单表数据达到多大的规模时,我们才要进行分库分表呢?
MySQL存储方式
首先我们要先了解一下MySQL存储数据的方式,以下都是针对InnoDB引擎来讲解的。
数据页
为了提高数据查询效率,MySQL采用了数据页的方式进行数据存储,一个数据页的大小是16KB,可以通过以下语句查询。
mysql> SHOW GLOBAL STATUS LIKE 'innodb_page_size';
+------------------+-------+
| Variable_name | Value |
+------------------+-------+
| Innodb_page_size | 16384 |
+------------------+-------+
1 row in set (0.00 sec)
根据结构示意图,我们可以看到,在这16KB的数据里,除了包括我们要记录的数据,还包含页头和页尾的开销(大约200字节)。因此,一个数据页中的有效数据空间大概为16184字节。
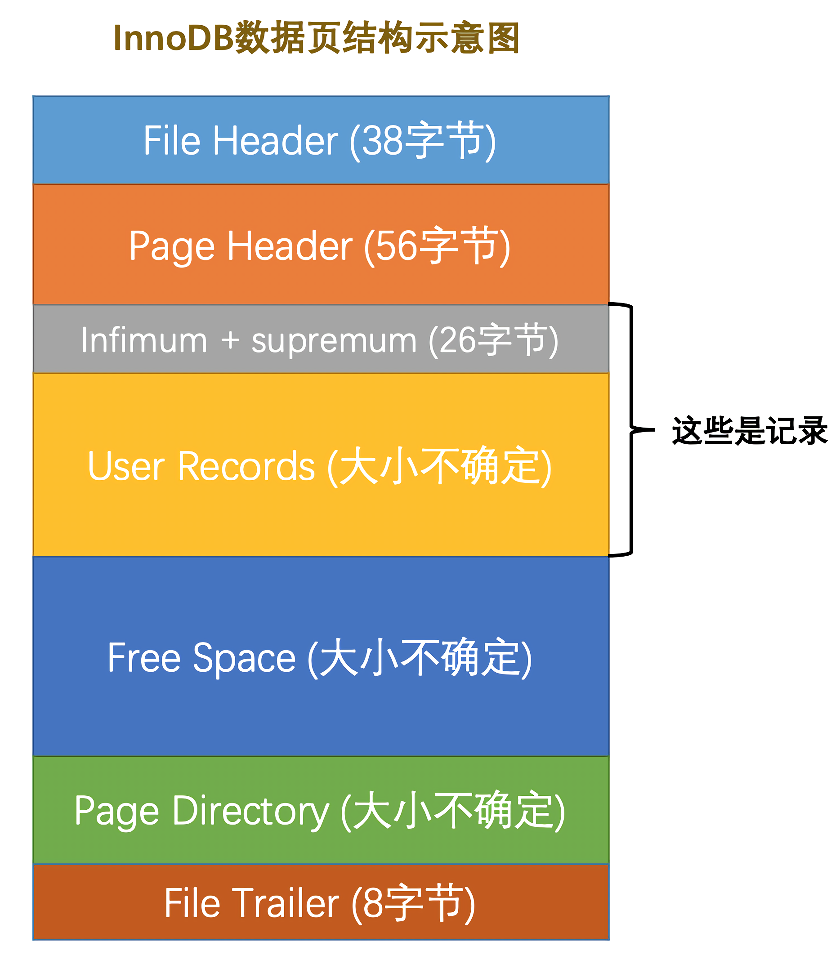
索引结构
InnoDB引擎的索引结构是B+树,只有叶子节点会存储记录的数据,非叶子节点只存索引。
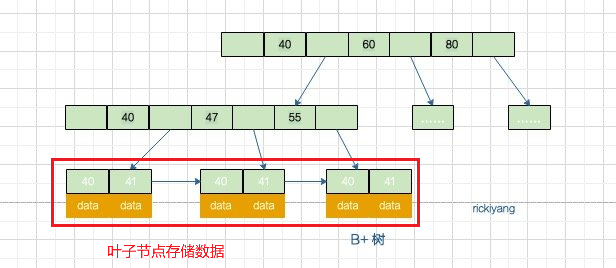
数据量计算
通常来说,三层B+树的索引结构可以达到一个较好的检索性能,只需三次磁盘IO即可完成数据查询。因此,我们以此为例进行计算。
根节点计算
我们假设数据表的主键是一个bigint类型的字段,bigint类型的长度是8Byte。而根节点除了要储存主键字段数据,还有存储下一层索引数据页的地址,大小为6Byte。
可以算出一条数据的索引所占空间为8+6=14Byte,进而可以算出根节点可以存储16184/14=1156个指针。

第二层节点计算
第二层的每个节点的指针数量和根节点一样,都是1156个指针,节点数量和根节点的指针数量一致。因此可以得出,第二层的指针数量为1156*1156=1336336。
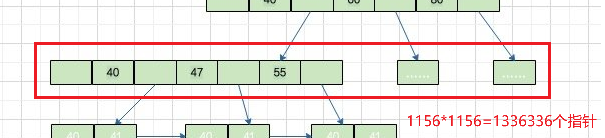
叶子节点计算
我们假设一行数据有100个字节,那么一个叶子节点可以存储16184/100≈161条数据。与第二层的指针数量相乘以后,可以得出总数据量为1336336*161=215150096条数据,大约2亿多条。

总结
通过以上的分析,我们可以发现,关于单表的数据量条数限制并没有一个统一的答案。单表可容纳多少数据量,这与表的主键以及数据行长度息息相关,需要具体情况具体分析。
另外,在阿里的开发规范中,关于数据库的建表规约,有一条这样的建议:
【推荐】单表行数超过 500 万行或者单表容量超过 2GB,才推荐进行分库分表。
说明:如果预计三年后的数据量根本达不到这个级别,请不要在创建表时就分库分表。
这个数据规模要比我们计算出来的小很多,可能由以下几个方面的原因导致:
- 实际业务中的表字段长度一般不止100个字节,主键索引结构也可能更加复杂,导致单个数据页可以存储的数据量大大降低;
- 磁盘IO性能的限制,当时机械硬盘还是主流,对数据量限制较为严格;
- 数据备份和恢复的难度,数据量过大会导致数据备份和恢复的难度大大提高。

















 3335
3335

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









