







 C99标准引入了可变长度数组(VLA)、内联函数(inline)和严格的类型别名规则。VLA允许在运行时确定数组长度,但长度在对象生存期内不可改变。内联函数旨在通过减少函数调用开销提高性能,但可能导致代码膨胀。严格类型别名规则限制了不同类型的对象别名访问,以避免潜在的未定义行为。此外,C99还新增了类型宽度宏、灵活的数组成员、复合文字、布尔数据类型等特性。
C99标准引入了可变长度数组(VLA)、内联函数(inline)和严格的类型别名规则。VLA允许在运行时确定数组长度,但长度在对象生存期内不可改变。内联函数旨在通过减少函数调用开销提高性能,但可能导致代码膨胀。严格类型别名规则限制了不同类型的对象别名访问,以避免潜在的未定义行为。此外,C99还新增了类型宽度宏、灵活的数组成员、复合文字、布尔数据类型等特性。
C99:
可变长度数组(VLA)
行内函数 (inline)
类型宽度宏,如 UINT32_MAX
严格的类型别名规则(strict aliasing)
灵活的数组成员 (Flexible Array Member)
复合文字 (Compound Literals)
布尔数据类型 _Bool
复数和虚数数据类型、
单行注释,使用//
一、可变长度数组(VLA)
C99及C++的数组对象定义是静态联编的,在编译期就必须给定对象的完整信息。但在程序设计过程中,我们常常遇到需要根据上下文环境来定义数组的情况,在运行期才能确知数组的长度。对于这种情况,C90及C++没有什么很好的办法去解决(STL的方法除外),只能在堆中创建一个内存映像与需求数组一样的替代品,这种替代品不具有数组类型,这是一个遗憾。C99的可变长数组为这个问题提供了一个部分解决方案。
一、编译期可变
可变长数组(variable length array,简称VLA)中的可变长指的是编译期可变,数组定义时其长度可为整数类型的表达式,不再象C90/C++那样必须是整数常量表达式。在C99中可如下定义数组:
int n = 10, m = 20;
char a[n];
int b[m][n];
a的类型为char[n],等效指针类型是char*,
b的类型为int[m][n],等效指针类型是int()[n]。
int()[n]是一个指向VLA的指针,是由int[n]派生而来的指针类型。
由此,C99引入了一个新概念:可变改类型(variably modified type,简称VM)。一个含有源自VLA派生的完整声明器被称为可变改的。VM包含了VLA和指向VLA的指针,注意VM类型并没有创建新的类型种类,VLA和指向VLA的指针仍然属于数组类型和指针类型,是数组类型和指针类型的扩展。
一个VM实体的声明或定义,必须符合如下三个条件:
- 1代表该对象的标识符属于普通标识符(ordinary identifier);
- 2具有代码块作用域或函数原型作用域;
- 3无链接性。
Ordinary identifier指的是除下列三种情况之外的标识符:
- 1标签(label);
- 2结构、联合和枚举标记(struct tag、uion tag、enum tag);
- 3结构、联合成员标识符。
这意味着VM类型的实体不能作为结构、联合的成员。第二个条件限制了VM不能具有文件作用域,存储连续性只能为auto,这是因为编译器通常把全局对象存放于数据段,对象的完整信息必须在编译期内确定。
VLA不能具有静态存储周期,但指向VLA的指针可以。
两个VLA数组的相容性,除了满足要具有相容的元素类型外,决定两个数组大小的表达式的值也要相等,否则行为是未定义的。
下面举些实例来对数种VM类型的合法性进行说明:
#include <stdio.h>
int n = 10;
int a[n]; /*非法,VM类型不能具有文件作用域*/
int (*p)[n]; /*非法,VM类型不能具有文件作用域*/
struct test
{
int k;
int a[n]; /*非法,a不是普通标识符*/
int (*p)[n]; /*非法,p不是普通标识符*/
};
int main( void )
{
int m = 20;
struct test1
{
int k;
int a[n]; /*非法,a不是普通标识符*/
int (*p)[n]; /*非法,a不是普通标识符*/
};
extern int a[n]; /*非法,VLA不能具有链接性*/
static int b[n]; /*非法,VLA不能具有静态存储周期*/
int c[n]; /*合法,自动VLA*/
int d[m][n]; /*合法,自动VLA*/
static int (*p1)[n] = d; /*合法,静态VM指针*/
n = 20;
static int (*p2)[n] = d; /*未定义行为*/
return 0;
}
一、生存期内不可改变
一个VLA对象的大小在其生存期内不可改变,即使决定其大小的表达式的值在对象定义之后发生了改变。有些人看见可变长几个字就联想到VLA数组在生存期内可自由改变大小,这是误解。VLA只是编译期可变,一旦定义就不能改变,不是运行期可变,运行期可变的数组叫动态数组,动态数组在理论上是可以实现的,但付出的代价可能太大,得不偿失。考虑如下代码:
#include <stdio.h>
int main( void )
{
int n = 10, m = 20;
char a[m][n];
char (*p)[n] = a;
printf( “%u %u”, sizeof( a ), sizeof( *p ) );
n = 20;
m = 30;
printf( “/n” );
printf( “%u %u”, sizeof( a ), sizeof( *p ) );
return 0;
}
虽然n和m的值在随后的代码中被改变,但a和p所指向对象的大小不会发生变化。
上述代码使用了运算符sizeof,在C90/C++中,sizeof从操作数的类型去推演结果,不对操作数进行实际的计算,运算符的结果为整数常量。当sizeof的操作数是VLA时,情形就不同了。sizeof必须对VLA进行计算才能得出VLA的大小,运算结果为整数,不是整数常量。
VM除了可以作为自动对象外,还可以作为函数的形参。作为形参的VLA,与非VLA数组一样,会调整为与之等效的指针,例如:
void func( int a[m][n] ); 等效于void func( int (*a)[n] );
在函数原型声明中,VLA形参可以使用*标记,用于[]中,表示此处声明的是一个VLA对象。如果函数原型声明中的VLA使用的是长度表达式,该表达式会被忽略,就像使用了标记一样,下面几个函数原型声明是一样的:
void func( int a[m][n] );
void func( int a[*][n] );
void func( int a[ ][n] );
void func( int a[][] );
void func( int a[ ][*] );
void func( int (a)[] );
标记只能用在函数原型声明中。再举个例:
#include<stdio.h>
void func( int, int, int a[*][*] );
int main(void)
{
int m = 10, n = 20;
int a[m][n];
int b[m][m*n];
func( m, n, a ); /*未定义行为*/
func( m, n, b );
return 0;
}
void func( int m, int n, int a[m][m*n] )
{
printf( "%u/n", sizeof( *a ) );
}
除了*标记外,形参中的数组还可以使用类型限定词const、volatile、restrict和static关键字。由于形参中的VLA被自动调整为等效的指针,因此这些类型限定词实际上限定的是一个指针,例如:
void func( int, int, int a[const][*] );
//等效于
void func( int, int, int ( const a )[] );
//它指出a是一个const对象,不能在func内部直接通过a修改其代表的对象。例如:
void func( int, int, int a[const][*] );
void func( int m, int n, int a[const m][n] )
{
int b[m][n];
a = b; //错误,不能通过a修改其代表的对象
}
static表示传入的实参的值至少要跟其所修饰的长度表达式的值一样大。例如:
void func( int, int, int a[const static 20][*] );
……
int m = 20, n = 10;
int a[m][n];
int b[n][m];
func( m, n, a );
func( m, n, b ); /*错误,b的第一维长度小于static 20*/
类型限定词和static关键字只能用于具有数组类型的函数形参的第一维中。这里的用词是数组类型,意味着它们不仅能用于VLA,也能用于一般数组形参。
总的来说,VLA虽然定义时长度可变,但还不是动态数组,在运行期内不能再改变,受制于其它因素,它只是提供了一个部分解决方案。
二、行内函数 (inline)
C99引入一个新关键字inline,用于定义内联函数(inline function)。通常函数的调用都有一定的开销,因为函数的调用包括建立调用、传递参数、跳转到函数代码并返回。内联函数就是以空间换时间,使函数的调用更加快捷。
标准规定:具有内部链接的函数可以成为内联函数,还规定了内联函数的定义与调用该函数的代码必须在同一个文件中。因此最简单的办法是使用inline和static修饰。通常,内联函数应定义在首次使用它的文件中,所以内联函数也相当于函数原型。
一、和宏一样快的内联函数
通过声明一个函数内联,你可以使用 GCC 编译器更快地调用这个函数。GCC能实现这一点的一种方法是:将该函数的代码集成到其调用方的代码中。通过消除函数调用开销(建立调用、传递参数、跳转到函数代码并返回),来加速代码的执行;
此外,如果函数有实参为常量,那么这些实参的已知值可能允许在编译时进行简化,因此并不需要包含所有内联函数的代码。内联函数会影响程序的代码量,并且这种影响是难以预测的; 根据具体情况,通过将函数内联,目标代码可能会变大或变小。你还可以在使用GCC编译时,尝试使用选项:-finline-functions ,将所有“足够简单”的函数集成到它们的调用方中。
GCC 实现了声明内联函数的三种不同语义:一种是-std=gnu89或者是 -fgnu89-inline,或者使用 gnu_inline 属性时,让所有内联声明中都存在。另一种是 -std=c99, -std=gnu99 ,或者使用后一个C版本的选项(不包括-fgnu89-inline) ,第三种是在编译 C + + 时使用。
要声明一个函数为内联,可以在它的声明中使用 inline 关键字,如下所示:
static inline int
inc (int *a)
{
return (*a)++;
}
如果您正在编写一个头文件用以包含在 ISO C90程序中,需要使用 __inline__关键字, 而不是 inline。查看替代关键字。详情见 Alternate Keywords。
这三种类型的内联在两个重要的情况下表现相似: 一是当内联关键字 inline被用于静态static函数时,就像上面的例子一样; 二是当一个函数首次声明时不使用内联关键字 inline,然后在定义时使用 inline,就像这样:
extern int inc (int *a); //声明时未使用 inline 修饰 ,其中extern 关键字可以省略
inline int // 函数定义时却使用 inline
inc (int *a)
{
return (*a)++;
}
二、实例
#include<stdio.h>
static inline int MAX(int a, int b)
{
return a > b ? a : b;
}
int a[] = {19, 3, 5, 2, 1, 0, 8, 7, 6, 4 };
int max(int n)
{
return n == 0 ? a[0] : MAX(a[n], max(n-1));
}
int main(void)
{
printf("Max = %d\n",max(9));
return 0;
}
该程序定义了一个内联函数MAX(),并定义了一个max()函数,通过递归以求出数组a中值最大的元素。此外,需要注意以下几点:
在日常使用内联函数时,并不建议对内联函数进行嵌套使用(递归),因为内联函数也是类似宏定义的字符串替换,嵌套使用很容易造成代码量增大和冗余。
static 关键字不能省略,要将内联函数定义为 静态static函数,读者可以尝试将static关键字去除,
**并使用 gcc main.c -g 命令进行编译 。编译器会报出undefined reference to MAX的错误,关于此错误的解析可以参考gcc编译inline函数报错:未定义的引用
$ gcc main.c -g
$ objdump -dS a.out
在关于MAX()和max()函数的汇编部分,可以看到:
static inline int MAX(int a, int b)
{
1149: 55 push %rbp
114a: 48 89 e5 mov %rsp,%rbp
114d: 89 7d fc mov %edi,-0x4(%rbp)
1150: 89 75 f8 mov %esi,-0x8(%rbp)
return a > b ? a : b;
1153: 8b 45 fc mov -0x4(%rbp),%eax
1156: 39 45 f8 cmp %eax,-0x8(%rbp)
1159: 0f 4d 45 f8 cmovge -0x8(%rbp),%eax
}
115d: 5d pop %rbp
115e: c3 retq
int max(int n)
{
115f: f3 0f 1e fa endbr64
1163: 55 push %rbp
1164: 48 89 e5 mov %rsp,%rbp
1167: 48 83 ec 10 sub $0x10,%rsp
116b: 89 7d fc mov %edi,-0x4(%rbp)
return n == 0 ? a[0] : MAX(a[n], max(n-1));
116e: 83 7d fc 00 cmpl $0x0,-0x4(%rbp)
1172: 75 08 jne 117c <max+0x1d>
1174: 8b 05 a6 2e 00 00 mov 0x2ea6(%rip),%eax # 4020 <a>
117a: eb 2f jmp 11ab <max+0x4c>
117c: 8b 45 fc mov -0x4(%rbp),%eax
117f: 83 e8 01 sub $0x1,%eax
1182: 89 c7 mov %eax,%edi
1184: e8 d6 ff ff ff callq 115f <max>
1189: 89 c2 mov %eax,%edx
118b: 8b 45 fc mov -0x4(%rbp),%eax
118e: 48 98 cltq
1190: 48 8d 0c 85 00 00 00 lea 0x0(,%rax,4),%rcx
1197: 00
1198: 48 8d 05 81 2e 00 00 lea 0x2e81(%rip),%rax # 4020 <a>
119f: 8b 04 01 mov (%rcx,%rax,1),%eax
11a2: 89 d6 mov %edx,%esi
11a4: 89 c7 mov %eax,%edi
11a6: e8 9e ff ff ff callq 1149 <MAX>
}
11ab: c9 leaveq
11ac: c3 retq
在倒数第四行可以看到MAX函数的调用call命令:11a6: e8 9e ff ff ff callq 1149 <MAX>,说明MAX()函数此时是作为普通函数使用的。
如果使用-O选项指定GCC进行优化编译,然后反汇编:
可以看到max()函数的汇编代码,但是没有MAX()函数的汇编代码:
int max(int n)
{
1149: f3 0f 1e fa endbr64
return n == 0 ? a[0] : MAX(a[n], max(n-1));
114d: 85 ff test %edi,%edi
114f: 75 07 jne 1158 <max+0xf>
1151: 8b 05 c9 2e 00 00 mov 0x2ec9(%rip),%eax # 4020 <a>
}
1157: c3 retq
{
1158: 53 push %rbx
1159: 89 fb mov %edi,%ebx
return n == 0 ? a[0] : MAX(a[n], max(n-1));
115b: 8d 7f ff lea -0x1(%rdi),%edi
115e: e8 e6 ff ff ff callq 1149 <max>
1163: 48 8d 15 b6 2e 00 00 lea 0x2eb6(%rip),%rdx # 4020 <a>
116a: 48 63 db movslq %ebx,%rbx
return a > b ? a : b;
116d: 39 04 9a cmp %eax,(%rdx,%rbx,4)
1170: 0f 4d 04 9a cmovge (%rdx,%rbx,4),%eax
}
1174: 5b pop %rbx
1175: c3 retq
可以看到,并没有call指令调用MAX函数, MAX函数的指令是内联在max函数中的,由于源代码和指令的次序无法对应, max和MAX函数的源代码也交错在一起显示。 因为MAX()函数已经嵌入到max()函数里面了,此时编译器把MAX()函数当作内联函数,所以没有给它分配单独的代码空间,所以也无法获得该内联函数的地址。
关于C语言的内联函数的使用总结,有如下几点:
由于并未给内联函数预留单独的代码块,所以无法获得内联函数的地址,另外,内联函数无法在调试器中显示。
由于内联函数具有内部链接,所以在多个文件中定义同一个内联函数不会产生什么影响。
如果多个文件都需要使用同一个内联函数,可以将它定义在h头文件中
三、类型宽度宏,如 UINT32_MAX
在C99中,我包括stdint.h,它给了UINT32_MAX以及uint32_t。然而,在C ++中UINT32_MAX被定义出来。我可以在包含stdint.h之前定义__STDC_LIMIT_MACROS,但是如果有人在包括stdint.h本身之后包含我的头部,那么它不起作用。
在C ++中,找到uint32_t中可表示的最大值的标准方法
不确定uint32_t,但对于基本类型(bool,char,signed char,unsigned char,wchar_t,short,unsigned short,int,unsigned int,,unsigned long,float,double和long double),则可以通过#include 使用numeric_limits模板。
cout <<"Minimum value for int:" << numeric_limits<int>::min() << endl;
cout <<"Maximum value for int:" << numeric_limits<int>::max() << endl;
如果uint32_t是上述之一的#define,则此代码应立即可用
还是uint32_t是上述之一的typedef?
我当然希望它是typedef。 如果您的工具为此使用#define,我会质疑它们的质量。
为了避免numeric_limits :: min(),numerical_limits :: max()与std :: min()和std :: max()混淆,我必须将其括在这样的括号中:(std :: numeric_limits: :max)();
std::numeric_limits< T >::max()定义类型T的最大值。
std::numeric_limits< T >::max()定义类型T的最大值。
你也可以
#define UINT32_MAX ((uint32_t)-1)
如果使用静态变量,则会遇到以下问题:如果将类内的常量值分配给numeric_limits :: max(),则由于初始化的顺序,该值实际上将设置为零(请参见零初始化文章)。和局部范围静态变量的静态初始化)
因此,在这种情况下,只能使用Lior Kogan的答案来工作。
四、严格的类型别名规则(strict aliasing)
一、严格别名(Strict Aliasing)规则是什么,编译器为什么不做我想做的事?
在 C 和 C++中,当多个左值 lvalue 指向同一个内存区域时,就会出现别名(alias)。
int anint = 42;
int *intptr=&anint;
intptr 改变, anint 也会改变的值。这是因为 intpr 是 anint 的 alias
另一个例子
int anint;
void foo( int &i1, int &i2);
foo(anint,anint);
foo(anint,anint) 函数调用,使得 i1,i2 均为 anint 的 alias。这是一个合法的例子,编译器会认为 i1 和 i2 可能会指向同一内存区域,并生成正确的代码。
二、类型双关(Type Punning)
别名(alias)最常见的用途就是类型双关(Type Punning)。
有时我们想绕过类型系统,将一个对象解释为不同的类型。这就是所谓的类型双关,将一段内存
重新解释为另一种类型。
类型双关对于那些想要访问对象的底层表示的任务来说是非常有用的。典型的类型双关使用的领域是编译器、序列化、网络传输等。
类型双关传统上这是通过获取对象的地址,将其转换为我们想要重新解释的类型的指针,然后访问该值,或者换句话说,通过别名(alias)来实现。
以下就是类型双关的例子,但这不是一个合法的别名(alias),在标准定义中,这是未定义的行为。
int x = 1 ;
// In C
float *fp = (float*)&x ; // Not a valid aliasing
// In C++
float *fp = reinterpret_cast<float*>(&x) ; // Not a valid aliasing
printf( "%f\n", *fp );
三、严格别名(strict aliasing)规则
简单说,严格别名规则就是编译器当看到多个别名(alias)时,会在一定规则下默认它们指向不同的内存区域(即使实际上可能指向相同的区域),并以此进行优化,可能会生成与我们期望不同的代码。
控制严格别名(strict aliasing)规则的编译选项是 -fstrict-aliasing 和-Wstrict-aliasing,该编译选项在 -O2, -O3, -Os 下默认开启。Optimize-Options
int anint;
void foo(char *p1, int *p2);
// 符合strict aliasing,编译器认为p1,p2可能会指向同一内存区域
foo((char*)(&anint), &anint);
void bar(int *p1, float *p2);
// 违背strict aliasing,编译器认为p1,p2不会指向同一内存区域 ,为 Undefined Behavior
bar(&anint, (float*)(&anint));
四、在 C11 标准(N1570 draft)中的定义
一、In Section *6.5 Expressions paragraph 7*
对象的存储值只能由具有以下类型之一的左值表达式访问:(An object shall have its stored value accessed only by an lvalue expression that has one of the following types:)
- 与对象的有效类型兼容的类型(a type compatible with the effective type of the object)
int x = 1;
int *p = &x;
printf("%d\n", *p); // *p 是int类型的左值表达式,与int类型兼容(相同)
- 与对象的有效类型兼容类型的限定版本(a qualified version of a type compatible with the effective type of the object)
int x = 1;
const int *p = &x;
printf("%d\n", *p); // *p 是const int类型的左值表达式,与int类型兼容
- 与对象的有效类型相对应的有符号或无符号类型的类型(a type that is the signed or unsigned type corresponding to the effective type of the object)
//例如 使用signed int * ,或者 unsigned int * 作为 int 类型的别名
int x = 1;
unsigned int *p = (unsigned int*)&x;
printf("%u\n", *p ); // *p 是unsigned int类型的左值表达式,是int类型对应的无符号类型
注意, 使用 int * 作为 unsigned int 的 alias ,不符合标准,但 gcc 和 clang 都做了拓展,因此没有问题。
unsigned int x = 42;
int *p = (int *)&x;
printf("%d\n", *p); // No Warnning,No Error
二、关于拓展这一点,更多的讨论见以下链接
Why does gcc and clang allow assigning an unsigned int * to int * since they are not compatible types, although they may alias 。https://twitter.com/shafikyaghmour/status/957702383810658304 and https://gcc.gnu.org/ml/gcc/2003-10/msg00184.html
- 类型是与对象的有效类型相对应的限定版本有符号或无符号类型(a type that is the signed or unsigned type corresponding to a qualified version of the effective type of the object)
int x = 1;
const unsigned int *p = (const unsigned int*)&x;
printf("%u\n", *p );
- 聚合或union类型,其成员中包括上述类型之一(递归地包括子聚合或包含联合的成员)(an aggregate or union type that includes one of the aforementioned types among its members (including, recursively, a member of a subaggregate or contained union))
struct foo {
int x;
};
void foobar( struct foo *fp, int *ip ); // struct foo 是一个聚合类型,并包含 int 类型,因此可以alias with *ip
foo f;
foobar( &f, &f.x );
- 字符类型(a character type)
int x = 65;
char *p = (char *)&x;
printf("%c\n", *p ); // *p 是 char 类型的左值表达式,为character type,可以作为任何类型的 alias
char 是严格别名规则下的银弹,可以作为任何类型的 alias。不只是 char,unsigned char ,uint8_t, int8_t 也满足这条规则。
五、在 C++17 标准中(N4659 draft)中的定义
一、In section *[basic.lval] paragraph 11*
如果程序试图通过下列类型之外的泛左值(glvalue) 访问对象的存储值,则行为是未定义的:(If a program attempts to access the stored value of an object through a glvalue of other than one of the following types the behavior is undefined:)
- 泛左值 (glvalue)(“泛化 (generalized)”的左值)是一个表达式,其值可确定某个对象或函数的标识;
(11.1) - 对象的动态类型(the dynamic type of the object)
void *p = malloc( sizeof(int) ); // 开辟了内存区域,但对象还没有被初始化,其生命周期还没开始
int *ip = new (p) int{0}; // Placement new 动态赋予对象类型为 int
std::cout << *ip << "\n"; // *ip 是 int 类型的 泛左值表达式,与开辟内存空间对象的动态类型 int 相同
(11.2) - 对象的动态类型的 cv 限定版本(a cv-qualified version of the dynamic type of the object)
int *a[3];
const int *const *p = a;
const int *q = p[1]; // ok, 通过类似类型 const int* 的左值读取 int*
(11.4) - 对象的动态类型对应的有符号或无符号类型(a type that is the signed or unsigned type corresponding to the dynamic type of the object)
// https://godbolt.org/g/KowGXB
// si,ui 是对应的有符号或无符号类型,编译器生成了正确的代码,及认为si和ui可能指向同一内存区域,生成的汇编代码没有直接返回立即数1
signed int foo( signed int &si, unsigned int &ui ) {
si = 1;
ui = 2;
return si;
}
(11.5) - 对象的动态类型对应的有符号或无符号类型的cv 限定版本(a type that is the signed or unsigned type corresponding to a cv-qualified version of the dynamic type of the object)
signed int foo( const signed int &si1, int &si2); // Hard to show this one assumes aliasing
(11.6) - 在其元素或非静态数据成员中包含上述类型之一的聚合或union类型 (递归地包括子聚合或包含的union的元素或非静态数据成员)(an aggregate or union type that includes one of the aforementioned types among its elements or nonstatic data members (including, recursively, an element or non-static data member of a subaggregate or contained union))
struct foo {
int x;
};
// https://godbolt.org/g/z2wJTC
int foobar( foo &fp, int &ip ) {
fp.x = 1;
ip = 2;
return fp.x;
}
foo f;
foobar( f, f.x );
(11.7) - 对象动态类型的基类类型 (可能是 cv 限定的) (a type that is a (possibly cv-qualified) base class type of the dynamic type of the object)
struct foo { int x ; };
struct bar : public foo {};
int foobar( foo &f, bar &b ) {
f.x = 1;
b.x = 2;
return f.x;
}
(11.8) - a char, unsigned char, or std:: byte type.
int foo( std::byte &b, uint32_t &ui ) {
b = static_cast<std::byte>('a');
ui = 0xFFFFFFFF;
return std::to_integer<int>( b ); // b gives us a glvalue expression of type std::byte which can alias
// an object of type uint32_t
}
char` 永远的银弹,外加 `std::byte
二、C 和 C++ 标准对 strict aliasing 的定义大致相同,但有区别。
C++ 没有 C 里 有效类型 effective type 、 兼容类型 compatible type 的概念,而 C 没有 C++ 中 动态类型 dynamic type 、 相似类型 similar type 的概念。
// 以下,在C中合法,在C++中未定义(因为没placement new)
void *p = malloc(sizeof(float));
float f = 1.0f;
memcpy( p, &f, sizeof(float)); // Effective type of *p is float in C
// Or
float *fp = p;
*fp = 1.0f; // Effective type of *p is float in C
C++ 中一片内存区域必须被初始化(placement new)后才能被合法使用
float *fp = new (p) float{1.0f} ; // Dynamic type of *p is now float
六、严格别名(strict aliasing)为什么讨厌
一、因为严格别名(strict aliasing)规则的存在,我们很容易写出符合直觉,但是实际上是 Undefined Behavior 的代码。
违反 strict aliasing rule 的例 1
int foo( float *f, int *i ) {
*i = 1;
*f = 0.f;
return *i;
}
int main() {
int x = 0;
std::cout << x << "\n"; // Expect 0,Output 0
x = foo((float*)(&x), &x);
std::cout << x << "\n"; // Expect 0, But Output 1
}
函数 foo( float *f, int *i ),编译器根据 strict aliasing rule 会认为 *f 和 *i 指向不同的内存区域,并以此进行优化,但实际上指向了相同的内存区域,因此产生了错误的结果。
foo(float*, int*): # @foo(float*, int*)
mov dword ptr [rsi], 1
mov dword ptr [rdi], 0
mov eax, 1
ret
这个例子比较直接,生成了错误的函数体,比较明显。
违反 strict aliasing rule 的例 2,
#include <stdio.h>
#include <stdint.h>
void Store128(void *dst, const void *src) {
const uint8_t *s = (const uint8_t*)src;
uint8_t *d = (uint8_t*)dst;
for (int i = 0; i < 16; i+=4)
*(uint32_t*)(d + i) = *(const uint32_t*)(s + i);
}
int main(void)
{
float A[4] = {1, 2, 3, 4};
float B[4] = {5, 6, 7, 8};
Store128(B, A);
for (int i = 0; i < 4; i++)
printf("%f\n", B[i]);
return 0;
}
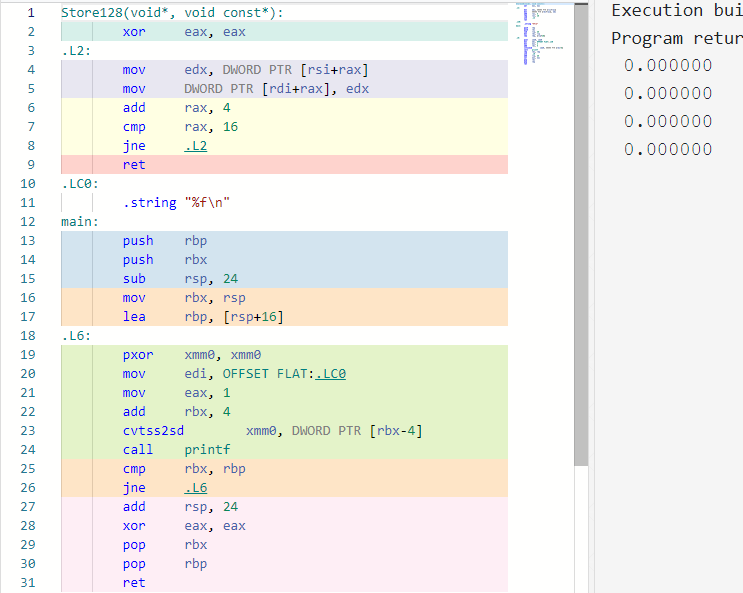
代码非常符合直觉, Store128() 里每次复制 4 字节,循环 4 次, 生成的函数体代码也没有问题。但错误之处在于 float A[],B[] 这两个变量被优化没了。
使用基于类型的别名分析(type-based-alias-analysis TBAA) 的优化器根据 strict aliasing rule 进行优化。
在本例中,编译器可能认为 *(uint32_t*) 不会影响 float 类型的变量,因此把 A,B 两个 float 变量都优化掉了,但这很明显是错误的。
这个例子为 gcc 独有,clang 和 msvc 对于这个例子都能编译正确。对于 gcc,编译时加上 -fno-strict-aliasing 即可编译正确,可见这个例子还是因为 strict aliasing rule 。
与 strict aliasing rule 相关的例 3 ,这个例子不是错误,而是一个与 strict aliasing 相关的性能优化问题。
#include <iostream>
#include <iomanip>
#include <stdint.h>
struct T{
uint8_t* target;
char* source;
void unpack3bit( int size);
};
void T::unpack3bit(int size) {
while(size > 0){
uint64_t t = *reinterpret_cast<uint64_t*>(source);
// uint8_t* target = this->target; // << ptr cached in local variable
target[0] = t & 0x7;
target[1] = (t >> 3) & 0x7;
target[2] = (t >> 6) & 0x7;
target[3] = (t >> 9) & 0x7;
target[4] = (t >> 12) & 0x7;
target[5] = (t >> 15) & 0x7;
target[6] = (t >> 18) & 0x7;
target[7] = (t >> 21) & 0x7;
target[8] = (t >> 24) & 0x7;
target[9] = (t >> 27) & 0x7;
target[10] = (t >> 30) & 0x7;
target[11] = (t >> 33) & 0x7;
target[12] = (t >> 36) & 0x7;
target[13] = (t >> 39) & 0x7;
target[14] = (t >> 42) & 0x7;
target[15] = (t >> 45) & 0x7;
source+=6;
size-=6;
target+=16;
}
}
void unpack3bit(uint8_t* target, char* source, int size) {
while(size > 0){
uint64_t t = *reinterpret_cast<uint64_t*>(source);
target[0] = t & 0x7;
target[1] = (t >> 3) & 0x7;
target[2] = (t >> 6) & 0x7;
target[3] = (t >> 9) & 0x7;
target[4] = (t >> 12) & 0x7;
target[5] = (t >> 15) & 0x7;
target[6] = (t >> 18) & 0x7;
target[7] = (t >> 21) & 0x7;
target[8] = (t >> 24) & 0x7;
target[9] = (t >> 27) & 0x7;
target[10] = (t >> 30) & 0x7;
target[11] = (t >> 33) & 0x7;
target[12] = (t >> 36) & 0x7;
target[13] = (t >> 39) & 0x7;
target[14] = (t >> 42) & 0x7;
target[15] = (t >> 45) & 0x7;
source+=6;
size-=6;
target+=16;
}
}
void T::unpack3bit(int size) {
...
mov rcx, rax
mov rdi, QWORD PTR [rdx] // useless code, load `target` addresss
shr rcx, 3
and ecx, 7
mov BYTE PTR [rdi+1], cl // target[1] = ...
mov rcx, rax
mov rdi, QWORD PTR [rdx] // useless code, load `target` addresss
shr rcx, 6
and ecx, 7
mov BYTE PTR [rdi+2], cl // target[2] = ...
...
}
void unpack3bit(uint8_t* target, char* source, int size) {
...
mov rdx, rax
shr rdx, 3
and edx, 7
mov BYTE PTR [rdi+1], dl
mov rdx, rax
shr rdx, 6
and edx, 7
mov BYTE PTR [rdi+2], dl
...
}
unpack3bit 这个函数有两个版本,一个是类的成员函数,一个是普通函数,他们的函数体完全一样,但编译出来的汇编却不完全相同。
T::unpack3bit 每次移位之前都重新获取 target 变量的地址放到 rdi 中, mov rdi, QWORD PTR [rdx] ,而 target 整个过程没有改变,这样做没有必要。
提问者声称 This slows down the code considerably (around 15% in my measurements). ,降低了约 15%的性能。
这个问题的原因很隐晦,是和 Strict aliasing rules 相关。类的成员函数 T::unpack3bit 版本,target 实际上是 this->target,而且 target 变量的类型是 uint8_t,也就是 unsigned char, 符合标准中的最后一条,编译器认为 this->target 可能是 this 的 alias。
因此,每次修改 target,编译器认为 this 也可能随之变化,即 target[0] = t & 0x7; 可能改变了 this 指针。虽然很怪异,但 target 是 unsigned char 类型,满足 Strict aliasing rules,编译器就做出了这样的假设。
解决方法有 3,其 1 是将 this->target 缓存在本地变量中,就像那行注释一样;其 2 是修改 target 变量类型为 uint16_t,并修改相关代码;其 3 是使用 restrict 关键字(Only in C,在 C++中,并无明确统一的标准支持 restrict 关键字。但是很多编译器实现了功能相同的关键字,例如 gcc 和 clang 中的__restrict 关键字)。
在 C 和 C++中的标准都分别规定了哪些表达式类型被允许与哪些类型进行别名。编译器假设我们将会严格(strict)遵守标准定义的 aliasing 规则,以进行优化)。编译器作者知道严格的别名规则意味着什么,此规则是为了让编译器作者知道他们何时可以安全地假设通过变量进行的更改不会影响另一个变量。
而作为程序员,编写代码时要格外注意严格别名规则,很有可能符合直觉的代码,实际上是 UB,或者意想之外的性能问题。
严格别名(strict aliasing)规则为什么讨厌?因为,它为程序员带来更多心智负担,不只是规则本身,编译器对于规则的理解/实现可能也存在不完美(如上文中 gcc 的例子)。
七、如何正确的进行类型双关(Type Punning)
上文说过 alias 通常是为了进行类型双关,那么如何正确的进行,写出符合标准的代码呢?
考虑一个例子,我们从网络中获得一个 unsigned char 数组,并把其解释为 double 数组,并对每个 double 进行操作。(不考虑端序问题)
我们可能会写出这样的代码
double foo(double x ) { return x ;}
// 假设 len 是 sizeof(double) 的整数倍
double bar( unsigned char *p, size_t len ) {
double result = 0.0;
for( size_t index = 0; index < len; index += sizeof(double) ) {
double ui = *(double*)(&p[index]);
result += foo( ui );
}
return result;
}
代码非常符合直觉,在我的电脑上也可以正确的运行,但实际上却是 undefined behavior,编译器在 fstrict-aliasing 下不保证生成正确的代码。
八、-fno-strict-aliasing of C/C++
编译时加上 fno-strict-aliasing 选项,C 和 C++ 均适用,禁用 strict aliasing rule,缺点是在获得便利的同时,也放弃了编译器可能进行的额外的优化(TBAA)
九、memcpy of C/C++
在 C 和 C++下,均可以使用 memcpy(), 进行符合 strict aliasing rules 的类型双关。
double foo(double x) { return x; }
// 假设 len 是 sizeof(double) 的整数倍
double bar(unsigned char *p, size_t len) {
double result = 0.0;
for (size_t index = 0; index < len; index += sizeof(double)) {
double ui;
memcpy(&ui, &p[index], sizeof(double));
result += foo(ui);
}
return result;
}
十、union of C
通过 union 进行类型双关,仅在 C 下可用,对于 C++ 不可用(不符合标准)。
C++ 标准 : 联合体的大小仅足以保有其最大的数据成员。其他数据成员在该最大成员的一部分相同的字节分配。分配的细节是实现定义的,且读取并非最近写入的联合体成员是未定义行为。许多编译器以非标准语言扩展实现读取联合体的不活跃成员的能力。
double foo(double x) { return x; }
// 假设 len 是 sizeof(double) 的整数倍
double bar(unsigned char *p, size_t len) {
double result = 0.0;
union {
double d;
unsigned char carr[sizeof(double)];
} tmp;
for (size_t index = 0; index < len; index += sizeof(double)) {
for (size_t i = 0; i < sizeof(double); i++) {
tmp.carr[i] = p[index + i];
}
result += foo(tmp.d);
}
return result;
}
十一、std::bit_cast of C++20
Todo
十二、内存对齐
在进行类型双关时,除了要注意 strict aliasing rule,还有一个问题值得关注就是内存对齐。
C 和 C++标准都规定了不同对象的内存对齐要求,这些要求限制了对象可以被分配(在内存中)的位置,从而限制了对象的访问。
一个例子, 首先假设
- alignof (char) and alignof (int) are 1 and 4 respectively
sizeof (int)is 4
将 char 数组解释为 int ,违反了严格别名要求,此外如果 char 数组对齐到 1 , 2, 3 字节的内存边界,将其解释为 int 也违反了内存对齐要求
char arr[4] = { 0x0F, 0x0, 0x0, 0x00 }; // Could be allocated on a 1 or 2 byte boundary
// (uintptr_t)(arr) % sizeof(int) != 0 , 这种情况即违反了对齐要求
int x = *reinterpret_cast<int*>(arr); // Undefined behavior we have an unaligned pointer
可以使用 alignas 或 _Alignas 关键字手动进行对齐。
alignas(alignof(int)) char arr[4] = { 0x0F, 0x0, 0x0, 0x00 };
int x = *reinterpret_cast<int*>(arr);
违反内存对齐,在某些平台上可能引发总线错误或者破坏访存的原子性。
https://en.wikipedia.org/wiki/Bus_error#Unaligned_access
Demonstrates torn loads for misaligned atomics https://gist.github.com/michaeljclark/31fc67fe41d233a83e9ec8e3702398e8 and tweet referencing this example https://twitter.com/corkmork/st
十三、restrict 关键字
根据 strict aliasing rule,编译器会进行优化,但有时,即使两个变量可能符合 alias 规则,但我们保证他们不会指向同一片内存空间,并把该信息提供给编译器,以进行更多的优化。
restrict 关键字 (since C99) 就起到了这样的作用。
C++ 标准中没有该关键字,但编译器都做了拓展,在 Gcc 中为 __restrict__ 或者 __restrict 。
一个例子:
//-O3
int add(int* a, int* b)
{
*a = 10;
*b = 12;
return *a + *b;
}
add(int*, int*):
mov DWORD PTR [rdi], 10
mov DWORD PTR [rsi], 12
mov eax, DWORD PTR [rdi]
add eax, 12
ret
这里变量 a,b 均为 int* 类型,是相容的 aliasing,即编译器认为他们可能指向同一内存区域,因此即使在 O3 下也没有直接优化为返回立即数.
int add(int* __restrict__ a, int* __restrict__ b)
{
*a = 10;
*b = 12;
return *a + *b;
}
add(int*, int*):
mov DWORD PTR [rdi], 10
mov eax, 22
mov DWORD PTR [rsi], 12
ret
当加上 __restrict__ 关键字后,我们从语义上保证变量 a,b 不会指向同一内存空间,编译器直接优化成了返回立即数 22.
十四、一点建议
对于 C++,更推荐使用 reinterpret_cast<>,而不是 C 风格的强制类型转换。这不是因为 reinterpret_cast<> 有什么特别的地方,只是因为 reinterpret_cast<> 便于搜索,在 code review 时便于审查,可以更明显得提示你:哦,在这个地方可能进行了类型 punning,我是否注意了 strict aliasing rule。
使用 -Wold-style-cast 以对使用 C 风格类型转换的地方进行 warnning。
此外,现在的编译器也变得更好了,上文中关于网络传输进行类型双关的例子,以及常见的 swap_words() 例子,虽然都违反了 strict aliasing rule,但编译器都能生成正确的代码,尽管这种写法在标准中是UB。
五、灵活的数组成员 (Flexible Array Member)
在讲述柔性数组成员之前,首先要介绍一下不完整类型(incomplete type)。不完整类型是这样一种类型,它缺乏足够的信息例如长度去描述一个完整的对象
一、incomplete types (types that describe objects but lack information needed to determine their sizes).
C与C++关于不完整类型的语义是一样的。
前向声明就是一种常用的不完整类型:
class base;
struct test;
base和test只给出了声明,没有给出定义。不完整类型必须通过某种方式补充完整,才能使用它们进行实例化,否则只能用于定义指针或引用,因为此时实例化的是指针或引用本身,不是base或test对象。
一个未知长度的数组也属于不完整类型:
extern int a[];
extern不能去掉,因为数组的长度未知,不能作为定义出现。不完整类型的数组可以通过几种方式补充完整才能使用,大括号形式的初始化就是其中一种方式:
int a[] = { 10, 20 };
二、柔性数组成员(flexible array member)也叫伸缩性数组成员
它的出现反映了C程序员对精炼代码的极致追求。这种代码结构产生于对动态结构体的需求。在日常的编程中,有时候需要在结构体中存放一个长度动态的字符串,一般的做法,是在结构体中定义一个指针成员,这个指针成员指向该字符串所在的动态内存空间,例如:
struct test
{
int a;
double b;
char *p;
};
p指向字符串。这种方法造成字符串与结构体是分离的,不利于操作,如果把字符串跟结构体直接连在一起,不是更好吗?于是,可以把代码修改为这样:
char a[] = “hello world”;
struct test *PntTest = ( struct test* )malloc( sizeof( struct test ) + strlen( a ) + 1 );
strcpy( PntTest + 1, a );
这样一来,( char* )( PntTest + 1 )就是字符串“hello world”的地址了(已经忽略p)。
这时候p成了多余的东西,可以去掉。但是,又产生了另外一个问题:
是使用( char* )( PntTest + 1 )不方便。
如果能够找出一种方法,既能直接引用该字符串,又不占用结构体的空间,就完美了,符合这种条件的代码结构应该是一个非对象的符号地址,在结构体的尾部放置一个0长度的数组是一个绝妙的解决方案。不过,C/C++标准规定不能定义长度为0的数组,因此,有些编译器就把0长度的数组成员作为自己的非标准扩展,例如:
struct test
{
int a;
double b;
char c[0];
};
*c*就叫柔性数组成员*,如果把PntTest指向的动态分配内存看作一个整体,c就是一个长度可以动态变化的结构体成员,柔性一词来源于此。c的长度为0,因此它不占用test的空间,同时PntTest->c就是“hello world”的首地址,不需要再使用( char* )( PntTest + 1 )这么丑陋的语法了。
鉴于这种代码结构所产生的重要作用,C99甚至把它收入了标准中:
三、Structure and union specifiers
As a special case, the last element of a structure with more than one named member may have an incomplete array type; this is called a flexible array member.
C99使用不完整类型实现柔性数组成员,标准形式是这样的:
struct test
{
int a;
double b;
char c[];
};
c同样不占用\test的空间,只作为一个符号地址存在,而且必须是结构体的最后一个成员。柔性数组成员不仅可以用于字符数组,还可以是元素为其它类型的数组,例如
struct test
{
int a;
double b;
float c[];
};
应当尽量使用标准形式,在非C99的场合,可以使用指针方法。有些人使用char a[1],这是非常不可取的,把这样的a用作柔性数组成员会发生越界行为,虽然C/C++标准并没有规定编译器应当检查越界,但也没有规定不能检查越界,为了一个小小的指针空间而牺牲移植性,是不值得的。
柔性数组到底如何使用呢?看下面例子:
typedef struct st_type
{
int i;
int a[0];
}type_a;
有些编译器会报错无法编译可以改成:
typedef struct st_type
{
int i;
int a[];
}type_a;
这样我们就可以定义一个可变长的结构体,用 sizeof(type_a)得到的只有 4,就是
**sizeof(i)=sizeof(int)。那个 0 个元素的数组没有占用空间,**而后我们可以进行变长操作了。通过如下表达式给结构体分配内存:
**type_a *p = (type_a*)malloc(sizeof(type_a)+100*sizeof(int));这样我们为结构体指针 p 分配了一块内存。用 p->item[n]就能简单地访问可变长元素。
但是这时候我们再用sizeof(p)**测试结构体的大小,发现仍然为4。是不是很诡异?我们
不是给这个数组分配了空间么?
别急,先回忆一下我们前面讲过的“模子” 。在定义这个结构体的时候,模子的大小就
已经确定不包含柔性数组的内存大小。柔性数组只是编外人员,不占结构体的编制。只是说
在使用柔性数组时需要把它当作结构体的一个成员,仅此而已。再说白点,柔性数组其实与
结构体没什么关系,只是“挂羊头卖狗肉”而已,算不得结构体的正式成员。
需要说明的是:C89不支持这种东西,C99把它作为一种特例加入了标准。但是,C99
所支持的是 incomplete type,而不是 zero array,**形同这种形式是非法的,支持的形式是形同int item[];只不过有些编译器把 int item[0];作为非标准扩展来支持,**而且在C99发布之前已经有了这种非标准扩展了,C99发布之后,有些编译器把两者合而为一了。当然,上面既然用 malloc函数分配了内存,肯定就需要用 free函数来释放内存:
free§;
经过上面的讲解,相信你已经掌握了这个看起来似乎很神秘的东西。不过实在要是没掌握也无所谓,这个东西实在很少用。
【柔性数组结构成员】
C99中,结构中的最后一个元素允许是未知大小的数组,这就叫做柔性数组成员,但结构中的柔性数组成员前面必须至少一个其他成员。柔性数组成员允许结构中包含一个大小可变的数组。sizeof返回的这种结构大小不包括柔性数组的内存。包含柔性数组成员的结构用malloc ()函数进行内存的动态分配,并且分配的内存应该大于结构的大小,以适应柔性数组的预期大小。
C语言版:
type_a *p = (type_a*)malloc(sizeof(type_a)+100*sizeof(int));
C++语言版:
type_a *p = (type_a*)new char[sizeof(type_a)+100*sizeof(int)];
而释放同样简单:
C语言版:
free(p);
C++语言版:
delete []p;
六、复合文字 (Compound Literals)
假如需要向带有一个int参量的函数传递一个值,您可以传递一个int变量,也可以传递一个int常量,比如5。
在C99标准以前:可以给函数传递数组,或者其他自定义的结构等,但是没有所谓的数组(结构)常量可以来传递。C99新增了复合文字(compound literal)。文字是非符号常量。例如:5是int类型的文字;82.3是float类型的文字等等。C99标准委员会认为:如果又能够表示数组和结构内容的复合文字,那么在编写程序的时候要方便的多
1.对于数组来说,复合文字看起来像是在数组的初始化列表前面加上用圆括号括起来的类型名。
int diva[2]={10,20};//普通数组
(int [2]){10,20};//一个复合文字
注意:类型名就是前面声明中去掉diva后剩余的部分,即int[2]。
2.初始化一个命名数组时可以省略数组大小,初始化一个复合文字时可以省略数组大小,编译器会自动计算元素的数目:
(int []){50,20,90};//有3个元素的复合文字
3.由于这些复合文字没有名称,因此不可能在一个语句中创建它们,然后在另一个语句中使用。而是必须在创建它们的同时通过某种方法来使用它们,一种方法是使用指针保存其位置。请看下面的例子:
int* pt1;
pt1=(int [2]){10,20};
众所周知,数组名其实就是指向数组首元素的指针,所以此处的pt1就相当于数组名,所以之后可以像使用数组名一样,使用这个指针了。
4.复合文字也可以做为实际参数被传递给带有类型与之匹配的形式参量的函数:
int sum(int ar[],int n)
{
int total=0;
for(int i=0;i<n;i++)
total+=ar[i];
return total;
}
int tot;
tot=sum((int[]{1,2,3,4,5,6}),6);
此处第一个参数是包含6个元素的int型数组,同时也是首元素的地址(同数组名一样)。这种给函数传递信息而不必先创建数组的做法,是复合常量的通常使用方法。
5.可以把这种技巧用在处理二维数组或多维数组的函数中。例如,下面的代码介绍如何创建一个二维int数组并保存其地址:
int (*pt2)[4];//声明一个数组指针
pt2=(int [2][4]){{1,2,3,-9},{4,5,6,-8}};
6.结构体中使用复合文字。
int add(struct xy instance)
{
return instance.x+instance.y;
}
int sum = add((struct xy){1,2}); //调用
7.对复合文字进行取址操作。
struct point{
double x;
double y;
};
struct point* instance=&((struct point){2.2,2.3});
8.总结:
(1)当一个类似结构的东西需要临时构造的时候,可以用 (type_name){xx,xx,xx},而type_name就是之前定义的格式,去掉变量名(数组名)即可, 这种使用方法有点像 C++ 的构造函数。
(2)其实,复合文字就相当于一个常量,只不过形式较为复杂而已,所有可以用常量的地方均可以用复合文字,例如,宏定义。
(3)使用复合文字,在想传一个“常量”时,就不必先定义,再传值了,比如传一个常数坐标(struct point{double x;double y;}),这样就不用先定义一个结构变量,再传结构体过去了,代码更加简洁。
(4)值得注意的是,复合文字具有左值语义。
七、布尔数据类型 _Bool 、复数类型Complex 和虚数类型Complex
一、简单介绍Bool和Complex、Complex
_Bool(布尔值类型)
对于学过其他语言(C++,JAVA等)的小伙伴来说布尔值类型肯定是不陌生的,
可是C语言在C99前还是没有布尔值类型的。
C99新增了stdbool.h头文件
stdbool.h定义如下:(摘抄stdbool.h)
<span style="color:#333333">//
// stdbool.h
//
// Copyright (c) Microsoft Corporation. All rights reserved.
//
// The C Standard Library <stdbool.h> header.
//
#ifndef _STDBOOL
#define _STDBOOL
#define __bool_true_false_are_defined 1
#ifndef __cplusplus
#define bool _Bool
#define false 0
#define true 1
#endif /* __cplusplus */
#endif /* _STDBOOL */
/*
* Copyright (c) 1992-2010 by P.J. Plauger. ALL RIGHTS RESERVED.
* Consult your license regarding permissions and restrictions.
V5.30:0009 */</span>
在stdbool.h中可以看到定义了bool、true、falses三个我们用到的宏
bool _Bool(布尔值类型)
true(真) 1
false(假) 0
PS:_Bool(布尔值类型)占用字节大小为1字节,原则来说1位内存大小就够了*(0或1)*
PS:C语言没有true,false关键字。
PS:判断真和假,true(真)只要大于1,false(假)0
二、_Complex(复数类型)
☆1)为什么要添加复数类型?
因为许多科学和工程计算都要用到负数和虚数。
☆2)复数类型和虚数类型都是有所保留的
但是复数和虚数都是有所保留的,因为不是所有程序都会用到复数和虚数,所以复数和虚数都是作为可选择的。
C11标准把整个复数软件包都作为可选项。
☆3)C语言的复数类型和虚数类型
目前C语言定义了三种复数类型:
float _Complex、double _Complex、long double _Complex
目前C语言定义了三种虚数类型:
float _Imaginary、double _Imaginary、long double _Imaginary
如果包含了complex.h则可以使用complex代替_Complex
☆4)复数类型解析
_Complex(复数类型)
复数类型分别定义了两个部分,一个表示实部,一个表示虚部。
举例说明:
float _Complex 那么分别定义了两个float(单精度浮点数类型),一个表示实部,另一个表示虚部。
☆5)_Imaginary(虚数类型)
因为_Complex(复数类型)里面已经包含虚数了,所以跟_Imaginary(虚数类型)存在重叠了,然而因为_Complex(复数类型)和_Imaginary(虚数类型)都不是硬性规定必须实现的,所以部分编译器都只实现了_Complex(复数类型)而没有实现_Imaginary(虚数类型)。
PS:(VS、DEV)没有实现_Imaginary(虚数类型)
三 、_Bool(布尔值类型)和_Complex(复数类型)、_Imaginary(虚数类型)的简单使用
☆1)_Bool(布尔值类型)
占用内存大小:
printf("type _Bool size:%u\n", sizeof(_Bool)); //1
_Bool(布尔值类型)占1字节内存大小
赋值操作:
#include <stdio.h>
#include <limits.h>
int main(void)
{
long int llTestTrueValue = LONG_MAX; //long max
long int llTestFalseValue = LONG_MIN; //long min
_Bool bTrue = 1; //true
_Bool bFlase = 0; //false
_Bool bTestTrue = llTestTrueValue; //test true
_Bool bTestFalse = llTestFalseValue; //test false
printf("-----------------test value-----------------\n");
printf("test true value:%ld\n", llTestTrueValue); //2147483647
printf("test false value:%ld\n", llTestFalseValue); //-2147483648
printf("--------------_Bool test value--------------\n");
printf("_Bool test true value:%d\n", bTestTrue); //1
printf("_Bool test false value:%d\n", bTestFalse); //1
printf("--------------------_Bool-------------------\n");
printf("_Bool true value:%d\n", bTrue); //1
printf("_Bool false value:%d\n", bFlase); //0
return 0;
}
从上面可以看到任何数字进行对Bool(布尔值类型)的变量进行赋值的时候都会先进行转换一下,赋值一个大于0和小于0的数字都会被转换成1,只有赋值0才会是0。所以可以总结得到将一个非0的数赋值给_Bool(布尔值类型)的变量都会被转换成1。
使用:
使用_Bool(布尔值类型)变量进行判断
#include <stdio.h>
#include <stdbool.h>
int main(void)
{
bool bTrue = true; //true
bool bFlase = false; //false
if(bTrue)
printf("true\n"); //true
else
printf("false\n"); //false
return 0;
}
PS:此处包含了stdbool.h,可以让读者了解stdbool.h的使用
之前介绍了stdbool.h中定了三个我们用到的宏,分别是bool,true,false
bool _Bool(布尔值类型)
true 1
false 0
所以上面赋值true,就等于直接赋值了1给布尔值类型的变量,false就等于赋值了0给布尔值类型的变量。
判断_Bool(布尔值类型)的变量,因为只有0为false,所以任何非0值都为true,因此输出true。
☆2)_Complex(复数类型)和_Imaginary(虚数类型)
占用内存大小:(此处使用的编译器为DEV)
#include <stdio.h>
int main(void)
{
printf("float _Complex size:%u\n", sizeof(float _Complex)); //8
printf("double _Complex size:%u\n", sizeof(double _Complex)); //16
printf("long double _Complex size:%u\n", sizeof(long double _Complex)); //32
return 0;
}
PS:拿float _Complex来说,一个float占用4字节,所以一个float _Complex占用了两个float,所以float _Complex分别定义了一个float的实部和虚部。
赋值:
实数部分赋值:
float _Complex fCex = 1.0f; //赋值实数部分
虚数部分赋值:
float _Complex fCex = 1.0if; //赋值虚数部分
PS:两个赋值之间的差别就是实数部分赋值是1.0f,虚数部分赋值是1.0if,i表示虚数(按道理来说就是imaginary的缩写第一个字母)
然后你们会问那样怎么实数虚数一起赋值吖?
float _Complex fCex = 1.0f + 1.0if; //实数 虚数 一起赋值
因为i代表虚数所以后面的1.0if就是虚数部分,前面的1.0f就是实数部分了
计算:
float _Complex fCex = 0.0f;
fCex = fCex + 2.0f * 5.0f + 2.0if * 5.0f;
2.0f * 5.0f为实部,2.0if * 5.0f为虚部
看完上面是不是觉得会很容易漏写了i
为此我们可以自己定义一个i或者使用complex.h
定义一个宏表示虚数i:
float _Complex fCex = 1.0f + 1.0f * CUSTOM_IMAGINARY;
complex.h
在complex.h中已经为我们定义了一个宏I,定义如下:
#define I _Complex_I
#define _Complex_I (0.0F + 1.0iF)</span>
而且还定义了一个complex的宏,代替_Complex,定义如下:
#ifndef __cplusplus
#define complex _Complex
#endif</span>
PS:如果已经定义了complex相关的结构体关键字,枚举类型,或者typedef定义的自定义名称,再包含complex.h就会出现的错误,所以使用complex.h之前要注意项目是否已经定义了complex的类型!!!
如何获取_Complex的实部和虚部?
在complex.h已经为我们提供了获取实部和虚部的函数:
实部的获取:
float _Complex crealf(float _Complex) 获取float _Complex的实部
double_Complex creal(double _Complex) 获取double _Complex的实部
long double _Complex creall(long double _Complex) 获取long double _Complex的实部
虚部的获取:
float _Complex cimagf(float _Complex) 获取float _Complex的虚部
double_Complex cimag(double _Complex) 获取double _Complex的虚部
long double _Complex cimagl(long double _Complex) 获取long double _Complex的虚部
PS:当然了complex.h中还提供了许多函数,比如csqrtf(计算平方根),ccosf(复数的余弦值)…等等
为什么没有讲_Imaginary?
因为复数_Complex中已经包含了_Imaginary了,而且很少编译器提供了这个_Imaginary(虚数类型)关键字,所以就没有讲啦~
四、关于_Bool(布尔值类型)和_Complex(复数类型)、_Imaginary(虚数类型)的命名
因为标委会考虑到,如果使用新的关键字,会导致以该关键字作为标识符的现有代码全部失效,比如定义了一个struct complex{…};的结构体,那样会让complex成为关键字会导致之前的这些代码出现语法错误。但是使用struct Complex的人很少,特别是标准使用首字母是下划线的标识符作为预留字以后。因此委员会选定Complex作为关键字,在不考虑名称冲突的情况下可以选择complex作为关键字,通过包含complex.h里面定义了complex的宏代替_Complex。
所以Bool和Complex、Imaginary关键字名称不同之前的关键字所字母为下划线开头就是为了避免在C99之前已经定义了complex的发生冲突。
C99标准支持复数和虚数的类型,但是有所保留。一些独立实现(如嵌入式处理器的实现)就不需要复数选项,所以这个数据类型是可选项。
C有三种复数类型:float_Complex、double_Complex、long double_Complex。例如,float_Complex类型的变量应包含两个float类型的值,分别表示复数的实部和虚部。类似的,C语言的三种虚数类型float_Imaginary、double_Imaginary、long double_Imaginary。
如果包含complex.h头文件,就可以用complex代替_Complex,,用imaginary代替_Imaginary。还可以用I(i的大写)来代替-1的平方根。
为什么不直接使用complex也是因为C中包含了某些关键字会引起冲突。
八、单行注释,使用`//
正式引入单行注释符号“//”
九、新增了函数库
<complex.h> 支持复数算法
<fenv.h> 给出对浮点状态标记和浮点环境的其他方面的访问
<inttypes.h> 定义标准的、可移植的整型类型集合。也支持处理最大宽度整数的函数(常见)
<iso646.h> 首先在此1995年第一次修订时引进,用于定义对应各种运算符的宏
<stdbool.h> 支持布尔数据类型类型。定义宏bool,以便兼容于C++
<stdint.h> 定义标准的、可移植的整型类型集合。该文件包含在<inttypes.h>中(常见)
<tgmath.h> 定义一般类型的浮点宏
<wchar.h> 首先在1995年第一次修订时引进,用于支持多字节和宽字节函数
<wctype.h> 首先在1995年第一次修订时引进,用于支持多字节和宽字节分类函数
十.__func__预定义标识符
C99 标准提供一个名为__func__的预定义标识符,它展开为一个代表
函数名的字符串(该函数包含该标识符)。那么,__func__ 必须具有函数
作用域,而从本质上看宏具有文件作用域。因此,__func__是C语言的预定
义标识符,而不是预定义宏。
下面程序中使用了一些预定义宏和预定义标识符。注意,其中一
些是C99 新增的,所以不支持C99的编译器可能无法识别它们。如果使用
GCC,必须设置-std=c99或-std=c11。
// predef.c -- 预定义宏和预定义标识符
#include <stdio.h>
void why_me();
int main(){
printf("The file is %s.\n", __FILE__);
printf("The date is %s.\n", __DATE__);
printf("The time is %s.\n", __TIME__);
printf("The version is %ld.\n", __STDC_VERSION__);
printf("This is line %d.\n", __LINE__);
printf("This function is %s\n", __func__);
why_me();
return 0;
}
void why_me(){
printf("This function is %s\n", __func__);
printf("This is line %d.\n", __LINE__);
}
输出
The file is predef.c.
The date is Sep 23 2013.
The time is 22:01:09.
The version is 201112.
This is line 11.
This function is main
This function is why_me
This is line 21.
二、#line和#error
#line指令重置_ _LINE_ _和_ _FILE_ _宏报告的行号和文件名。可以这
样使用#line:
#line 1000 // 把当前行号重置为1000
#line 10 "cool.c" // 把行号重置为10,把文件名重置为cool.c
#error 指令让预处理器发出一条错误消息,该消息包含指令中的文本。
如果可能的话,编译过程应该中断。可以这样使用#error指令:
#if _ _STDC_VERSION_ _ != 201112L
#error Not C11
#endif
编译以上代码生成后,输出如下:
$ gcc newish.c
newish.c:14:2: error: #error Not C11
$ gcc -std=c11 newish.c
$
三、#pragma
在现在的编译器中,可以通过命令行参数或IDE菜单修改编译器的一些
设置。#pragma把编译器指令放入源代码中。例如,在开发C99时,标准被
称为C9X,可以使用下面的编译指示(pragma)让编译器支持C9X****
#pragma c9x on
一般而言,编译器都有自己的编译指示集。例如,编译指示可能用于控
制分配给自动变量的内存量,或者设置错误检查的严格程度,或者启用非标
准语言特性等。C99 标准提供了 3 个标准编译指示。
C99还提供_Pragma预处理器运算符,该运算符把字符串转换成普通的
编译指示。例如:
_Pragma("nonstandardtreatmenttypeB on")
等价于下面的指令:****
#pragma nonstandardtreatmenttypeB on
由于该运算符不使用#符号,所以可以把它作为宏展开的一部分:
#define PRAGMA(X) _Pragma(#X)
#define LIMRG(X) PRAGMA(STDC CX_LIMITED_RANGE X)
然后,可以使用类似下面的代码:
LIMRG ( ON )
顺带一提,下面的定义看上去没问题,但实际上无法正常运行:
#define LIMRG(X) _Pragma(STDC CX_LIMITED_RANGE #X)
问题在于这行代码依赖字符串的串联功能,而预处理过程完成之后才会
串联字符串。
_Pragma 运算符完成“解字符串”(destringizing)的工作,即把字符串中
的转义序列转换成它所代表的字符。因此
_Pragma("use_bool \"true \"false")
变成了
#pragma use_bool "true "false
四、泛型选择(C11)
在程序设计中,泛型编程(generic programming)指那些没有特定类
型,但是一旦指定一种类型,就可以转换成指定类型的代码。例如,C++在
模板中可以创建泛型算法,然后编译器根据指定的类型自动使用实例化代
码。
C没有这种功能。然而,C11新增了一种表达式,叫作泛型选择表达式
(generic selection expression),可根据表达式的类型(即表达式的类型是
int、double 还是其他类型)选择一个值。泛型选择表达式不是预处理器指
令,但是在一些泛型编程中它常用作#define宏定义的一部分。
下面是一个泛型选择表达式的示例:
_Generic(x, int: 0, float: 1, double: 2, default: 3)
_Generic是C11的关键字。_Generic后面的圆括号中包含多个用逗号分隔
的项。第1个项是一个表达式,后面的每个项都由一个类型、一个冒号和一
个值组成,如float: 1。第1个项的类型匹配哪个标签,整个表达式的值是该
标签后面的值。例如,假设上面表达式中x是int类型的变量,x的类型匹配
int:标签,那么整个表达式的值就是0。如果没有与类型匹配的标签,表达式
的值就是default:标签后面的值。泛型选择语句与 switch 语句类似,只是前
者用表达式的类型匹配标签,而后者用表达式的值匹配标签。
下面是一个把泛型选择语句和宏定义组合的例子:
#define MYTYPE(X) _Generic((X),\
int: "int",\
float : "float",\
double: "double",\
default: "other"\
)
宏必须定义为一条逻辑行,但是可以用 \ 把一条逻辑行分隔成多条物理
行。
在这种情况下,对泛型选择表达式求值得字符串。例如,对
MYTYPE(5)求值得"int",因为值5的类型与int:标签匹配。
下面程序演示了这种用法:
mytype.c程序
// mytype.c
#include <stdio.h>
#define MYTYPE(X) _Generic((X),\
int: "int",\
float : "float",\
double: "double",\
default: "other"\
)
int main(void)
{
int d = 5;
printf("%s\n", MYTYPE(d)); // d 是int类型
printf("%s\n", MYTYPE(2.0*d)); // 2.0 * d 是double类型
printf("%s\n", MYTYPE(3L)); // 3L是long类型
printf("%s\n", MYTYPE(&d)); // &d 的类型是 int *
return 0;
}
下面是该程序的输出:
int
double
other
other
MYTYPE()最后两个示例所用的类型与标签不匹配,所以打印默认的字
符串。可以使用更多类型标签来扩展宏的能力,但是该程序主要是为了演示
_Generic的基本工作原理。
对一个泛型选择表达式求值时,程序不会先对第一个项求值,它只确定
类型。只有匹配标签的类型后才会对表达式求值。
可以像使用独立类型(“泛型”)函数那样使用_Generic 定义宏。
十一、其它部分特性的改动
放宽的转换限制
限制 C89标准 C99标准
数据块的嵌套层数 15 127
条件语句的嵌套层数 8 63
内部标识符中的有效字符个数 31 63
外部标识符中的有效字符个数 6 31
结构或联合中的成员个数 127 1023
函数调用中的参数个数 31 127
不再支持隐含式的int规则
删除了隐含式函数声明
对返回值的约束
C99中,非空类型函数必须使用带返回值的return语句.
扩展的整数类型
扩展类型 含义
int16_t 整数长度为精确16位
int_least16_t 整数长度为至少16位
int_fast32_t 最稳固的整数类型,其长度为至少32位
intmax_t 最大整数类型
uintmax_t 最大无符号整数类型
对整数类型提升规则的改进
C89中,表达式中类型为char,short int或int的值可以提升为int或unsigned int类型.
C99中,每种整数类型都有一个级别.例如:long long int 的级别高于int, int的级别高于char等.在表达式中,其级别低于int或unsigned int的任何整数类型均可被替换成int或unsigned int类型.
新增的内部宏
__STDC_HOSTED 若操作系统存在,则为1
__STDC_VERSION 199991L或更高。代表C的版本
__STDC_IEC_599 若支持IEC 60559浮点运算,则为1
__STDC_IEC_599_COMPLEX 若支持IEC 60599复数运算,则为1
__STDC_ISO_10646 由编译程序支持,用于说明ISO/IEC 10646标准的年和月格式:yyymmmL
十二.for循环的改进
C99标准允许在for循环的头部声明变量,变量的作用域在循环体内。
如:
for(int i=0; i<10; i++){// do someting ...
}
十三、函数的声明与实现可以分离
函数声明与定义的关系 在C语言中,函数声明和函数定义是密切相关的概念。函数声明是指在使用函数之前提供函数的原型,而函数定义是实际实现函数功能的代码块。
函数声明的作用是向编译器提供有关函数的信息,以便编译器在编译时能够正确处理函数的调用。函数声明只需提供函数的返回类型、函数名和参数列表即可,不需要具体的函数实现。
函数定义则包括函数的声明以及函数体的具体实现。函数定义提供了函数的完整描述,包括函数体中的具体代码逻辑。函数定义通常放置在函数声明之后,以便在函数调用时能够找到函数的实现。
下面是一个函数声明与定义的示例:
// 函数声明
int sum(int a, int b);
// 函数定义
int sum(int a, int b) {
return a + b;
}
函数声明与定义的分离可以提高程序的模块化和可维护性。通过将函数声明放置在头文件中,并将函数定义放置在源文件中,可以实现代码的分离和重用。在多个源文件中需要使用某个函数时,只需包含对应的头文件,而无需重复编写函数的定义。
十四.增加了restrict指针
restrict是一个用于限定指针的关键字,一般定义int * restrict a,用来告知编译器,对于该指针指向的内容的修改,只能通过该指针实现,这样做的一个好处是,可以让编译器来更好的优化代码,生成效率更高的汇编代码。gcc编译时需要 加-std=c99 来实现对c99的支持。
通过restrict修饰指针,可以确保两个指针不能指向同样的内存空间。
如memcpy函数在C99标准下的定义为
void *memcpy(void *restrict s1, const void *restrict s2,size_t size);
一、并行优化
对于以下代码:
void add(const float * restrict a, const float * restrict b, float * restrict c)
{
int i;
for(i = 0; i < 6; ++i)
ci]= a[i] + b[i];
}
如果有两个cpu核,则编译器可以优化成[0,2] 和[3,5] 分别处理。
二、简化优化
int func (int* a, int* b)
{
*a = 2;
*b = 3;
return *a;
}
如果在 a 和 b指向内存空间不同时,可以保证返回值一定是2,如果指向的内存空间一致时,返回值为3。虽然,对于一般常规的定义a 和 b不会指向相同的内存空间,但是也会有误操作的可能。那么对于这样一个函数的返回值绝大概率返回值为2,极小概率返回值为3。然而对于编译器来说只有生成100%正确的代码才会进行优化。因此编译器不会替换成下面的更优版本:
int func (int* a, int* b)
{
*a = 2;
*b = 3;
return 2;
}
如果使用restrict这个关键字,就可以利用它来帮助编译器安全的进行代码优化:
int func (int *restrict a, int *restrict b)
{
*a = 2;
*b = 3;
return *a;
}
此刻,由于restrict的效果,指针a 是*a 修改的唯一途径,b不会对a的内容修改,因此可以安全的优化为下列代码:
int func (int *restrict a, int *restrict b)
{
*a = 2;
*b = 3;
return 2;
}
IEC 10646标准的年和月格式:yyymmmL
十二.for循环的改进
C99标准允许在for循环的头部声明变量,变量的作用域在循环体内。
如:
for(int i=0; i<10; i++){// do someting ...
}
十三、函数的声明与实现可以分离
函数声明与定义的关系 在C语言中,函数声明和函数定义是密切相关的概念。函数声明是指在使用函数之前提供函数的原型,而函数定义是实际实现函数功能的代码块。
函数声明的作用是向编译器提供有关函数的信息,以便编译器在编译时能够正确处理函数的调用。函数声明只需提供函数的返回类型、函数名和参数列表即可,不需要具体的函数实现。
函数定义则包括函数的声明以及函数体的具体实现。函数定义提供了函数的完整描述,包括函数体中的具体代码逻辑。函数定义通常放置在函数声明之后,以便在函数调用时能够找到函数的实现。
下面是一个函数声明与定义的示例:
// 函数声明
int sum(int a, int b);
// 函数定义
int sum(int a, int b) {
return a + b;
}
函数声明与定义的分离可以提高程序的模块化和可维护性。通过将函数声明放置在头文件中,并将函数定义放置在源文件中,可以实现代码的分离和重用。在多个源文件中需要使用某个函数时,只需包含对应的头文件,而无需重复编写函数的定义。
十四.增加了restrict指针
restrict是一个用于限定指针的关键字,一般定义int * restrict a,用来告知编译器,对于该指针指向的内容的修改,只能通过该指针实现,这样做的一个好处是,可以让编译器来更好的优化代码,生成效率更高的汇编代码。gcc编译时需要 加-std=c99 来实现对c99的支持。
通过restrict修饰指针,可以确保两个指针不能指向同样的内存空间。
如memcpy函数在C99标准下的定义为
void *memcpy(void *restrict s1, const void *restrict s2,size_t size);
一、并行优化
对于以下代码:
void add(const float * restrict a, const float * restrict b, float * restrict c)
{
int i;
for(i = 0; i < 6; ++i)
ci]= a[i] + b[i];
}
如果有两个cpu核,则编译器可以优化成[0,2] 和[3,5] 分别处理。
二、简化优化
int func (int* a, int* b)
{
*a = 2;
*b = 3;
return *a;
}
如果在 a 和 b指向内存空间不同时,可以保证返回值一定是2,如果指向的内存空间一致时,返回值为3。虽然,对于一般常规的定义a 和 b不会指向相同的内存空间,但是也会有误操作的可能。那么对于这样一个函数的返回值绝大概率返回值为2,极小概率返回值为3。然而对于编译器来说只有生成100%正确的代码才会进行优化。因此编译器不会替换成下面的更优版本:
int func (int* a, int* b)
{
*a = 2;
*b = 3;
return 2;
}
如果使用restrict这个关键字,就可以利用它来帮助编译器安全的进行代码优化:
int func (int *restrict a, int *restrict b)
{
*a = 2;
*b = 3;
return *a;
}
此刻,由于restrict的效果,指针a 是*a 修改的唯一途径,b不会对a的内容修改,因此可以安全的优化为下列代码:
int func (int *restrict a, int *restrict b)
{
*a = 2;
*b = 3;
return 2;
}



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











