




一、《LLM-OREF: An Open Relation Extraction Framework Based on Large Language Models》--25'ALC
1. 🔎 背景 (Background)
传统的 RE 方法只能处理预定义好的关系类型。但在现实世界中,新关系层出不穷。OpenRE (开放关系抽取)旨在发现并提取训练阶段未见过的新关系。
2. 💡 动机 (Motivation)
-
现有方法的痛点: 依赖人工标注(Human Annotation)来定义聚类后的关系类型,这限制了实际应用。
-
LLM 的潜力: LLM 具备强大的生成能力,可以直接生成自然语言形式的关系标签,而不仅仅是做分类或聚类。
-
初步发现 (Preliminary Study): 作者发现 LLM 在零样本 (Zero-shot) 下发现新关系的能力很差,但在小样本 (Few-shot) 下(即给几个例子),尤其是如果示例中包含目标关系时,表现会非常好 。
3. 🚧 现有问题 (Existing Problems)
-
无法自动发现新关系: 传统的聚类方法虽然能把相似的句子放一起,但不知道这个聚类代表什么关系(Cluster Alignment Problem)。
-
LLM 的发现能力有限: 虽然 LLM 擅长做已知关系的分类,但让它凭空发现一个它没见过的新关系(Relation Discovery),仍然很有挑战性。
4. 🚀 创新方法 (Innovative Methods)
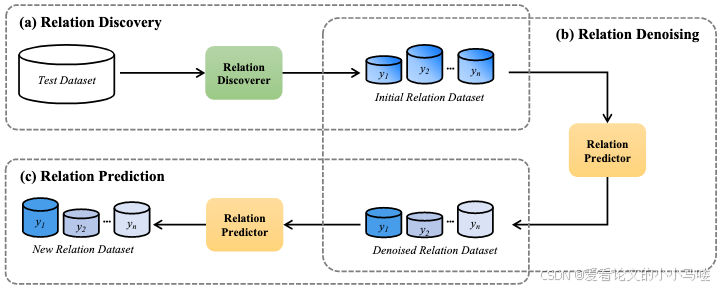
这篇论文提出了 LLM-OREF 框架,核心是利用 LLM 的生成能力,通过**“发现-去噪-预测”**的流程来实现自动化的开放关系抽取。
框架包含两个核心组件:
-
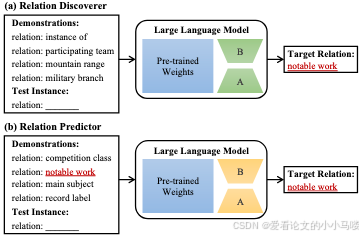
关系发现器 (Relation Discoverer, RD):
-
任务: 在只看过“旧关系”的情况下,去预测测试样本的“新关系”。
-
输入: 包含旧关系实例的 Demonstrations。
-
作用: 这是一个大胆的猜想者,负责提出潜在的新关系候选。
-
-
关系预测器 (Relation Predictor, RP):
-
任务: 给定几个候选关系及其对应的实例,判断测试样本属于哪一个。
-
输入: 包含新关系实例的 Demonstrations。
-
作用: 这是一个严谨的判断者,负责验证和精选。
-
5. ⚙️ 技术细节 (Technology)
1. 自我纠正推理策略 (Self-Correcting Inference Strategy)
阶段一:关系发现 (Relation Discovery)
-
-
使用 RD 对测试集中的每个样本进行初步预测。
-
为了提高召回率,RD 会对每个样本进行多次预测(使用不同的旧关系示例),生成多个候选新标签 。
-
-
阶段二:关系去噪 (Relation Denoising)
-
-
RD 的预测可能有很多噪音(瞎猜的)。
-
利用 RP 进行交叉验证。构建包含 RD 预测出的新标签的 Demonstrations,让 RP 重新判断测试样本是否真的属于这个标签。
-
如果 RP 在多次验证中都一致认为样本属于该标签,则认为这是一个高置信度 (High-Reliability) 的样本 。
-
-
阶段三:关系预测 (Relation Prediction)
-
利用阶段二筛选出的“靠谱样本”作为 Demonstrations,构建高质量的 Prompt。
-
再次使用 RP 对整个测试集进行最终预测。这时 RP 看到了真实的新关系样本,预测准确率会大幅提升 。
-
总结: LLM-OREF 的核心思想是**“用 LLM 验证 LLM”**。它先让模型大胆猜测新关系(RD),然后通过构建验证任务让模型自己去剔除错误的猜测(RP),最终利用筛选出的高质量样本实现精准的新关系预测。
二、《When Phrases Meet Probabilities: Enabling Open Relation Extraction with Cooperating Large Language Models》--24'ALC_[ORELLM]

同样致力于解决**OpenRE(开放关系抽取)**问题,也同样试图摆脱人工标注,但其技术路线与 LLM-OREF 有显著不同。
1. 🔎 背景 (Background)
-
任务: 开放关系抽取 (OpenRE)。即在没有预定义关系标签的情况下,从文本中发现并提取新的关系。
-
主流范式: 现有的 OpenRE 方法通常被建模为**聚类(Clustering)**任务。即先把句子编码成向量(Embedding),然后用 K-Means 等算法把相似的句子聚在一起,每一堆代表一种关系 。
2. 🚧 现有问题 (Existing Problems)
作者指出了“基于 Embedding 聚类”的传统方法存在三个致命缺陷 :
-
度量失效: 预训练模型(如 BERT)的向量空间存在各向异性(Anisotropy),直接用欧氏距离或余弦相似度计算距离并不准确。
-
目标不一致: 预训练任务(如填空)与聚类任务(分类)之间存在 Gap。
-
结果不直观: 聚类只能把句子分组,但无法直接给出**“这到底是什么关系”**的标签(Relational Phrase),这违背了关系抽取的初衷。
3. 💡 动机 (Motivation)
-
LLM 的新视角:
-
LLM 擅长生成文本,可以直接提取**“关系短语”**(例如:生成“father of”而不是仅仅输出一个向量)。
-
LLM 的核心是**“下一个词预测”。这提供了一种新的相似度度量方式:如果给定短语 A,模型生成短语 B 的概率**很高,说明 A 和 B 语义相似 。
-
-
核心思想: 不用向量算距离,而是用生成概率算距离。
4. 🚀 创新方法 (ORELLM Framework)
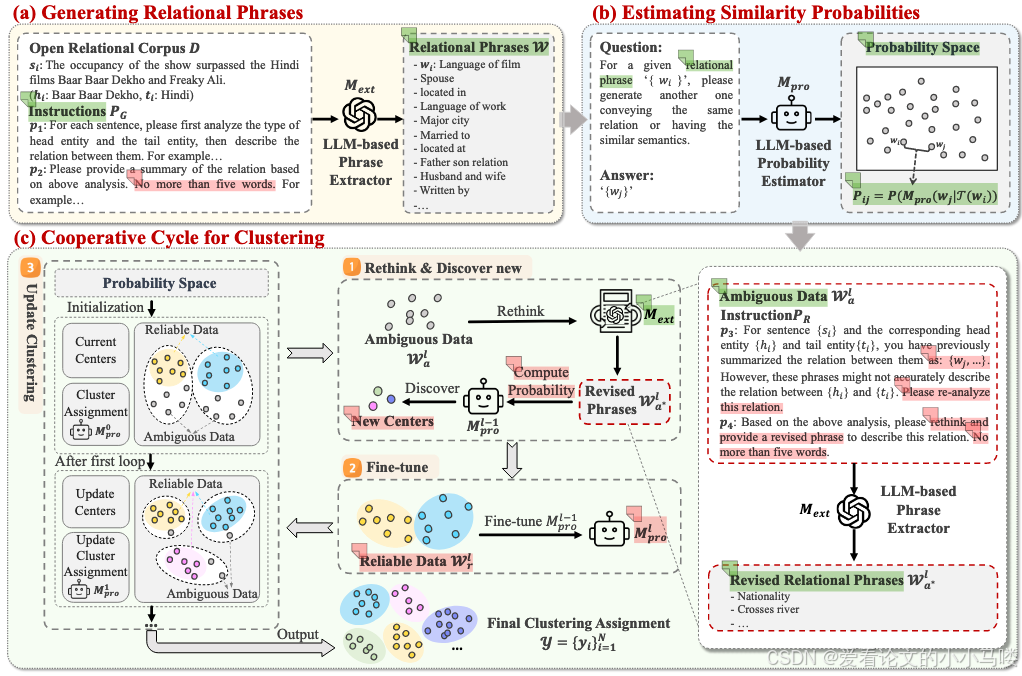
这篇论文提出了 ORELLM 框架,核心是让两个 LLM 分工合作。
角色分工:
-
生成者 (Phrase Extractor, Mext):
-
通常是一个强大的闭源模型(如 ChatGPT)。
-
任务: 读句子,直接提取出描述实体关系的短语(Relational Phrases)。例子: 输入“Steve Jobs founded Apple”,提取出“founder of”。
-
-
估算者 (Probability Estimator, Mpro):
-
通常是一个较小的开源模型(如 GPT-2 XL)。
-
任务: 计算短语之间的语义相似度。
-
原理: 构建一个 Prompt:“给定关系短语 A,请生成一个相似的短语”。然后计算模型生成短语 B 的条件概率 P(B∣A)。这个概率值就直接作为相似度分数
-
协作循环 (Cooperative Cycle):
为了提高效果,这两个模型会进行多轮交互迭代 :
-
初始化:M_ext 提取短语,M_pro 计算相似度矩阵并进行初步聚类。
-
筛选: 根据聚类结果,离中心近的样本为**“可靠数据”,离中心远的样本为“模糊数据”**。
-
反思 (Rethink & Discover):
-
对于模糊数据,让 Mext(ChatGPT)“重新思考”:告诉它之前的提取可能不对,让它根据上下文重新生成一个更好的短语。这有助于发现被遗漏的新关系 。
-
-
微调 (Fine-tune):
-
利用可靠数据,微调 M_pro(GPT-2),让它更能理解该领域的语义相似度,从而在下一轮给出更准的概率分 。
-
5. 📒 总结
面对开放式关系抽取,作者还是选择使用聚类方法,与前人不同在于:本文使用LLM抽取出来的短语作为embedding内容,对于聚类模型通过让LLM生成相似短语进行对比学习。
三、《Actively Supervised Clustering for Open Relation Extraction》--23'ALC_[ASCORE]

1. 🔎 背景 (Background)
-
任务: 开放关系抽取 (OpenRE)。
-
主流范式: 两阶段聚类 (Two-stage Clustering)。
-
第一阶段: 无监督聚类。学习关系表示并进行聚类。
-
第二阶段: 人工标注。给每个聚类簇打标签(命名关系)。
-
-
痛点:
-
无监督太弱: 第一阶段缺乏监督信号,聚类效果差,甚至需要预先知道聚类数量 K(这在开放场景下是不现实的)。
-
标注分离: 聚类和标注是割裂的,标注过程不能反过来优化聚类模型。
-
2. 💡 动机 (Motivation)
-
核心洞察: 聚类学习和关系标注不必是串行的,可以交替进行 (Alternately Performed)。
-
主动学习 (Active Learning): 如果能在聚类过程中,挑选少量最具代表性的样本让此人标注,这些标注信息就能作为**“主动监督信号”**,反过来指导模型更好地聚类,从而发现更多隐藏的关系 。
3. 🚀 创新方法 (ASCORE Framework)
这篇论文提出了 ASCORE (Actively Supervised Clustering for OpenRE) 框架。
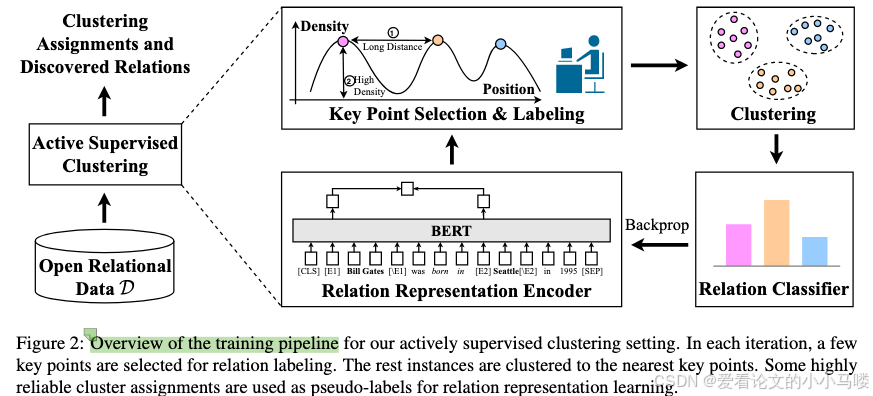
1. 循环迭代流程 (Iterative Loop)
ASCORE 将整个过程变成了一个循环:
-
编码 (Encoding): 使用 BERT 将句子编码为向量,并通过自编码器降维。
-
标注 (Labeling): 使用主动学习策略选出少量“关键点”,人工标注其关系标签。
-
学习 (Learning):
-
将标注数据作为种子,将附近的无标签数据聚类过来,赋予伪标签 (Pseudo-labels)。
-
利用这些伪标签,通过对比损失函数微调 BERT 编码器,让同类样本靠得更近,异类分得更开 。
-
-
重复: 有了更好的编码器,下一轮能选出更具价值的样本进行标注。
2. 关键点选择策略 (Key Point Selection)
为了让标注价值最大化,作者设计了专门针对聚类的选择策略:
-
局部密度最大 (Local Maximum Density): 选出来的点必须是“孩子王”,周围有很多邻居。这样标注它一个,就能把周围一大片都打上伪标签。
-
距离正则化 (Distance Regularization): 选出来的点必须离已知的点足够远。这能鼓励模型去探索未知的领域,发现全新的关系,而不是只在已知关系里打转 。
4. 📒 总结
ASCORE 是目前 OpenRE 领域中 “引入人工介入(Human-in-the-loop)” 的巅峰之作, 卖点是“只需极少人工,换取巨大提升”。
四、《A Relation-Oriented Clustering Method for Open Relation Extraction》--21'EMNLP_[RoCORE]

它代表了**“利用已知关系监督来辅助发现新关系”**这一技术路线的SOTA(State-of-the-Art)。
1. 🔎 背景 (Background)
-
任务: 开放关系抽取 (OpenRE)。
-
主流方法: 基于聚类的无监督关系发现。
-
通常做法是:用 BERT 把句子编码成向量 -> 计算向量距离 -> 用 K-Means 聚类。
-
-
痛点:
-
向量包含杂质: BERT 的向量是高维的,包含了很多与“关系”无关的信息(比如句法结构、形态学特征、特定的实体词)。
-
聚类偏差: 直接对这些向量聚类,往往会把“句式相似”或“实体相似”的句子聚在一起,而不是把“关系语义相似”的句子聚在一起 。
-
2. 💡 动机 (Motivation)
-
核心思想: 既然无监督聚类容易跑偏,为什么不利用**已知的(Pre-defined)**关系数据来教模型“什么是关系”呢?
-
目标: 学习一个**“面向关系的表示空间 (Relation-Oriented Representation)”**。在这个空间里,不管句式怎么变,只要表达的是同一种关系,它们的向量就应该靠得很近。
3. 🚀 创新方法 (RoCORE Framework)
这篇论文提出了 RoCORE 框架,核心是 “有监督的表示学习 + 无监督的聚类” 交替进行。
1. 关系导向的聚类模块 (Relation-Oriented Clustering Module)
为了让向量更适合聚类,作者引入了一个非线性映射 g(⋅),将 BERT 的高维向量映射到一个低维空间,并施加两个约束:
-
中心损失 (Center Loss): 强制让同一类关系的样本,向该关系的质心 (Centroid) 靠拢。这使得簇内更加紧凑 。
-
重构损失 (Reconstruction Loss): 映射后的低维向量必须能还原回原始向量。这是为了防止模型“偷懒”(比如把所有向量都映射为0,虽然距离为0了,但信息全丢了)。
2. 迭代式联合训练 (Iterative Joint Training)
这是模型训练的核心流程 :
-
第一步(初始化): 用 BERT 提取特征。
-
第二步(聚类): 在低维空间对无标签数据进行 K-Means 聚类,生成伪标签 (Pseudo-labels)。
-
第三步(分类器训练):
-
对于有标签数据(已知关系):用真实的标签训练,让模型学会“什么是关系”。
-
对于无标签数据(新关系):利用上一步生成的伪标签,通过成对损失函数 (Pairwise Loss) 进行训练。如果两个样本聚到了同一类,拉近它们的距离;如果不同类,推远它们的距离。
-
-
循环: 有了更好的特征表示,下一轮聚类就会更准;聚类更准,伪标签质量就更高,反过来又能优化特征表示。
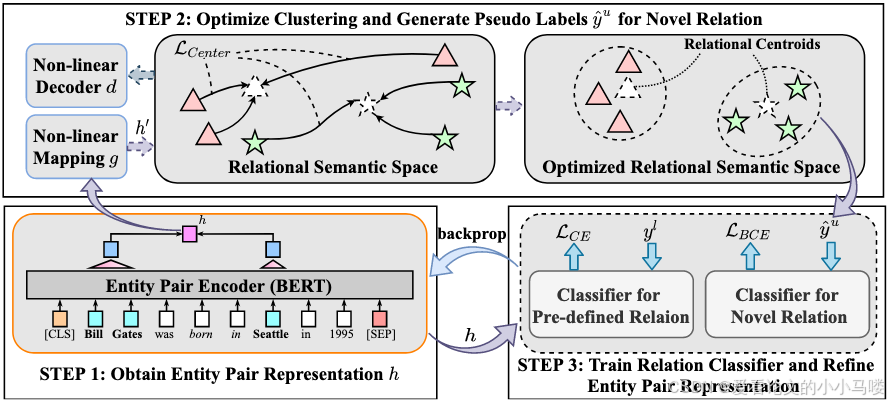
RoCORE简单来说,是使用bert做embedding映射到语义空间,进行聚类,用有标签和聚类得到的伪标签来重新训练bert。随着迭代进行,bert能够得到更好的关系语义空间表示,更好的表示有助于更好的关系分类,成功的分类=成功的关系抽取。
4. 📒 总结
ASCORE是RoCORE的提升版本:RoCORE是直接边聚边训,ASCORE在RoCORE的基础上将已知关系标签换成了选择key point,并通过人工进行标注。
以下是早年小模型的论文几乎没有研究价值
五、《SelfORE: Self-supervised Relational Feature Learning for Open Relation Extraction》--20_[SelfORE]

1. 🚧 现有问题 (Existing Problems)
-
特征质量差: 直接使用 BERT 的 [CLS] 向量或其他通用特征进行聚类,效果并不理想,因为这些特征不是专门为“关系抽取”定制的。
-
聚类硬分配 (Hard Assignment) 的缺陷: 传统的 K-Means 等算法是“硬分配”(非黑即白),容易受到噪声干扰。
-
预知 K 值的限制: 许多方法需要预先知道有多少种关系(K),这在开放域场景下是不现实的
2. 🚀 创新方法 (SelfORE Framework)
这篇论文提出了 SelfORE 框架,核心是一个自监督学习循环 (Self-supervised Learning Loop)。
框架包含三个主要模块 :
-
上下文关系编码器 (Contextualized Relation Encoder):
-
利用 BERT 提取实体对及其上下文的特征向量。
-
-
自适应聚类 (Adaptive Clustering):
-
不对特征进行硬聚类,而是采用软分配 (Soft-assignment)。计算样本属于某个簇的概率分布。
-
利用高置信度的样本来优化聚类中心。
-
-
关系分类 (Relation Classification):
-
将聚类得到的“伪标签”作为监督信号,训练一个分类器。
-
通过分类损失反向传播,微调 BERT 编码器,使其生成的特征更具判别性。
-
六、《Open Relation Extraction: Relational Knowledge Transfer from Supervised Data to Unsupervised Data》--EMNLP'19_[RSN]
它首次提出了**“关系知识迁移”**的概念,即利用已知关系的标注数据来帮助发现新关系。它也是后续许多工作(如 RoCORE, LLM-OREF)的重要对比基线。
1. 💡 动机 (Motivation)
-
核心洞察: 之前的 OpenRE 方法大多是完全无监督的,这就浪费了现有的、高质量的预定义关系数据集(如 TACRED, FewRel)。
-
核心假设: 尽管“新关系”和“旧关系”在语义上不同,但**“判断两个句子是否表达相同关系”**这种能力是可以迁移的。
-
例子: 如果模型学会了判断“A 是 B 的父亲”和“A 的爸爸是 B”是同一种关系,那么它可能也能学会判断“A 是 B 的 CEO”和“A 掌管 B”是同一种关系,即使它从未见过“CEO”这个类别。
-
-
目标: 学习一个通用的关系相似度度量 (Relational Similarity Metric),并在新关系上进行聚类。
2. 🚧 现有问题 (Existing Problems)
-
无监督的局限: 传统的无监督聚类无法有效区分“有意义的关系模式”和“无关的噪声”,因为它们不知道什么是“关系”。
-
特征表达弱: 早期方法依赖手工特征或浅层 Embedding,难以捕捉深层语义。
3. 🚀 创新方法 (Innovative Methods)
这篇论文提出了 RSN (Relational Siamese Networks) 框架。
-
孪生网络结构 (Siamese Network):
-
模型不是去预测“这是什么关系”,而是去预测**“这两句话是否表达了同一种关系”**(二分类问题)。这种设计使得模型可以处理从未见过的关系类型。
-
-
半监督与远程监督扩展:
-
为了利用无标签数据,作者引入了半监督 RSN,通过条件熵最小化和虚拟对抗训练 (VAT) 来利用未标记的新关系数据,进一步优化特征空间 。
-
4. ⚙️ 技术细节 (Technology)
1. 句子编码器 (Sentence Encoder)
-
使用经典的 CNN 结构。
-
输入包含词向量 (Word Embeddings) 和位置向量 (Position Embeddings)。
-
通过卷积和最大池化得到句子的向量表示 v 。
2. 相似度计算 (Similarity Computation)
-
输入两个句子的向量 vl,vr。
-
计算绝对距离:vd=∣vl−vr∣。
-
通过全连接层和 Sigmoid 函数输出相似度概率 p 。
3. 损失函数
-
有监督损失: 交叉熵损失(判断两句话是否同类)。
-
半监督损失(针对无标签数据):
-
条件熵损失 (Conditional Entropy Loss): 惩罚预测概率接近 0.5 的情况,逼迫模型做出确定的判断(靠近 0 或 1)。
-
虚拟对抗损失 (VAT): 给输入加微小的扰动,要求模型的输出保持不变,增强鲁棒性 。
-
4. 聚类算法
-
得到相似度矩阵后,作者对比了 HAC(层次聚类)和 Louvain 算法。
-
发现 Louvain(一种基于图社区发现的算法)效果更好,因为它不需要预先指定聚类数量 K 。
5. 📒 总结
RSN 的核心贡献在于打破了 OpenRE 只能做无监督聚类的思维定势。它证明了通过学习“相似度度量”,可以将已知关系的知识成功迁移到未知关系上。
七、《Unsupervised open relation extraction.》--18_[RW-HAC]
1. 💡 动机 (Motivation)
-
无监督聚类: 作者认为,既然没有标签,那就通过聚类把语义相似的句子放到一起。
-
特征工程: 关键在于如何把句子变成计算机能理解的向量(Vector)。简单的词向量平均(Averaging)效果不好,因为句子中有很多无关词(如 "the", "is")。必须突出核心词的重要性。
2. 🚀 创新方法 (RW-HAC Framework)
这篇论文提出了 RW-HAC 方法,核心是 “重加权词嵌入 + 层次聚类”。
1. 基于依赖句法树的重加权 (Dependency-based Re-weighting)
-
核心思想: 一个句子中,真正决定关系的词,往往位于两个实体之间的最短依赖路径 (Dependency Path) 上。
-
做法:
-
使用 Stanford CoreNLP 解析句法树。
-
如果一个词在两个实体的依赖路径上,给它一个很高的权重(Cin≈1.85)。
-
如果不在路径上,给它一个很低的权重(Cout≈0.02)。
-
结果: 生成的句子向量 s(W,D) 能够聚焦于关系词(如 "born", "hometown"),忽略无关噪声 。
-
2. 稀疏特征降维 (Sparse Feature Reduction)
-
除了词向量,作者还引入了实体类型 (Entity Types)(如 Person, Location)作为特征。
-
这些特征非常稀疏。为了防止它们干扰聚类,作者先对这些稀疏特征单独做 PCA(主成分分析) 降维,然后再与词向量拼接 。
3. 层次聚类 (HAC)
-
使用 HAC (Hierarchical Agglomerative Clustering) 算法对处理后的特征向量进行聚类。
-
相比 K-Means,HAC 在这种特征空间下效果更好 。
5. 📒 总结
RW-HAC 代表了 "Feature Engineering + Clustering" 的技术路线。虽然现在有了 BERT 等强大的预训练模型,但在当年,它通过巧妙利用句法结构来增强语义表示,为 OpenRE 提供了一个非常强有力的无监督基线。
后记
整理一遍ore的相关工作:
18年,最开始RW-HAC在bert技术前使用句法树、主成分分析、层次聚类。
19年,RSN开始使用网络,开始做远程监督、半监督。
20年,SelfORE使用bert,自适应聚类,微调bert编码器,训练分类器。
21年,RoCORE提出要利用已知标签,loss来源于有标签数据、聚类生成的伪标签数据。
23年,ASCORE提出使用技术判断关键关系,对其进行人工标注,标注数据帮助训练编码器,循环标注和聚类。
24年,ORELLM使用LLM根据query生成大量猜测的关系短语,用其作为query的关系embedding,训练聚类器、表征模型。
25年,LLM-OREF摆脱分类范式,直接使用LLM推理关系答案,为了提高LLM准确率,设置关系发现器、关系预测器,放答案关系对应的demonstration,转ZS为FS。

















 3704
3704

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









