







 本文介绍如何搭建Hadoop2.5.1的HA高可用集群,包括配置JournalNode同步元数据信息、ResourceManager高可用以及Zookeeper集群等关键步骤。
本文介绍如何搭建Hadoop2.5.1的HA高可用集群,包括配置JournalNode同步元数据信息、ResourceManager高可用以及Zookeeper集群等关键步骤。
1.在hadoop2.0中通常由两个NameNode组成,一个处于active状态,另一个处于standby状态。Active NameNode对外提供服务,而Standby NameNode则不对外提供服务,仅同步active namenode的状态,
以便能够在它失败时快速进行切换。hadoop2.0官方提供了两种HDFS HA的解决方案,一种是NFS,另一种是QJM。这里我们使用简单的QJM。在该方案中,主备NameNode之间通过一组JournalNode同步元数据
信息,一条数据只要成功写入多数JournalNode即认为写入成功。通常配置奇数个JournalNode这里还配置了一个zookeeper集群,用于ZKFC(DFSZKFailoverController)故障转移,当Active NameNode挂掉了,会自动切换
Standby NameNode为standby状态
2.hadoop-2.2.0中依然存在一个问题,就是ResourceManager只有一个,存在单点故障,hadoop2.5.1开启RM高用后可以解决这个问题,有两个ResourceManager,一个是Active,一个是Standby,状态由zookeeper进行协调
1.准备环境,四台虚拟机
192.168.135.129
192.168.135.130
192.168.135.131
192.168.135.132
2.配置hosts
在/etc/hosts下配置端口映射
192.168.135.129 node1
192.168.135.130 node2
192.168.135.131 node3
192.168.135.132 node4
注意:端口映射可不配置,而直接填写ip地址,但需要在hdfs-site.xml文件中添加如下配置
<property>
<name>dfs.namenode.datanode.registration.ip-hostname-check</name>
<value>false</value>
</property>3.安装jdk1.7.0_79
4.建立hadoop运行账号hello(四台机器一样)
5.使用hadoop用户操作:ssh远程免密码登陆
6.在node1,node2,node4上安装zookeeper(详细安装步骤略)
7.安装配置hadoop集群(在node1上操作)
注意:详细配置可查看官网,这里不详述
7.1下载并解压hadoop安装包tar -zxvf hadoop-2.5.1-x64.tar.gz
7.2修改配置文件(hadoop2.0所有的配置文件都在$HADOOP_HOME/etc/hadoop目录下)
#将hadoop添加到环境变量中
vim /etc/profile
export HADOOP_HOME=/home/hello/app/hadoop-2.5.1
export PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin
7.2.1修改core-site.xml
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<!--
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License. See accompanying LICENSE file.
-->
<!-- Put site-specific property overrides in this file. -->
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://Aro</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>file:/root/hadoop-2.9.1/tmp</value>
<description>Abase for other temporary directories.</description>
</property>
<property>
<name>ha.zookeeper.quorum</name>
<value>node1:2181,node2:2181,node4:2181</value>
</property>
</configuration>
7.2.2修改hdfs-site.xml
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<!--
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License. See accompanying LICENSE file.
-->
<!-- Put site-specific property overrides in this file. -->
<configuration>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/root/hadoop-2.9.1/tmp/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/root/hadoop-2.9.1/tmp/dfs/data</value>
</property>
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<property>
<name>dfs.nameservices</name>
<value>Aro</value>
</property>
<property>
<name>dfs.ha.namenodes.Aro</name>
<value>nn1,nn2</value>
</property>
<property>
<name>dfs.namenode.rpc-address.Aro.nn1</name>
<value>node1:8020</value>
</property>
<property>
<name>dfs.namenode.rpc-address.Aro.nn2</name>
<value>node4:8020</value>
</property>
<property>
<name>dfs.namenode.http-address.Aro.nn1</name>
<value>node1:50070</value>
</property>
<property>
<name>dfs.namenode.http-address.Aro.nn2</name>
<value>node4:50070</value>
</property>
<property>
<name>dfs.namenode.shared.edits.dir</name>
<value>qjournal://node1:8485;node2:8485;node4:8485/Aro</value>
</property>
<property>
<name>dfs.client.failover.proxy.provider.Aro</name>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value>
</property>
<property>
<name>dfs.ha.fencing.methods</name>
<value>sshfence</value>
</property>
<property>
<name>dfs.ha.fencing.ssh.private-key-files</name>
<value>/root/.ssh/id_rsa</value>
</property>
<property>
<name>dfs.journalnode.edits.dir</name>
<value>/root/hadoop-2.9.1/journalnode/data</value>
</property>
<property>
<name>dfs.ha.automatic-failover.enabled</name>
<value>true</value>
</property>
</configuration>7.2.3修改slaves
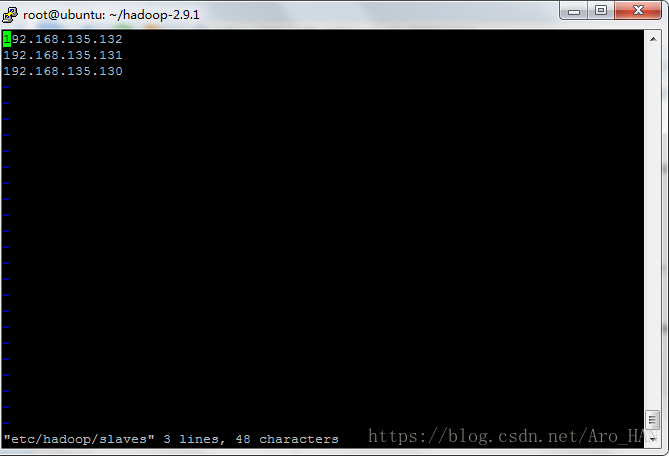
###注意:严格按照下面的步骤
8.启动集群
8.1启动zookeeper集群(分别在node1、node2、node4上启动zk)
cd /home/hello/app/zookeeper-3.4.7
./bin/zkServer.sh start
#查看状态:一个leader,两个follower
./bin/zkServer.sh status
8.2启动journalnode(分别在在node1、node2、node4上执行)
cd /weekend/hadoop-2.5.1
./sbin/hadoop-daemon.sh start journalnode
#运行/usr/java/jdk1.7.0_79/bin/jps命令检验,node2、node3、node4上多了JournalNode进程
8.3格式化HDFS
#在node1上执行命令:
./bin/hdfs namenode -format
#格式化后会在根据core-site.xml中的hadoop.tmp.dir配置生成个文件,这里我配置的是/home/hello/app/hadoop-2.5.1/tmp,
#然后将/home/hello/app/hadoop-2.5.1/tmp拷贝到node2的/home/hello/app/hadoop-2.5.1/下。
scp -r ./tmp/ hello@node2:/home/hello/app/hadoop-2.5.1/
##也可以这样,建议hdfs namenode -bootstrapStandby
8.4格式化ZKFC(在node1上执行即可)
./bin/hdfs zkfc -formatZK
8.5启动HDFS(在node1上执行)
./sbin/start-dfs.sh
测试集群工作状态的一些指令:
./bin/hdfs dfsadmin -report 查看hdfs的各节点状态信息
./bin/hdfs haadmin -getServiceState nn1 查看namenode高可用
./bin/yarn rmadmin –getServiceState rm1 查看ResourceManager高可用
./sbin/hadoop-daemon.sh start namenode 单独启动一个namenode进程
./hadoop-daemon.sh start zkfc 单独启动一个zkfc进程
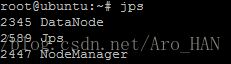
结果为:
nn1&&zk
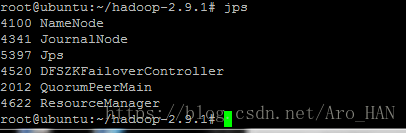
nn2&&dn4&&zk
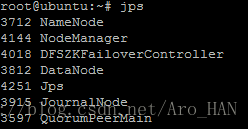
dn2&&zk
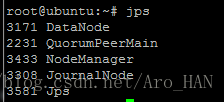
dn3

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









